Command Palette
Search for a command to run...
在随机森林中使用无穷小刀切法估计渐近方差的重抽样与递归划分方法比较
在随机森林中使用无穷小刀切法估计渐近方差的重抽样与递归划分方法比较
Cole Brokamp MB Rao Patrick Ryan Roman Jandarov
随机森林应用于 LendingClub 数据集
摘要
无穷小刀切法(IJ)最近被应用于随机森林以估计其预测方差。这些理论是在使用分类与回归树(CART)和自助法重抽样的传统随机森林框架下验证的。然而,研究发现,使用条件推断(CI)树和子采样(subsample)的随机森林不易受到变量选择偏差的影响。在此,我们通过一种新颖的方法进行模拟实验,以探索IJ在采用不同重抽样方法和基学习器变体的随机森林中的适用性。我们模拟了测试数据点,并在100个模拟训练数据集上分别使用不同的重抽样方法与基学习器组合对每个数据点进行随机森林训练。结果表明,在使用IJ时,用CI树替代传统的CART树,以及用子采样替代自助法采样,能够显著提高预测方差估计的准确性。上述随机森林变体已整合到R编程语言的开源软件包中。
一句话总结
模拟实验表明,将无限小刀切法应用于结合条件推断树和子采样的随机森林中,能够产生比传统 CART 和自助法方法更准确的预测方差估计,且这些方法学改进现已集成至一个开源 R 包中。
核心贡献
- 本研究建立了一个模拟框架,用于评估在随机森林中采用条件推断树替代传统 CART 树、以及采用子采样替代自助法重采样时,无限小切法在预测方差估计中的表现。
- 涵盖一百个模拟训练数据集的实验表明,将条件推断树与子采样相结合,相比标准随机森林配置,能够生成精度高得多的无限小切法方差估计值。
- 经评估的算法变体已实现于一个开源 R 包中,以促进改进版方差估计技术的实际部署。
引言
随机森林广泛应用于预测建模,但准确量化预测不确定性对于可靠的机器学习推断仍然至关重要。尽管早期研究已证实无限小切法可用于估计标准随机森林的预测方差,但其与现代算法变体的配合性能尚未得到严格验证。作者利用模拟实验,评估了无限小切法与子采样等替代重采样策略,以及条件推断树等不同构树算法结合时的表现。该分析通过确定这些广泛采用的修改是否能够保持准确的量化不确定性,填补了关键的方法学空白。
数据集
- 数据集构成与来源: 作者使用数学模拟函数生成完全合成的数据,而非导入外部记录。该数据集包含十个从正态分布中采样的预测变量,以及通过预定义模拟规则生成的十一种独立合成结果。
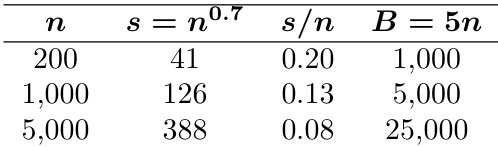
