Command Palette
Search for a command to run...
时间序列分析-入门到精通
摘要
一句话总结
本文提出了一种用于重复时间序列的判别分析框架,该框架将传递函数建模为随机变量以考虑组内频谱变异性,通过分析随机倒谱推导出用于最优组间分离的相对功率简约度量,并通过模拟研究和步态变异性分析验证了该方法的有效性。
核心贡献
- 提出了一种用于重复时间序列的统计模型,将传递函数视为随机变量,以同时考虑组间和组内频谱变异性。
- 开发了基于随机倒谱的判别分析方法,该方法能够生成用于最优组间分离的简约相对功率度量,并利用有限数量的估计倒谱系数实现一致的分类。
- 通过模拟研究和步态变异性数据的实证分析,证明了考虑组内频谱变异性的优势。
引言
研究人员常规地分析不同组别的重复时间序列,以提取具有区分度的频域模式,这一做法对于步态分析和生物医学信号处理等应用至关重要。然而,传统的判别方法通常假设各组内的频谱特征保持均匀,从而忽略了个体重复样本之间自然发生的周期性变化。为弥补这一不足,作者采用了一种将传递函数视为随机变量的建模范式,从而能够同时捕捉组间和组内的频谱差异。随后,他们将判别分析应用于随机倒谱,得到了紧凑的相对功率指标,在合理考虑组内变异性的同时,能够可靠地对新观测值进行分类。该方法计算简便,因为它仅依赖于对有限集估计倒谱系数应用标准判别程序。
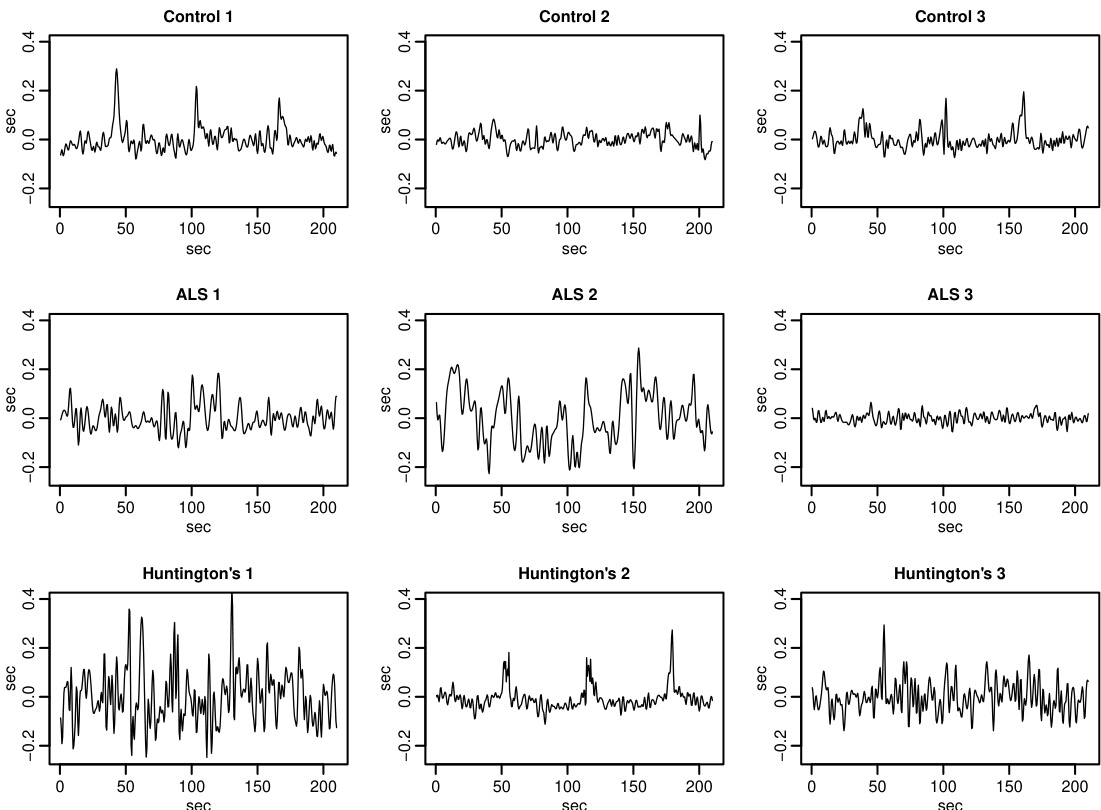
数据集

-
数据集构成与来源 作者分析了由 Hausdorff 等人(2000年)收集并公开托管于 PhysioNet 上的步态变异性数据。该数据集记录了来自三个神经疾病队列个体的步幅间隔,以支持病理特征刻画与诊断分类。
-
子集详情
- 健康对照组:16 名参与者
- 肌萎缩侧索硬化症(ALS)患者:11 名参与者
- 亨廷顿病(Huntington’s disease)患者:18 名参与者
- 总队列:45 名个体
-
裁剪与处理流程
- 参与者佩戴足底压力传感器以正常步速行走。
- 分析仅提取左脚步幅间隔,丢弃 20 秒的启动期,并保留每位受试者固定的 3.5 分钟窗口。
- 采用 3 倍标准差中值滤波器去除走廊转弯引起的伪影。
- 信号通过三次平滑样条进行插值,重采样至 2 Hz,并进行线性去趋势处理。
