Command Palette
Search for a command to run...
语言建模
摘要
一句话总结
通过对词一元组特征和词性分布特征训练支持向量机(SVM)分类器,作者实现了将历史葡萄牙语文学作品年代精确判定到五十年和百年区间的99.8%准确率,特征分析表明信息性词汇与形态句法标记同语言演变密切相关。
核心贡献
- 提出了一种针对历史葡萄牙语文学作品的时序文本分类框架,该框架通过词n-gram建模词汇变异,通过词性分布建模形态句法变异,从而刻画语言演变过程。
- 通过专项分析探究最具信息量的语言特征,并明确将这些模式与历史语言演变过程相联系。
- 证明利用词一元组特征的SVM分类器在预测百年和五十年区间内的出版年代时,准确率达到99.8%。
引言
提供的文本仅包含元数据和致谢部分,缺乏总结所需的研究背景、现有局限及具体贡献。提供摘要或正文后,将为您撰写简明概述,重点突出应用场景、现有挑战及作者的核心贡献。最终输出将严格遵循格式规范,保持技术严谨性同时确保易于理解。
数据集
-
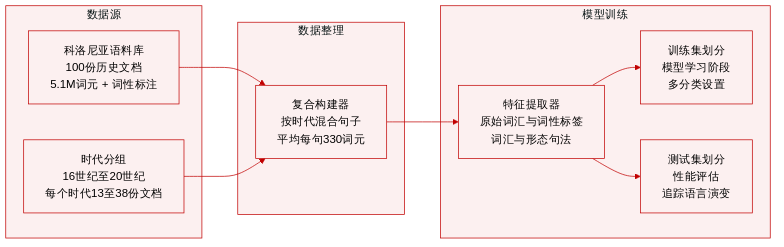
数据集构成与来源: 作者使用Colonia语料库,这是一部涵盖16世纪至20世纪初的历史葡萄牙语文献合集。该语料库包含100部完整小说及文本合集,总量超过510万 tokens,并附带经TreeTagger预处理生成的句子边界及粗粒度词性(POS)标签。
-
子集详情: 文档按历史时期组织,作为分类标签。子集规模存在天然的不平衡性,从16世纪的13篇文档到19世纪的38篇文档不等。
-
数据使用与处理: 为缓解各时期原始文档数量有限的问题并统一输入长度,作者通过随机采样并拼接同一时期的句子来合成复合文档。这些人工文本平均长度约为330 tokens,并被划分为训练集和测试集。该构建方法在各类别内部混合了不同的作者风格与主题,同时强制统一长度以提升分类难度。
-
特征构建与建模: 作者从复合文档中提取原始词汇和POS标签,作为词汇和形态句法特征。这些特征用于训练多类时序文本分类模型,旨在追踪历时语言变异。
方法
作者利用支持向量机(SVM)分类器对历史葡萄牙语文本中的词汇与句法变异进行建模,以实现时序分类。该框架依赖从词汇层面和词性(POS)信息中提取特征,从而识别跨越不同世纪的语言演变模式。特征根据其对SVM模型的贡献进行排序,利用训练过程中分配的权重,可识别最具区分度的语言模式。该方法能够检测语言使用中主题与结构随时间发生的转变。