- 子集详情: 数据被组织为三十三种唯一的数据集类型,由十一种模拟函数与三种训练样本量(n=200, 1000, and 5000)组合而成。预测变量 X1 至 X5 遵循标准正态分布(均值为 0,方差为 1),而 X6 至 X10 则从均值为 10、方差为 5 的正态分布中抽取,以引入更宽的值域。每个模拟函数使用特定子集的预测变量,该信息通过数据集名称中的数字体现,尽管在模型训练期间会向随机森林模型输入全部十个变量。
- 数据使用与处理: 作者将生成的数据划分为不同大小的训练集与固定的评估集。针对每个模拟函数,生成一百个独立测试点以评估预测精度。训练集在三种指定样本量下被反复采样,以评估模型在不同数据量条件下的性能。
- 其他处理细节: 合成结果通过预测变量的逻辑与算术运算构建。逻辑组合使用指示函数表示与(AND)和或(OR)条件,而算术组合则应用求和(SUM)与平方和(SQ)变换。数据集名称中嵌入的数字反映了参与该特定模拟函数的预测变量数量,且由于整个流程完全依赖受控的数学生成,未应用任何外部过滤或裁剪操作。
方法
作者利用一个将随机森林预测与方差估计技术相结合的框架来评估预测不确定性。整体流程始于一个分布,从中生成一百个测试集。每个测试集用于生成一百个预测值与一百个方差预测值,构成后续分析的基础。该框架计算这一百个预测值的经验方差,作为预测函数方差的估计值。随后,该方差与预测值的绝对偏差结合,生成一百个绝对偏差估计值。对所有一百个估计值求平均,即得到经验预测偏差。
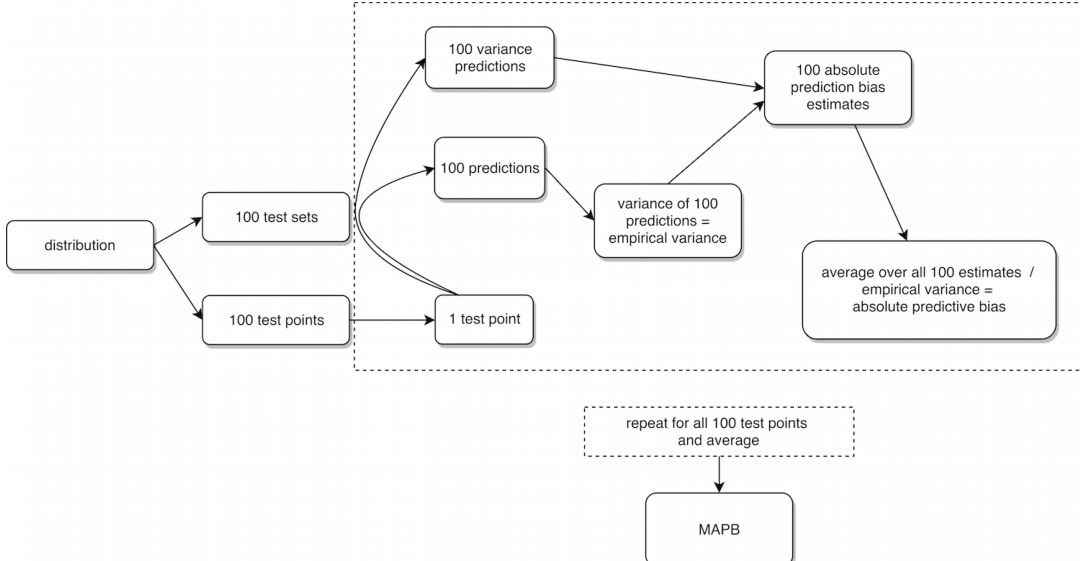
该过程对所有一百个测试点重复执行,并将结果取平均以生成最终指标,称为 MAPB。该迭代过程确保框架能够捕捉整个测试集上的变异性与偏差,从而提供对预测性能的综合评估。该框架强调了方差与偏差在评估预测可靠性方面的重要性,尤其是在随机森林等集成方法的背景下。
实验
本研究通过系统性地改变树类型、重采样方法、特征选择参数、样本量及底层数据分布的模拟实验,评估了随机森林预测方差估计的准确性。这些实验变体验证了方差估计器的鲁棒性,结果表明:与传统 CART 模型相比,条件推断树能持续降低偏差;而子采样通过增强树之间的去相关性,其表现显著优于自助法采样。最终,研究结果证实,将条件推断树与子采样相结合能在多种条件下提供最可靠的方差估计,这不仅验证了理论证明,也凸显了自助法重采样在复杂场景下的性能局限。
作者进行了模拟实验,以评估不同配置(包括树类型、重采样方法和样本量)下随机森林方差估计的平均绝对预测偏差(MAPB)。结果表明,在降低偏差方面,子采样始终优于自助法采样;且在所有条件下,条件推断树通常比传统 CART 树产生更低的偏差。在所有条件下,子采样的平均绝对预测偏差均低于自助法采样。无论其他模拟因素如何,条件推断树产生的偏差始终低于传统 CART 树。样本量对偏差的影响因数据分布而异,部分分布在大样本量下表现出偏差增加的趋势。