- 最终为每位参与者生成一个标准化、去趋势且长度为 420 的步幅间隔序列。
-
模型使用与分析
- 处理后的序列使用 7 个多锥体(multitapers)转换为对数频谱估计,交叉验证选出 4 个频谱系数。
- 构建两个判别函数以对比特定频带的功率,将每位受试者映射至二维特征空间。
- 分类性能采用留一法交叉验证进行评估,而非固定的训练集与测试集划分。
- 生成的判别分数用于与替代信息论分类器进行对比评估,并作为区分三种神经疾病组的可解释诊断工具。
方法
作者采用基于倒谱的框架对时间序列数据进行判别分析,旨在识别能够最佳分离组别且同时考虑组内频谱变异性的低维度量。该方法的核心在于通过对数频谱及其关联的倒谱系数将时间序列转换为函数表示,从而实现对组间差异的严谨且可解释的分析。特定重复样本的对数频谱定义为 γjk(λ)=log∣Ajk(λ)∣2,其中 Ajk(λ) 表示第 j 组第 k 个重复样本的傅里叶变换。组平均对数频谱记为 αj(λ)=E{γjk(λ)},其与该均值的偏差为 βjk(λ)=γjk(λ)−αj(λ)。这些对数频谱随后通过余弦级数转换为倒谱系数,得到 ℓ≥1 时的 cjkℓ=∫01γjk(λ)2cos(2πλℓ)dλ,以及 cjk0=∫01γjk(λ)dλ,从而构成序列 cjk∈RN。组平均倒谱 aj 与偏差倒谱 bjk 同样分别由 αj 和 βjk 导出。
该方法通过构建倒谱 Fisher 判别分析推进,旨在寻找倒谱系数的线性组合,以在相对于组内变异性的情况下最大化组均值间的分离度。设 y0∈RN 为权重向量,并定义线性函数 ∑ℓ=0∞y0ℓcjkℓ 的分离度为 ∣∣y0∣∣Λ2=∑ℓ,m=0∞y0ℓΛ(ℓ,m)y0m,其中 Λ(ℓ,m) 为组间核。组内核 Γ(ℓ,m)=E(bjklbjkm) 定义了线性组合间的协方差,且 ∣∣y0∣∣Γ2=⟨y0,y0⟩Γ。第一个判别函数通过最大化 ∣∣y1∣∣Λ 获得,约束条件为 ∣∣y1∣∣Γ=1,结果为 djk1=∑ℓ=0∞y1ℓcjkℓ。高阶判别函数按顺序定义,确保其与低阶判别函数关于 Γ 正交,即 yq 满足对于 m<q 有 ⟨yq,ym⟩Γ=0。非平凡判别函数的数量 Q 受限于组数 J−1 以及 Λ 和 Γ 的秩。该框架产生了简约且可解释的度量,能够捕捉组间最具判别力的特征。