词一元组被用作主要特征集,用于捕捉不同时期的词汇变化。此外,引入POS n-gram(如POS标签序列)以捕捉句法和语法转变。POS标签的使用有助于识别风格偏好,例如19世纪和20世纪形容词使用频率的增加,这体现在ADJ NOM ADJ和NOM ADJ CONJ等模式中。这些模式对于区分后期时期尤为有效,因为此时的风格选择更为显著。
该框架还引入了命名实体,尽管其对语言演变的指示性较弱,但能显著提升分类准确率。例如,对Dom Afonso和Dom João等历史人物的提及,或Sua Majestade等正式头衔,均作为17世纪文本的时期特定标记。同样,per、asi、mui、mi和despois等古旧形式在16世纪文本中十分突出,其中per因其拉丁语词源及在拉丁语引文中的高频使用而具有极强的区分度。
为应对历史文本数量有限的问题,作者采用数据增强策略,通过生成同一时期文本片段来构造人工训练集和测试集实例。该方法使得模型能够在真实数据稀缺的条件下进行评估,从而提升泛化能力与鲁棒性。
实验
评估采用按出版时期标注的历史葡萄牙语语料库,利用词汇n-gram和形态句法词性分布训练监督分类器。初步与扩展实验验证,生成复合文档能显著提升性能,通过缓解数据稀缺性并中和作者特定的风格偏差。随后在百年和五十年区间的测试证实,词汇级特征能有效追踪词汇转变,而结构模式则捕捉潜在的语法演变。最终结果表明,监督分类可可靠地对历时语言演变进行建模,但未来方法需优化任意时间边界,以更好地捕捉连续的语言发展过程。
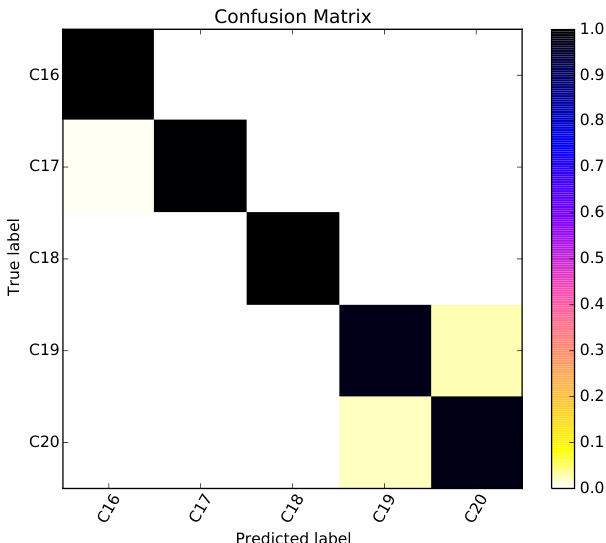
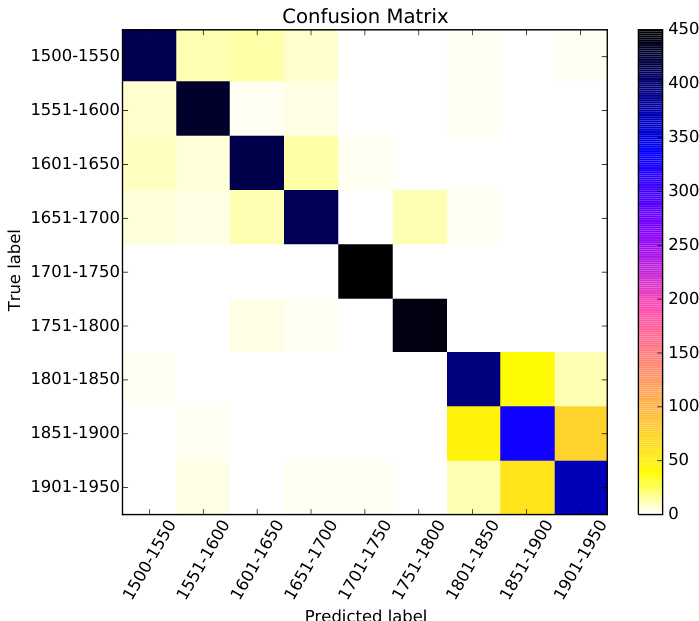
作者使用监督机器学习对历史葡萄牙语文本按出版年代进行分类,重点考察词汇与形态句法特征。结果表明,将文本分类至百年和五十年区间具有较高准确率,其中词一元组表现最佳,POS三词组捕捉结构语言变异。混淆矩阵显示大多数时期的分类近乎完美,相邻时间段之间存在一定混淆。词一元组取得最高分类准确率,优于其他特征类型。POS三词组捕捉结构语言变异,尽管准确率低于词一元组,但表现依然强劲。相邻时间区间的混淆度最高,尤其在19世纪和20世纪,表明这些时期具有相似的语言特征。
作者使用带有词汇和形态句法特征的机器学习模型对历史葡萄牙语文本按出版年代进行分类。结果表明,预测百年时间区间具有较高准确率,词一元组表现最佳,且在采用更细粒度的50年区间时性能依然强劲,尽管相邻时期间存在一定混淆。百年区间的分类准确率极高,词一元组取得最优表现。50年区间的性能保持强劲,仅相邻时间段间出现少量混淆。模型对数据生成方法表现出鲁棒性,人工文档的效果优于较小样本。
