Command Palette
Search for a command to run...
卷积神经网络
摘要
一句话总结
本研究提出了一种用于卷积神经网络的 Dropout 训练框架,该框架使用概率加权池化替代标准的最大池化,通过多项分布激活采样在测试阶段进行模型平均,在无需数据增强的情况下于 MNIST 数据集上达到了最先进的性能,并在 CIFAR-10 和 CIFAR-100 上取得了极具竞争力的结果。
核心贡献
- 将 Dropout 应用于最大池化层,在数学上等价于在训练期间按照多项分布随机选择激活值。这一等价关系阐明了标准最大池化 Dropout 操作背后的随机机制。
- 提出将概率加权池化作为确定性最大池化的直接替代品,用于在测试阶段执行模型平均。实证评估表明,该方法相比传统池化方法具有更优越的性能。
- 同时为最大池化层和全连接层设计 Dropout,可在无需数据增强的情况下于 MNIST 上达到最先进的准确率,并在 CIFAR-10 和 CIFAR-100 上取得极具竞争力的结果。此外,研究表明,尽管卷积架构本身已提供固有的正则化效果,但卷积 Dropout 仍能显著改善模型的泛化能力。
引言
深度卷积神经网络彻底革新了视觉识别领域,但在有限数据上训练时仍极易发生过拟合。尽管 Dropout 已成为全连接层的标准正则化技术,但先前研究大多忽略了其在卷积层和池化层中的应用,其前提是假设架构中的权重共享已足以缓解过拟合。作者将 Dropout 同时应用于最大池化层和卷积层,以系统性地提升模型泛化能力。研究证明,最大池化 Dropout 的功能等同于多项分布激活采样,并在测试阶段引入概率加权池化,以高效近似指数级数量的子模型的平均值。该方法在无需依赖数据增强的情况下,于 MNIST 上取得了最先进的性能,并在 CIFAR 基准测试中展现出极具竞争力的结果,其表现优于既定的随机池化方法。
数据集

- 数据集构成与来源: 作者使用了 CIFAR-10 数据集,该数据集包含十个类别的自然图像,最初来源于基于网络的 Tiny Images 集合。
- 子集详情: 数据集包含 50,000 个训练样本和 10,000 个测试样本,每张图片格式均为 32x32 的 RGB 图像。