该方法可推广至对数频谱权重函数。当 ∑ℓ=0∞∣yqℓ∣<∞ 时,权重函数 ξq(λ)=yq0+∑ℓ=1∞yqℓ2cos(2πλℓ) 存在,且判别函数 djkq 可表示为 ∫01ξq(λ)γjk(λ)dλ。该公式建立了倒谱方法与基于积分的判别分析之间的联系,尽管倒谱方法更为通用,因为它在积分对数频谱判别函数存在时将其包含在内。
估计过程采用有限维近似进行。给定 n 个长度为 N 的独立时间序列片段,作者考虑通过 c^jkℓ=N−1∑m=0N−1γ^jkm2cos(2πλmℓ) 估计倒谱系数,其中 λm=m/N,γ^jkm 为对数频谱估计器。多锥体方法使用 R 个正交数据锥体 hrt,因其具有优良的偏差、方差和分辨率特性而受到推荐。第 r 个加窗周期图为 Ijkrm=N−1/2∑t=1NhrtXjkte−2πiλmt2,多锥体对数频谱估计器为 γ^jkm=log(R−1∑r=1RIjkrm)。
在实际实现中,作者将倒谱系数截断至 L 维,形成 c^jkL=(c^jk0,…,c^jkL−1)T。判别函数与权重函数通过在该有限维向量上应用经典 Fisher 判别分析进行估计。估计的组均值为 a^jL=nj−1∑k=1njc^jkL,总体均值为 a^L=∑j=1Jπ^ja^jL。组间核估计为 Λ^L=∑j=1Jπ^j(a^jL−a^L)(a^jL−a^L)T。组内协方差为 Γ^L=∑j=1Jπ^jΓ^Lj,其中 Γ^Lj=(nj−1)−1∑k=1njb^jkL(b^jkL)T,且 b^jkL=c^jkL−a^jL。第 q 个估计权重函数 y^qL 是 Γ^L−1Λ^L 的第 q 个特征向量,判别函数为 d^jkqL=(y^qL)Tc^jkL。相应的权重函数 ξ^qL(λ)=y^q0L+∑ℓ=1L−1y^qℓL2cos(2πλℓ) 即使理论版本 ξq 仅以极限意义存在,仍具有可解释性。
对具有未知组别归属的新时间序列进行分类时,首先估计其倒谱 c^∗L 并计算其判别函数 d^∗qL。分类规则将观测值分配给最小化 ∑q=1Q(d^∗qL−μjq)2−2log(πj) 的组 j,其中 μjq=∑ℓ=0∞yqℓajℓ 为第 q 个组均值判别函数。该规则在正态分布假设下是最优的,并对应于 Delaigle 和 Hall(2012)提出的质心分类器。倒谱系数数量 L 通过留一法交叉验证选择,以最小化所有重复样本的分类误差。
