Command Palette
Search for a command to run...
K+ 均值:对 K-均值聚类算法的增强
K+ 均值:对 K-均值聚类算法的增强
Srikanta Kolay Kumar S. Ray Abhoy Chand Mondal
K-means 算法
摘要
K-均值(MacQueen,1967)[1] 是解决著名聚类问题的最简单的无监督学习算法之一。该过程采用一种简单直接的方法,将给定的数据集分类为预定义的 K 个簇中。确定 K 值是一项困难的任务,且目前尚不清楚哪个 K 值能够根据我们的直觉对对象进行有效划分。为解决这一问题,我们提出了 K+ 均值算法。该算法是对 K-均值算法的一种增强。
一句话总结
针对传统 K-means 算法难以确定合适聚类数量的问题,作者提出了 K+ Means 算法。这是一种改进的无监督聚类算法,简化了数据划分流程。
核心贡献
- K+ Means 算法通过根据数据特征自动确定最终聚类数量,增强了标准 K-Means 聚类,无需预先指定聚类数。
- 该方法计算最小、最大和平均簇内差异以检测异常值,随后将距离较高的对象提升为新质心,直到聚类代表点和分配结果稳定。
- 与标准 K-Means 的对比评估表明,该方法能将异常点隔离至独立簇中,同时保持 O(tk²n) 的时间复杂度,并消除对异常值位置的敏感性。
引言
未提供源文本。请提供摘要或正文片段,以便撰写简明摘要,概述技术背景及其实际意义,指出现有方法的局限性,并从解释性角度说明作者的主要贡献。
数据集
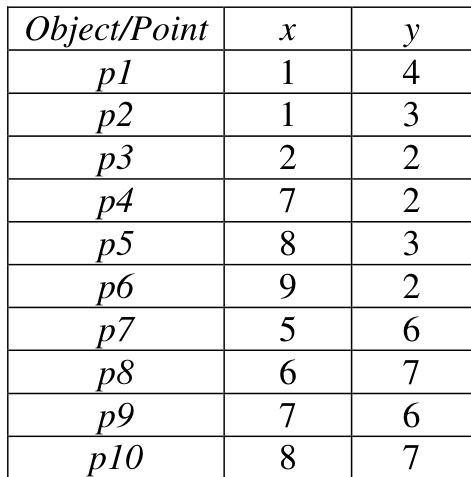
- 数据集构成与来源: 作者依赖一个包含在单个表格中的小型示例数据集来演示该算法。
- 各子集的关键细节: 仅提供了一个示例子集。其中包含的对象数量有限,专为逐步演示而选取,而非用于大规模建模。
- 论文的数据使用方式: 该数据集仅作为实际示例,用于引导读者逐步了解 K+ Means 聚类步骤。摘录内容未提及正式的训练集划分、混合比例或评估协议。
- 处理与可视化细节: 原始表格数据直接映射至二维坐标系以进行可视化演示。未描述任何裁剪、元数据构建或额外的预处理流程。
方法