- 数据处理: 像素值被归一化至 [0, 1] 范围,且作者从每张图像中减去了基于整个数据集计算得到的通道均值。
- 模型使用与训练: 数据遵循标准的 50,000 训练样本与 10,000 测试样本划分。为应对较高的类内差异,作者对更深的卷积网络进行了 1000 个 epoch 的训练,并在卷积层、最大池化层和全连接层分别应用保留概率为 0.3、0.5 和 0.7 的 Dropout。模型评估采用概率加权池化,并明确指出报告结果不包含任何训练数据增强。
方法
作者将最大池化 Dropout 作为一种随机机制,用于在卷积神经网络(尤其是池化层)的训练过程中引入变化。该框架从卷积层和池化层的标准前向传播开始,激活值在此过程中通过最大池化等池化函数进行处理。在引入最大池化 Dropout 的情况下,二值掩码会逐元素地应用于每个池化区域内的激活值。该掩码服从保留概率为 p 的伯努利分布,并以 q=1−p 的概率随机将激活值置零。随后,修改后的激活值被送入池化操作。 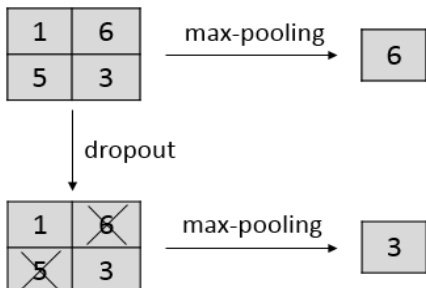
如图所示,若无 Dropout,最大池化会选择池化区域内的最大激活值。引入 Dropout 后,选择过程变为随机过程:例如,若激活值为 1、6、5 和 3,且掩码将 6 和 5 置零,则剩余值(1 和 3)中的最大值 3 将成为输出。这种随机性源于池化激活的选择对应于从多项分布中采样,其中选择激活值 ai(l) 的概率为 pi=pqn−i,n 为池化区域内的单元数量。当所有单元均被丢弃时会出现一种特殊情况,此时以 qn 的概率输出零。该公式表明,最大池化 Dropout 实际上是在训练一个模型混合体,每个模型对应池化区域内不同的活跃单元组合。
为了在测试阶段近似模型平均,作者提出了概率加权池化。池化输出不再是对最大激活值的简单缩放,而是计算区域内所有激活值的加权和,其中每个激活值的权重为其在训练期间被选中的概率。这确保了测试阶段的输出与训练期间使用的多项分布下的期望输出相匹配。该方法无需显式实例化这些模型,即可高效地对 Dropout 生成的指数级数量的可能模型进行平均。