在正则条件下建立了理论一致性。对对数频谱光滑性的假设确保了组内协方差的最大特征值有界,且最小特征值 σL 衰减缓慢。估计权重函数与判别函数的一致性要求 σL−2n−1/2→0,σL−2N−1/2→0,以及 Ln−1/2→0,当 n,N,L→∞ 时成立。在这些条件下,y^qL 依 Γ-范数收敛于真实权重函数 yq,且 d^jkqL 依概率收敛于 djkq。因此,分类规则 Π^(c^∗L) 依概率收敛于真实组别归属 Π(c∗)。该框架通过使用合并估计 ∑j=1JπjΓj 容纳了组内协方差的异质性,在此设置下估计量仍然有效,尽管分类率可能需要进行调整。该方法为存在组内频谱变异性的判别分析提供了一种稳健且可解释的途径,相较于假设组内重复样本完全相同的传统方法具有优势。
实验
一项模拟研究在不同训练样本量和序列长度下测试条件自回归过程,以评估不同组内频谱变异性水平下的时间序列分类程序。所提出的倒谱 Fisher 判别分析始终比忽略组间频谱差异的传统方法获得更高的样本外分类准确率,其中基于多锥体的估计方法表现最强。尽管倒谱方法在不同频谱变异性水平下均保持了稳健的准确率,但传统信息准则方法随着组内变异性的增加出现了显著的性能下降。这些结果验证了所提出框架在处理时间序列分类中异质频谱模式时的优越稳定性和有效性。
作者开展了一项模拟研究,以评估不同组内频谱变异性水平下的分类程序。结果表明,倒谱 Fisher 判别分析在所有条件下均持续优于基于信息准则的方法,性能差异受对数频谱估计器选择的影响。未考虑组内变异性的方法的分类率对频谱变异性的增加更为敏感。倒谱 Fisher 判别分析在所有实验条件下均实现了高于基于信息准则方法的分类率。在倒谱方法中,多锥体估计器表现最佳,而直接估计器表现最差。忽略组内频谱变异性的方法随着变异性的增加表现出分类性能下降。
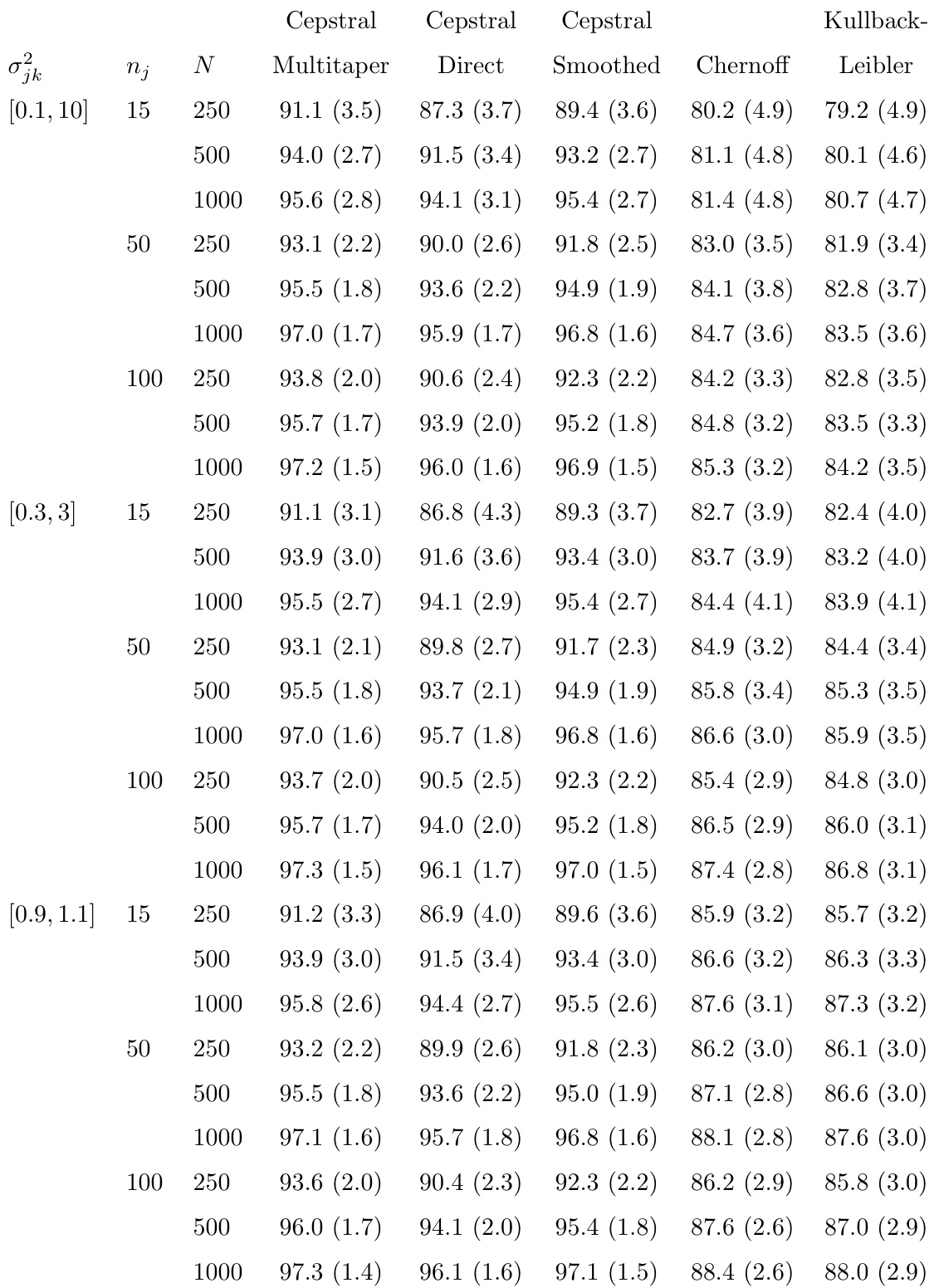
该模拟研究在不同组内频谱变异性水平下评估分类程序,以验证其针对频谱波动的鲁棒性。研究结果表明,显式建模组内变异性至关重要,因为忽略该变性的方法在变异性增加时会遭受严重的性能下降。倒谱 Fisher 判别分析在所有条件下均持续优于基于信息准则的方法,整体准确率高度依赖于对数频谱估计器的选择。在测试的估计器中,多锥体方法提供了最可靠的结果,而直接方法效果最差。