作者比较了使用不同树类型、重采样方法和样本量的随机森林变体性能,重点关注平均绝对预测偏差作为方差估计准确性的度量。结果表明,与传统 CART 树和自助法采样相比,条件推断树和子采样能持续降低偏差,其中重采样方法对性能的影响最为显著。在所有分布和样本量下,条件推断树在降低预测偏差方面始终优于传统 CART 树。子采样导致的偏差低于自助法采样,且最优的子采样表现甚至超越了最差的自助法表现。增加树分裂所用变量数量对自助法采样的影响比对子采样更为明显,尤其对某些数据分布而言。
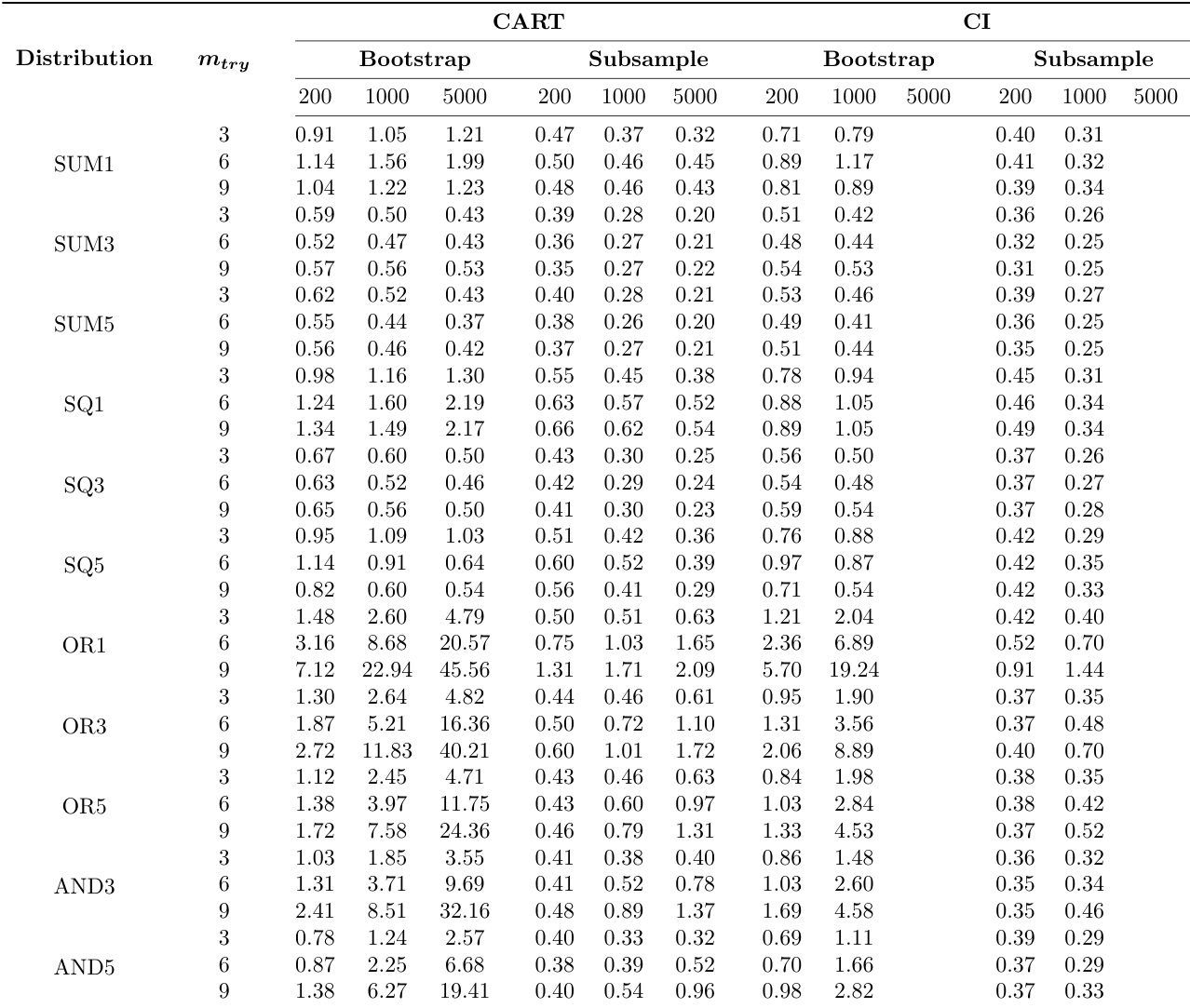
作者进行了模拟实验,以评估采用不同树类型、重采样方法和参数设置时随机森林方差估计的平均绝对预测偏差。结果表明,条件推断树始终优于传统 CART 树,且子采样在所有条件下均能带来显著低于自助法重采样的偏差。无论重采样方法或样本量如何,条件推断树均能持续降低偏差。子采样产生的偏差大幅低于自助法重采样,且最优的子采样表现优于所有情况下的最优自助法表现。在模拟函数中增加所用变量数量会导致使用自助法重采样时偏差升高,尤其是在配合条件推断树时更为明显。

作者分析了不同数据分布和样本量下随机森林预测的经验方差,观察到相较于 SUM 和 SQ 分布,OR 和 AND 分布的方差通常较低,且随着样本量增加这一趋势更为明显。结果显示,对于 SUM 和 SQ 分布,经验方差随样本量增大而减小,但对于 OR 和 AND 分布则呈上升趋势,这可能是由于其基线方差较低所致。这些趋势与平均绝对预测偏差中观察到的模式一致。相较于 SUM 和 SQ 分布,OR 和 AND 分布的经验方差始终较低,尤其在较大样本量下。SUM 和 SQ 分布的经验方差随样本量增加而减小,而 OR 和 AND 分布的经验方差则随之增加。涉及更多变量和更宽值域的分布具有更高的中位经验方差,尤其在 SUM5 和 SQ5 中表现明显。
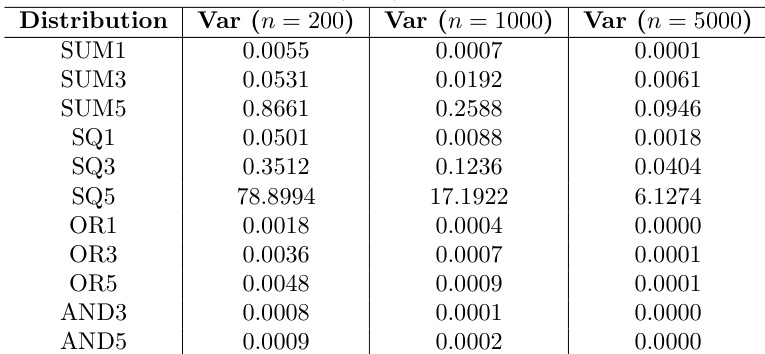
模拟实验通过系统性地改变树架构、重采样策略、样本量及底层数据分布,评估了随机森林的方差估计准确性。结果验证了条件推断树和子采样能持续产生比传统 CART 模型和自助法重采样更低的预测偏差,且重采样方法对性能的影响最为强烈。此外,经验方差的变化轨迹与偏差模式高度吻合,表明分布特征与样本量之间存在交互作用,从而产生差异化的缩放行为,而非统一的性能提升。