作者还引入了卷积 Dropout,该机制直接将 Dropout 应用于卷积层之前的特征图。在此过程中,二值掩码独立地应用于每个特征图,随后修改后的激活值与学习到的滤波器进行卷积运算。可能的不同卷积输出数量随参数数量呈指数级增长,从而形成一个庞大的模型集成。在测试阶段,网络使用所有单元进行评估,滤波器权重按保留概率进行缩放,从而提供对这些模型平均效果的估计。实证结果表明,尽管卷积 Dropout 能够改善泛化能力,但由于卷积层固有的共享滤波器与局部连接结构已提供了正则化效果,其作用不及最大池化 Dropout 或全连接层 Dropout。
实验
实验在 MNIST、CIFAR-10 和 CIFAR-100 数据集上训练的常规 CNN 架构中,评估了多种池化策略与 Dropout 的应用位置。结果表明,相较于传统替代方案,概率加权池化作为测试阶段对 Dropout 模型平均的近似方法更为准确有效,并持续改善模型的泛化能力。此外,对不同网络层中 Dropout 的探究显示,虽然所有应用位置均能缓解过拟合,但将最大池化 Dropout 与全连接层 Dropout 结合使用能提供最稳健的正则化效果与更优的性能。最终,本研究证实,概率加权池化与战略性 Dropout 集成在无需依赖数据增强的情况下,能显著提升模型准确率。
作者对 CNN 模型评估了不同的 Dropout 技术,重点关注最大池化 Dropout 及其对模型性能的影响。结果表明,结合最大池化 Dropout 与全连接层 Dropout 可实现最低的错误率,相较于其他 Dropout 配置,表明泛化能力得到提升。概率加权池化被强调为一种优于最大池化和缩放最大池化的测试阶段推理方法。结合最大池化 Dropout 与全连接层 Dropout 在测试数据集上取得了最佳性能。在测试阶段,概率加权池化的表现优于最大池化和缩放最大池化。在多个层中使用 Dropout 可以提升性能,但不当的组合可能会导致结果下降。
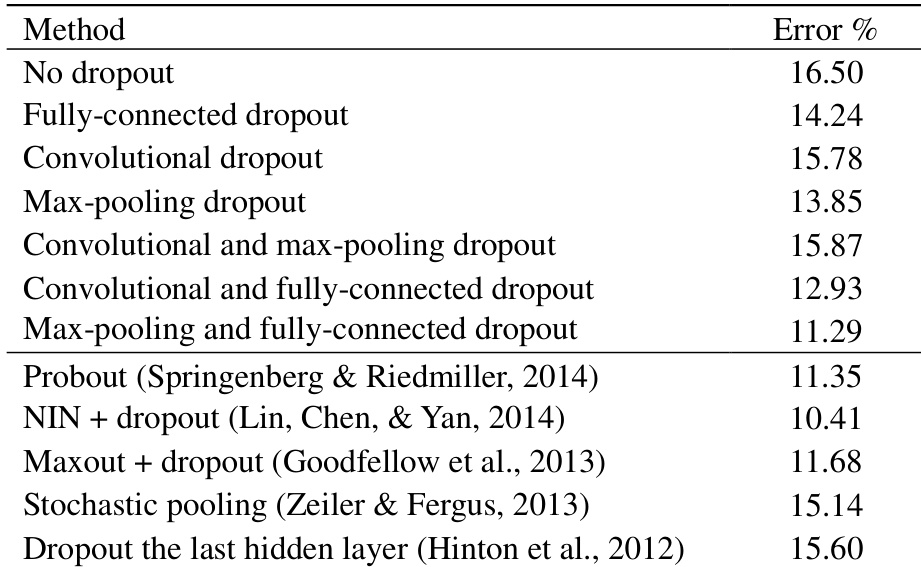
{"summary": "作者在通过最大池化 Dropout 训练后,于测试阶段对比了不同的池化方法,重点关注其在不同保留概率下降低错误率的有效性。结果表明,概率加权池化始终优于最大池化和缩放最大池化,尤其是在较低保留概率下,这表明其泛化能力更强,且能更准确地近似模型平均。", "highlights": ["在所有保留概率下,概率加权池化均能实现比最大池化和缩放最大池化更低的错误率。", "概率加权池化与其他方法之间的性能差距在较低保留概率下最为明显。", "随着保留概率的增加,所有池化方法的错误率趋于收敛,而概率加权池化始终保持稳定优势。"]
