Command Palette
Search for a command to run...
基于深度学习回答图像问题的教程
基于深度学习回答图像问题的教程
Mateusz Malinowski Mario Fritz
Keras 教程:深度学习入门指南
摘要
随着计算机视觉和自然语言理解中更精确方法的发展,能够针对真实世界图像内容回答问题的一体化架构应运而生。在本教程中,我们构建了一种基于神经网络的图像问答方法。我们的教程主要基于 DAQUAR 数据集,并辅以 VQA 数据集。通过微小的调整,我们所提出的模型在这两个数据集上均能取得具有竞争力的性能;事实上,它们是结合长短期记忆网络(LSTM)与图像全局全帧卷积神经网络(CNN)表示的最佳方法之一。我们希望读者在阅读本教程后,能够使用深度学习框架(如 Keras 以及本文介绍的 Kraino)构建各种架构,从而在这一挑战性任务中进一步提升性能。
一句话总结
Malinowski 和 Fritz 提供了一份关于构建神经视觉问答架构的教程,该架构将长短期记忆网络(LSTM)与全局全帧 CNN 表示相结合,在 DAQUAR 和 VQA 数据集上展现了具有竞争力的性能。同时,教程提供了基于 Keras 和 Kraino 框架的实现指南,以支持进一步的性能优化。
核心贡献
- 本教程介绍了一种用于视觉问答的神经网络架构,该架构将长短期记忆网络与全局全帧卷积神经网络表示相集成。
- 该工作提供了 Kraino,这是一个基于 Keras 的框架,旨在简化视觉问答深度学习架构的实现与训练流程。
- 在 DAQUAR 和 VQA 数据集上的评估表明,所提出的模型取得了具有竞争力的性能,并跻身于利用全局图像表示的主流方法之列。
引言
视觉问答通过使机器能够解读真实世界图像并响应自然语言查询,在计算机视觉与自然语言理解之间架起了桥梁,这一能力对于推动多模态 AI 和直观应用的发展至关重要。然而,先前的方法通常依赖于全局图像表示,这会丢弃细粒度细节,难以处理语义和空间歧义,且依赖僵化的准确率指标,无法捕捉答案正确性的细微差别。作者通过提出一种精简的神经网络架构来解决这些不足,该架构将长短期记忆网络与全帧卷积神经网络特征相结合,在基准数据集上展现了具有竞争力的性能,同时为使用现代深度学习框架实现和扩展这些模型提供了实用指南。