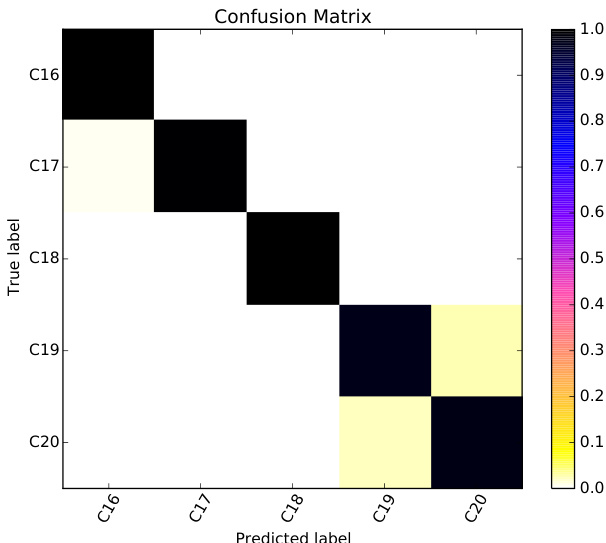
作者使用词汇和词性n-gram作为特征对历史文本按出版年代进行分类。结果表明,词一元组取得最高准确率,显著优于其他特征类型与基线。性能随特征类型变化,基于词汇的特征在一元组时达到峰值,而基于POS的特征随n-gram阶数升高而提升。词一元组取得最高分类准确率,优于所有其他特征类型。高阶词n-gram的准确率有所下降,而POS n-gram的性能随阶数增加而提升。使用词一元组的分类器取得近乎完美的准确率,大幅超越随机基线。

{"summary": "作者使用基于词汇和形态句法特征训练的机器学习分类器,对历史葡萄牙语文本按出版年代进行分类。结果表明,结合线性SVM使用词一元组可实现高分类准确率,且在使用更大规模的人工生成数据集时性能显著提升。表现最佳的模型在百年和五十年时间区间均取得近乎完美的准确率,而基于POS的特征同样表现强劲,尤其是三词组。", "highlights": ["通过人工合成文档生成更大规模数据集可大幅提升分类准确率。", "词一元组取得最优性能,在百年和五十年时间区间均实现近乎完美的准确率。", "POS三词组同样表现强劲,表明即使时间跨度较短,结构语言变化仍可被有效检测。"]}
作者使用带有词汇和形态句法特征的机器学习模型对历史葡萄牙语文本按出版年代进行分类。结果表明,使用词一元组可实现高分类准确率,即使时间区间缩减至50年,性能依然强劲,表明该方法在捕捉时序语言变异方面的有效性。在50年较小时间区间下,词一元组的分类准确率依然保持高位。所有时间区间的性能均表现良好,仅在19世纪与20世纪初之间存在轻微混淆。POS三词组取得显著准确率,表明结构语言变化可随时间推移被有效检测。
实验评估了基于词汇和形态句法特征训练的监督机器学习模型,用于对历史葡萄牙语文本按出版年代进行分类。结果表明,词一元组在百年和五十年区间内均持续产生最高分类准确率,而词性三词组有效捕捉了潜在的结构语言转变。尽管模型保持强劲性能,相邻时期间仍存在轻微的分类重叠,尤其在19世纪和20世纪,这反映了渐进的语言过渡。总体而言,研究结果验证了通过基于n-gram的特征提取可可靠地检测时序语言演变,且模型鲁棒性因扩展和合成数据增强训练集而进一步提升。