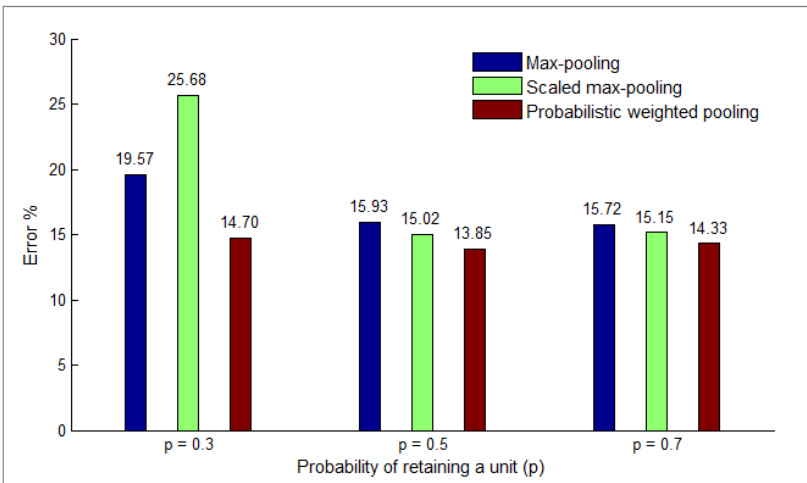
作者在 MNIST 数据集上评估了不同的 Dropout 方法,比较了它们在降低测试错误率方面的有效性。结果表明,结合最大池化 Dropout 与全连接层 Dropout 可实现最低的错误率,其表现优于其他配置及先前的最先进方法。研究发现,在测试阶段近似模型平均方面,概率加权池化优于最大池化和缩放最大池化。结合最大池化 Dropout 与全连接层 Dropout 在 MNIST 上实现了最低的测试错误率。在测试性能方面,概率加权池化优于最大池化和缩放最大池化。在不同层使用 Dropout 可提升泛化能力,但不当的组合可能会降低性能。
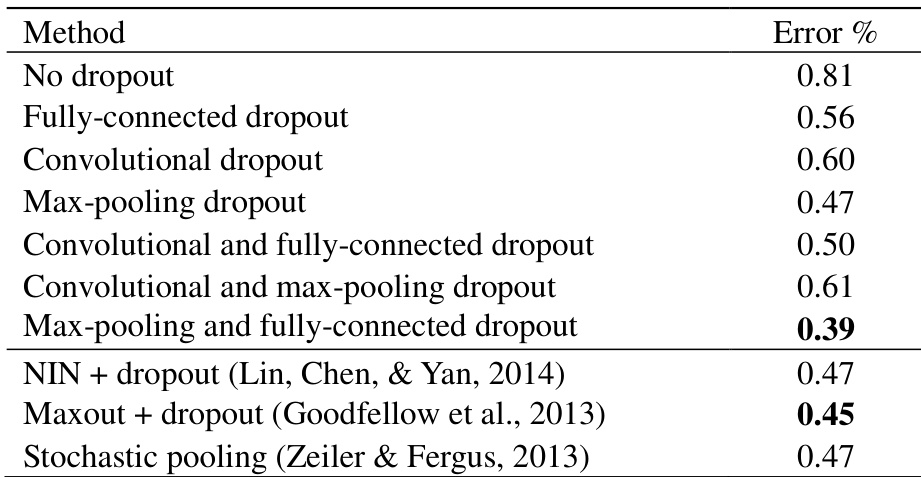
作者在 MNIST 数据集上评估了不同的 Dropout 策略与池化方法,比较了它们对模型性能的影响。结果表明,结合最大池化 Dropout 与全连接层 Dropout 可实现最低的错误率,其表现优于单独的 Dropout 方法及基线方法。在所有配置下,概率加权池化均能持续改善性能,表现优于最大池化和缩放最大池化。结合最大池化 Dropout 与全连接层 Dropout 在 MNIST 上取得了最佳的测试性能。在所有测试配置中,概率加权池化均稳定优于最大池化和缩放最大池化。同时于多个层使用 Dropout 可提升性能,但不当的组合可能会导致结果下降。
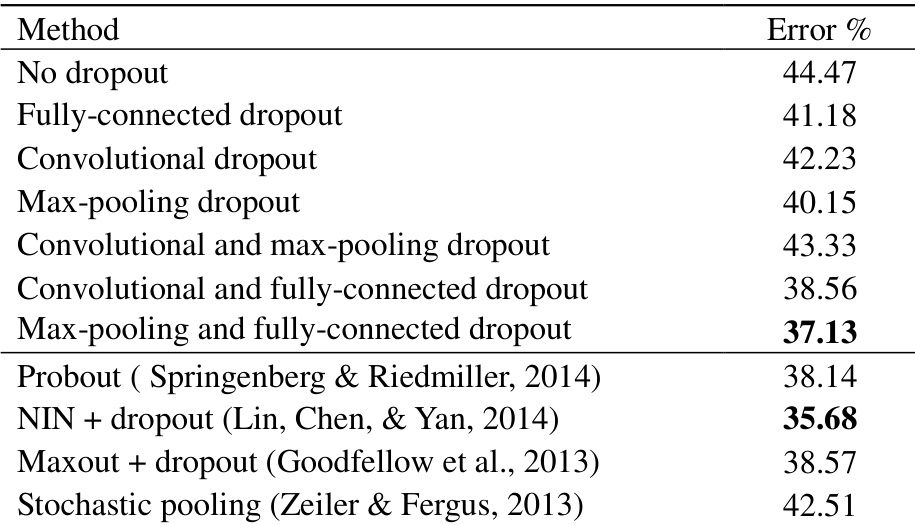
实验在基准数据集上评估 CNN 模型,以评估训练期间的各种 Dropout 配置与推理阶段的池化策略如何影响泛化能力与测试错误率。训练评估验证了结合最大池化 Dropout 与全连接层 Dropout 能产生最稳健的性能,而推理评估则证实,概率加权池化通过更准确地近似模型平均,始终超越标准最大池化与缩放最大池化。最终,定性研究结果表明,战略性协调的多层 Dropout 能够增强泛化能力,而不匹配的组合则可能降低整体模型准确率。