Command Palette
Search for a command to run...
一键部署 RolmOCR:跨场景极速 OCR 开源识别新基准
摘要
一句话总结
在1,844个用户特定的孤立字符上训练开源Tesseract 2.01 OCR引擎,并在1,133个小写罗马字母字符上进行评估,可获得83.5%的字符级准确率,其中分割失败率为5.56%,误分类率为10.94%。
核心贡献
- 本研究将Tesseract 2.01开源OCR引擎适配于识别手写小写罗马字母,通过在孤立字符和自由流文本样本上进行用户特定训练实现该目标。
- 为捕捉个体书写特征,本研究基于每位用户1844个训练字符开发了定制模型,无需从零构建新引擎。
- 在包含1133个字符的测试集上进行系统评估,得出83.5%的字符级准确率;实证分析显示分割失败率为5.56%,分类错误率为10.94%。
引言
光学字符识别系统可自动将纸质文档转换为数字文本,从而支持表单处理、邮件路由及金融文档处理等关键工作流。尽管历经数十年研究,构建能够持续保持高精度的手写OCR引擎仍是一项长期存在的技术挑战。尽管Tesseract等成熟的开源引擎在印刷体上表现可靠,但其对手写输入的有效性极少经过严格评估或优化。研究团队利用Tesseract 2.01填补这一空白,针对小写罗马字母实施用户特定训练。团队在孤立字符和自由流手写体上对引擎进行系统评估,测量字符级与词级准确率,以证明其在手写文档处理中的实际可行性。
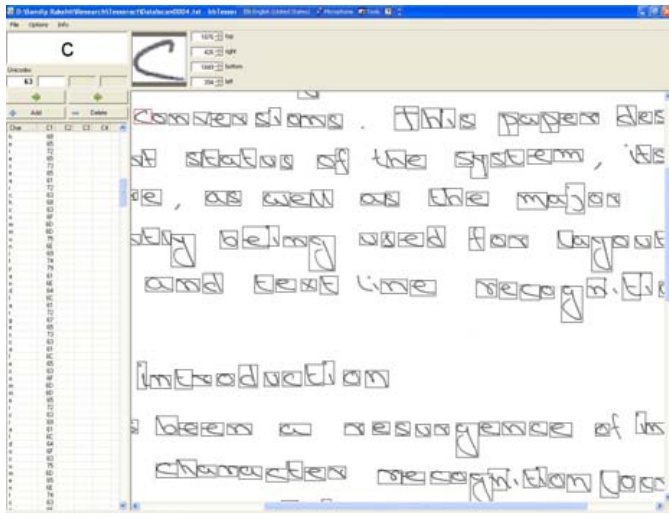
数据集

- 数据集构成与来源:研究团队编制了专注于小写罗马字母的手写数据集。数据来自四位不同用户,每位贡献者提供六页手写文档,分为两类:孤立字符及从技术文章提取的自由流文本。
- 子集详情与划分:每位用户的合集包含四页孤立小写字符和两页连续文本。研究团队将每位用户的三页孤立字符和一页自由流文本分配至训练集,同时从每个类别中预留一页用于测试。训练部分包含每位用户约70个孤立字符样本和120个词(约650个字符)的自由流文本,单个用户数据集中最多包含1,844个带标签字符样本。
- 数据使用与处理:该数据集用于训练Tesseract 2.01版本以进行自定义手写识别。研究团队为每个训练页面生成参考框文件,随后利用该文件引导OCR引擎启动,并自动标记其余训练图像。团队使用mftraining、cntraining、unicharset_extractor和wordlist2dawg执行标准Tesseract训练流程,生成八个核心模型文件,包括intemp、pffntable、Microfeat、normproto、unicharset、基于DAWG的词典、user-words和DangAmbigs。这些文件均以前缀三个字母的语言代码命名,并存放于tessdata目录中以供最终识别。
- 元数据与边界框构建:边界框元数据最初由Tesseract自动生成,以文本框格式存储字符顺序与坐标数据。当目标字符集偏离引擎默认训练集时,研究团队使用bbTesseract工具手动修正不准确之处,随后重命名输出文件以符合所需的命名规范。
方法
