Command Palette
Search for a command to run...
一键部署 LivePortrait
摘要
一句话总结
本研究通过在线调查以及软件文档与技术手册的分析,评估了 DSpace、EPrints 和 Greenstone,以考察每种开源数字图书馆管理软件如何向全球受众吸收并传播信息。
核心贡献
- 本文对三种开源数字图书馆管理系统(DSpace、Greenstone 和 EPrints)进行了系统的对比分析,以评估其架构设计与机构知识传播的功能能力。
- 通过综合在线调查与技术文档审查的发现,本研究建立了一个决策框架,将特定的软件功能与组织需求(包括内容格式、分发策略和部署时间线)相匹配。
- 评估结果表明,这些采用 GPL 许可的平台提供了可扩展且厂商中立的架构,在降低实施成本的同时,支持数字馆藏的可靠全球传播。
引言
数字图书馆已从简单的数字档案演变为支持全球协作以及学术与文化资产长期保存的复杂网络化平台。商业管理系统通常限制定制化并导致厂商依赖,而现有的开源替代方案在不同架构和元数据标准之间碎片化,增加了平台选择的难度。本文分析了包括 DSpace、Greenstone 和 EPrints 在内的主流开源数字图书馆管理系统,以将其技术能力与现实世界的机构需求进行映射。通过评估其可扩展性、对象模型与部署工作流,本文提供了一份结构化的参考指南,使组织能够根据内容格式、分发策略和技术约束选择最佳框架。
数据集
-
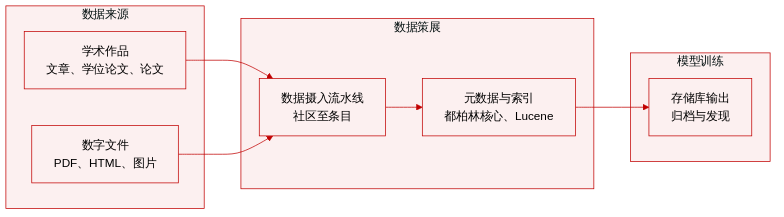
数据集构成与来源: 本文描述 DSpace 为麻省理工学院图书馆与惠普实验室联合开发的数字资产管理存储库。该数据集包含由大学、研究中心和图书馆贡献的机构学术产出,如文章、论文、学位论文和博士论文,以支持开放获取与长期数字归档。
-
各子集的关键细节: 数据遵循严格的层次结构。社区和子社区对应学院或实验室等机构单位。集合(Collections)用于归类相关内容,并可跨越多个社区。条目(Items)作为基础归档元素,每个条目均绑定至单一所属集合。条目进一步细分为软件包(Bundles),其中包含按类型分类的位流:ORIGINAL 文件、THUMBNAILS(缩略图)、用于索引的 TEXT(文本)、LICENSE 文档以及 CC_LICENSE 元数据。该系统支持多种格式,包括 PDF、HTML、JPEG、TIFF、MP3 和 AVI。
-
本文的数据使用方式: 本文将 DSpace 视为存储库架构,而非机器学习训练语料库。文中未指定模型训练划分、混合比例或算法微调流程。相反,本文重点探讨系统如何摄取、保存、索引并公开学术内容,以实现互操作性发现与机构管理。
-
处理与元数据构建: 本文概述了标准化的摄取与保存工作流。每个条目均分配规范的都柏林核心(Dublin Core)元数据记录,并可选支持 MODS 和 MARC21 等交叉映射,以便与外部系统进行交换。全文提取在提交时自动运行,以填充 TEXT 软件包用于搜索索引。非动态 HTML 文档使用相对链接进行保存,以维持内部引用,而绝对链接则原样存储。批量工具将内容转换为包含 XML 元数据文件的目录结构,用于导入和导出。持久标识符通过 CNRI Handle System 分配,搜索索引由 Apache Lucene 驱动,以支持字段查询、词干提取和停用词过滤。
方法
本文采用模块化且可扩展的架构,旨在支持开放获取存储库系统中数字学术内容的管理、保存与检索。整体框架围绕三个主要阶段构建:提交、管理与检索,各阶段由不同的组件与工作流驱动。在系统核心,元数据与数字文件被组织为条目,并存储于集合与社区中,构成保存与发现的基础。
提交流程始于提交者,其通过 Web 界面上传文件及相关元数据。如下图所示,该输入被处理为结构化数据流并路由至管理层。管理组件负责条目的存储,条目由数字文件及其对应元数据构成。这些条目在集合与社区中进行组织,作为内容的逻辑分组。系统通过在现行格式下维护归档来确保长期保存,并配备机制以随时间推移更新和管理存储库内容。

在管理层内,系统支持对元数据模式的管理控制,允许管理员定义捕获每个条目类型的字段。此配置可实现提交表单的自定义,确保仅向用户展示相关的元数据字段。系统支持多种条目类型,如同行评审期刊文章、学位论文和技术报告,每种类型均拥有独立的必填与选填元数据字段集。此灵活性通过分层元数据处理方法实现,其中模式定义分为三到四个阶段:定义字段的最大集合、指定条目类型、确定每种类型的必填字段,以及将其映射至开放档案倡议(OAI)标准以实现互操作性。系统还提供基于 Perl 的核心 API,使开发人员能够访问并扩展底层数字图书馆功能。

检索阶段旨在支持终端用户的高效浏览与搜索。系统允许用户基于元数据浏览功能在存储库中导航,支持按作者、部门、年份或出版物类型等条件过滤结果。此导航通过“表示”(representations)或“视图”(views)概念实现,该概念从元数据字段生成层次结构。如下图所示,这些视图源自条目元数据,提供了一种灵活的内容组织与展示方式。系统支持全文与基于字段的搜索,允许用户通过 SQL 查询以细粒度检索特定元数据字段。此外,系统符合 OAI 标准,支持外部服务自动收割元数据,从而促进内容在全球存储库网络中的传播。

系统架构还包含多个用户角色,包括管理员、编辑和作者,各角色拥有独立的权限与职责。管理员负责后端配置,包括 Web 界面的外观与功能以及整体存储库设置。编辑在发布前审核提交内容,并可修正元数据以保持一致性。作者负责提交文档并管理自己的提交内容(包括编辑与删除),但需受管理员权限限制。该系统基于开源技术构建,数据库采用 MySQL,Web 服务器采用 Apache,应用逻辑由 Perl 实现,确保平台具备健壮性、可扩展性与可定制性。