数据集
-
数据集构成与来源: 作者使用了两个视觉问答数据集:DAQUAR(Malinowski and Fritz, 2014),提供基于场景的问答图像三元组;以及 VQA(Antol et al., 2015),一个大规模开放式数据集。两者均提供配对的文本查询、答案及对应的图像标识符。
-
子集细节与过滤规则: DAQUAR 分为训练集和测试集,答案偶尔包含多个以逗号分隔的术语。VQA 训练子集通过单一高频答案模式进行过滤,并限制为最常见的 1000 个问答对;由于测试标签被隐藏,模型评估依赖于公开的验证集。
-
数据处理与训练使用: 通过从训练语料库构建独立的词到索引字典,将原始文本转换为数值格式。问题被填充至固定的 30 tokens 序列长度,答案则截断为首词后再填充至单个时间步。该流程基于 token 索引而非稀疏的 one-hot 向量运行,以避免低效的矩阵乘法,同时特殊 tokens 用于处理序列对齐和词表外词汇。
-
视觉特征提取与元数据对齐: 图像数据通过从预训练卷积网络中提取特征进行处理。作者从 VGG Net 中获取用于 DAQUAR 的倒数第二层(4096 维),并为 VQA 使用指定 CNN 的
pool5-7x7_s1层。文本与视觉模态通过共享的图像文件名进行对齐,最终特征表示应用了固定的 1000 维嵌入维度。
方法
作者利用一个模块化框架构建问答模型,该模型处理文本和视觉输入,整体围绕序列到序列(sequence-to-sequence)范式设计,包含独立的编码与融合组件。整体方法首先从仅文本模型开始,这些模型在无视觉输入的情况下学习回答问题,作为捕捉数据集偏差与常识知识的基线。随后,该框架扩展至联合语言与视觉模型,集成从图像中提取的视觉特征。核心设计依赖于模块化架构,语言流与视觉流分别处理,随后通过可配置的融合操作进行组合。