研究团队采用Tesseract OCR引擎作为字符识别流水线的基础。该开源光学字符识别系统最初由惠普开发,后由Google在Apache License 2.0协议下维护。Tesseract采用模块化架构运行,包含行与词查找器、词识别器、静态字符分类器、语言分析器及自适应分类器等关键组件。这些模块协同工作以处理输入图像、定位文本区域、识别单个字符,并应用特定语言规则以提升准确率。该引擎不支持文档版面分析或输出格式化,而是专注于字符级识别。
为启用特定语言(如英语)的识别功能,Tesseract需要一组存储在tessdata子目录中的八个训练文件。这些文件包含语言与结构数据,例如频率词典、词表、字符形状原型及unicharset定义,共同定义字符集与语言模型。训练过程始于标注训练图像的准备工作,其中每个字符均标注有边界框坐标。此步骤通过bbTesseract工具完成,该工具便于创建框文件,明确训练图像中每个字符的位置与标签。
如图所示,训练流程通过将预处理图像(例如fontfile.tif)输入Tesseract并附带特定命令行参数来执行:tesseract fontfile.tif junk nobatch box.train。该命令生成包含图像中每个字符特征向量的.tr文件,以捕捉形状与结构信息。随后使用两个专用程序处理这些特征:mftraining将字符形状特征聚类为原型,entraining构建字符分类器的训练数据。这些步骤对于生成使Tesseract能够高精度识别文本的特定语言模型至关重要。
实验
实验通过训练单用户模型处理孤立与自由流手写小写罗马字母,同时禁用语言分析模块,以评估Tesseract OCR引擎的核心识别准确率与分割鲁棒性。定性分析表明,尽管基线字符识别表现尚可,但系统整体可靠性受分割失败影响,尤其是由于引擎固有偏向均匀印刷文本而导致的过度分割与内部字符断裂。因此,研究得出结论:实际部署需结合多用户验证、扩充训练数据以及集成词级词典匹配,方能有效处理连续手写体。
研究团队评估Tesseract OCR引擎在手写小写罗马字母上的性能,重点关注孤立与自由流文本样本。结果显示,字符级识别准确率高于词级准确率,分割失败是主要误差来源,尤其在自由流文本中更为显著。系统在孤立字符上的表现优于自由流文本,且词的误分类率显著更高。字符级识别准确率高于词级准确率,自由流文本的表现低于孤立字符。分割失败对误差贡献显著,尤其在自由流文本中,词级准确率明显偏低。词的误分类率高于孤立字符,表明系统在处理草书与连续文本时面临挑战。
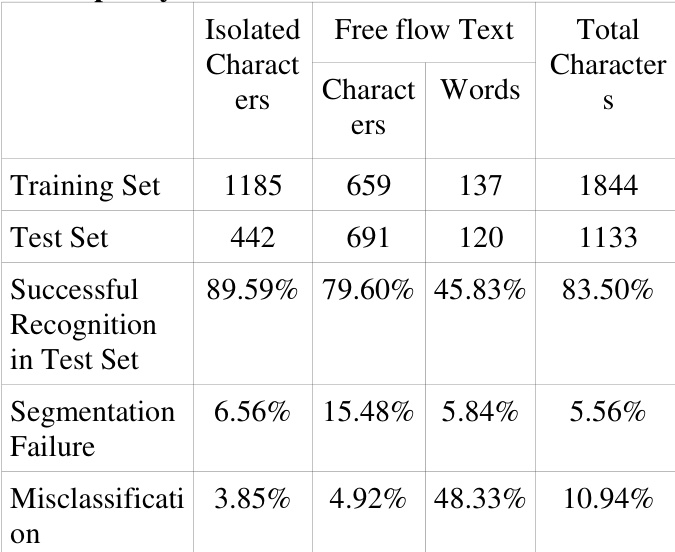
研究团队评估Tesseract OCR引擎在手写小写罗马字母上的性能,聚焦字符与词识别准确率。结果显示,系统达到中等水平的字符级准确率,但在分割方面存在困难,尤其针对特定字符,导致词级出现显著误差。分析表明,大量失败源于过度分割及草书文本识别困难。系统对特定字符表现出高失败率,尤其是字母“i”,对整体误分类有显著贡献。受分割问题影响,词级准确率显著低于字符级准确率。大多数识别误差归因于过度分割及处理草书文本的挑战。
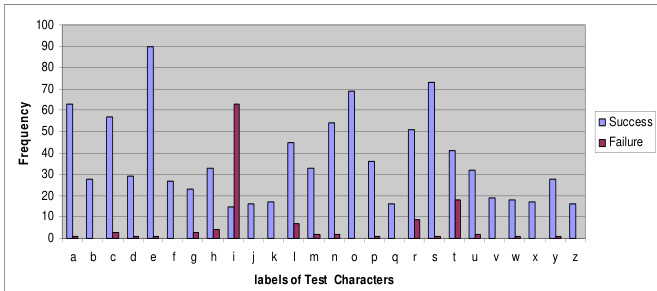
研究团队评估Tesseract OCR引擎在手写小写罗马字母上的表现,以检验其在孤立与连续文本样本中的字符与词识别能力。实验验证字符级识别始终优于词级准确率,且性能在自由流与草书手写体上显著下降。定性分析表明,分割失败(尤其是过度分割)是主要误差来源,而非根本性的识别局限。因此,系统在处理连续文本时表现出明显困难,确立了分割为实际应用的关键瓶颈。