作者以 K-Means 算法为基础组件开发 K+ Means 算法,以解决原始方法的关键局限性。该框架遵循标准 K-Means 流程,首先初始化 K 个质心并将数据点分配至最近的簇。收敛后,算法计算每个簇的簇内差异指标(最小值、最大值和平均值)。核心改进在于基于这些指标动态识别异常值。具体而言,平均簇内距离较高且通常伴随较大最大距离的簇将被标记以供进一步分析。此类簇中对应最大距离的数据点被识别为异常值,并作为新的聚类代表点。该过程迭代增加一个聚类数量,重新分配数据点并重新计算质心,直到不再形成新的代表点且聚类分配稳定。
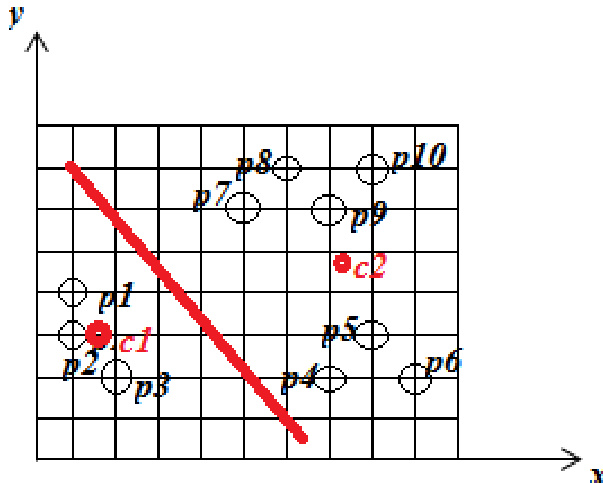
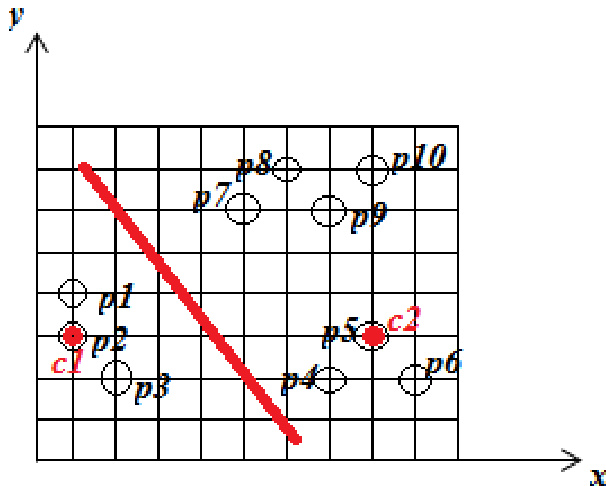
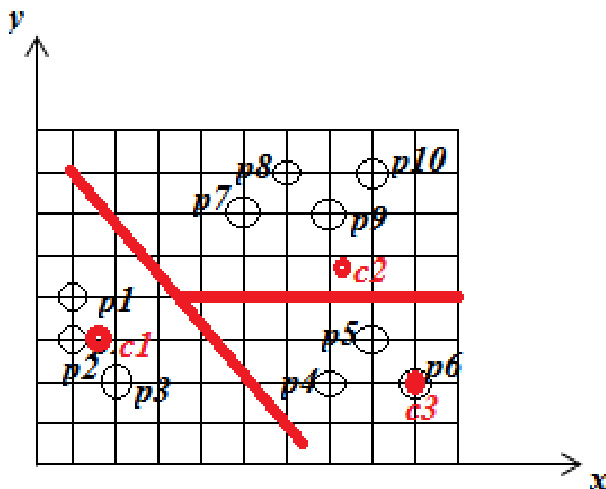
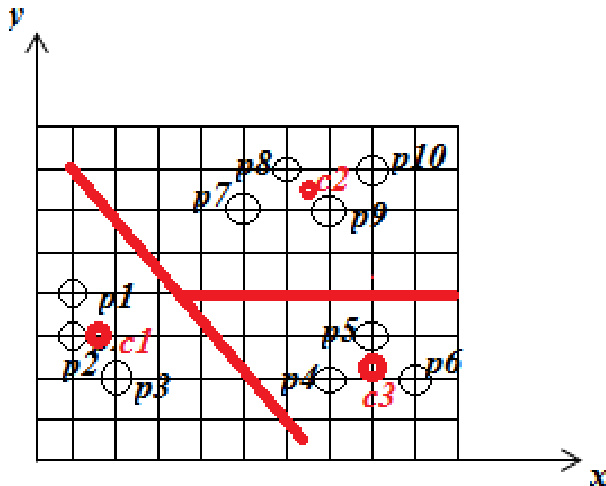
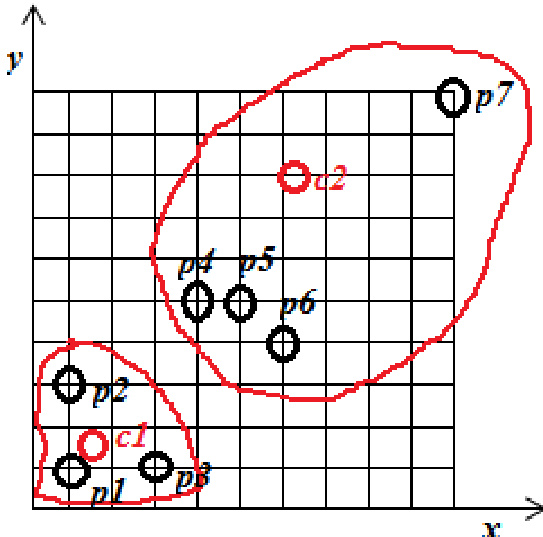
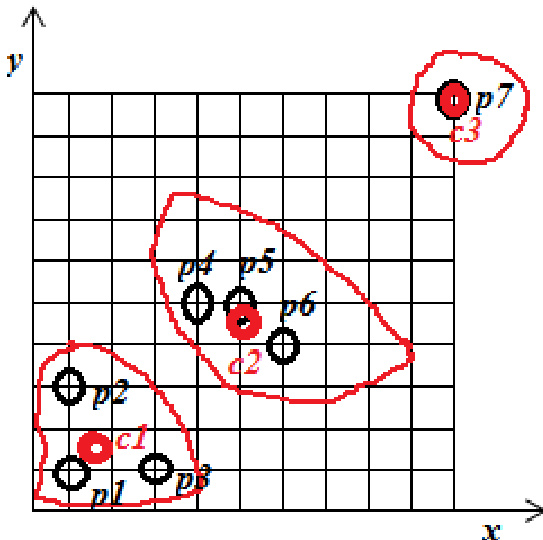
实验
评估在对象数据集上采用双簇配置,对比了标准 K-means 算法与 K+ Means 方法。实验验证了尽管 K-means 基于选定质心建立初始分组,但 K+ Means 算法能提供更准确且稳健的聚类分配,尤其在有效处理异常对象方面表现突出。尽管 K+ Means 方法涉及略高的计算复杂度,但其整体聚类效果始终更优。
作者将初始质心设置在 p1 和 p5 以应用 K-means 算法,生成两个簇,其中一个包含点 p1、p2 和 p3,另一个包含其余点。K-means 与 K+ Means 算法的对比显示,后者在较高复杂度下仍能产生更优的聚类结果,尤其在处理异常对象时。K-means 聚类根据初始质心选择将点划分为两个簇。与 K-means 相比,K+ Means 算法能产生更优的聚类效果,特别是对异常对象。K+ Means 算法的计算复杂度高于 K-means。
评估采用定义好的初始质心,将标准 K-means 聚类与 K+Means 算法进行对比,以将数据划分为不同组别。该设置验证了两种方法在形成连贯簇方面的相对有效性,同时评估了它们对异常数据点的处理能力。研究结果表明,尽管 K+Means 需要更高的计算开销,但其始终能产出更优的聚类质量,尤其在管理异常对象方面。