文本处理流程始于将输入问题编码为词表示序列。首先考虑的模块是词袋(Bag-of-Words, BOW)模型,该模型将问题表示为每个词的稀疏 one-hot 向量,随后使用可学习的嵌入矩阵 We 将其映射至稠密向量空间。嵌入后的词向量相加,生成整个问题的单一固定长度表示。该聚合表示通过全连接层,随后接 softmax 激活函数,以生成可能答案词的概率分布。模型通过最小化交叉熵损失进行训练,该损失衡量预测答案分布与真实答案分布之间的差异。训练过程采用基于梯度的优化算法 Adam,该算法根据梯度的一阶矩和二阶矩为每个参数自适应调整学习率。
为捕捉语言的序列特性,作者引入了循环神经网络(RNN)模块,具体为 LSTM,逐词处理输入问题。如图所示,每个词嵌入 xt 被输入至 LSTM 单元,该单元维护一个隐藏状态 ht,用于累积从序列起始至当前时间步的信息。序列的最终隐藏状态 ht 被用作整个问题的表示。该表示随后通过稠密层和 softmax 进行分类。RNN 架构显式地对词的顺序进行建模,这对于理解词序影响语义的问题至关重要。
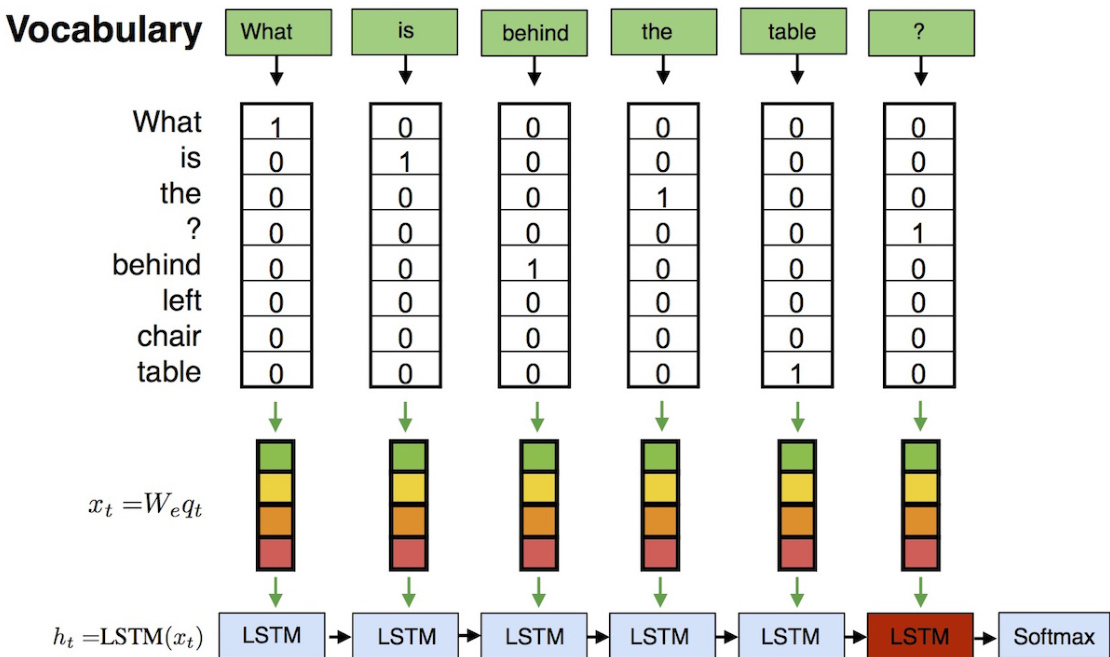
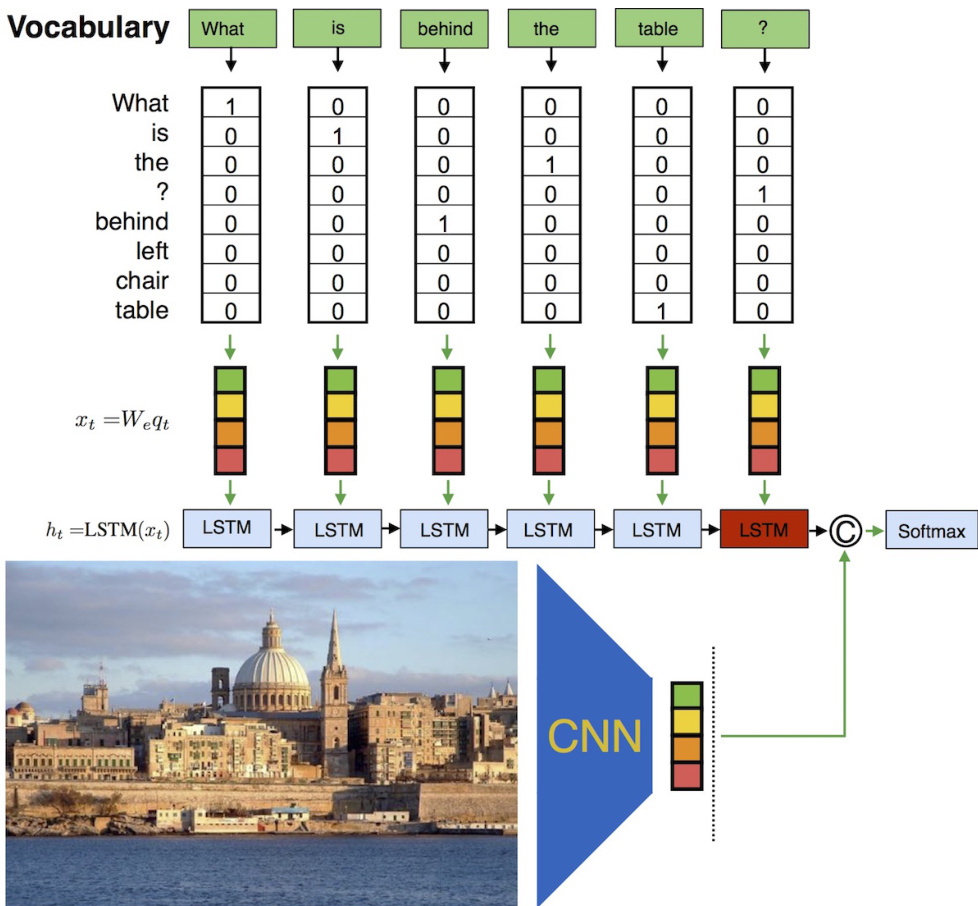
视觉信息的集成由独立的路径处理。卷积神经网络(CNN)用于从输入图像中提取固定维度的特征向量,作为视觉表示。该视觉特征向量通过稠密层处理,以匹配语言表示的维度。随后,语言表示与视觉表示通过多模态融合操作进行组合。该框架支持多种融合策略,包括拼接、逐元素乘法和求和。如图所示,融合后的表示通过 dropout 层和最终分类层以预测答案。模型使用相同的交叉熵损失和 Adam 优化算法进行端到端训练,梯度同时流经语言与视觉路径。
实验
评估框架采用 WUPS 指标,将预测结果与真实标签进行对比,有效处理了词级歧义和基于集合的比较。初始实验验证了仅文本的盲模型,后续测试则引入了 CNN 提取的视觉特征,并与词袋模型及循环神经网络架构相结合。这些多模态实验表明,集成视觉数据能显著提升性能,其中具备序列感知能力的 RNN 在处理图文联合输入时尤为有效。总体而言,该研究强调了模态融合策略与训练配置在实现稳健视觉理解中的关键作用。