Command Palette
Search for a command to run...
初学者的基本统计知识
摘要
一句话总结
通过将基于低频观测的时间改变 Lévy 过程的半参数推断重构为复合函数估计问题,本研究提出了一种复合特征函数估计方法。该方法能够给出一致的 Lévy 密度估计,并具有统一性与逐点极小极大最优收敛速率,算法性能通过时间改变的 Normal Inverse Gaussian 过程仿真得到验证。
核心贡献
- 针对多维 Lévy 过程的时间改变对应过程,利用低频观测数据开发了一套一致的 Lévy 密度估计程序,并借助其与复合函数估计的既定联系。
- 推导了该估计量的统一性与逐点收敛速率,并证明这些速率在适当的时间改变 Lévy 模型类中达到极小极大最优。
- 通过时间改变的 Normal Inverse Gaussian Lévy 过程仿真研究,实证展示了所提估计算法的性能。
引言
金融建模日益依赖时间改变的 Lévy 过程来捕捉波动率聚集等复杂市场动态,但参数化假设往往会引入显著的模型误设偏差。尽管高频统计方法在跳跃估计方面已取得进展,但在面对跳跃不可观测且增量存在依赖性的真实低频数据时仍面临困难。为弥补这一空白,作者利用复合特征函数估计方法构建了一个非参数框架,直接从低频观测中恢复底层 Lévy 密度。研究证明了该估计量能够达到最优的极小极大收敛速率,并通过 Normal Inverse Gaussian 过程仿真验证了该方法的有效性,为传统参数化建模提供了一种稳健且灵活的替代方案。
数据集

- 数据集构成与来源: 作者使用由多元时间改变 Lévy 过程生成的合成时间序列数据。观测值由离散增量 Zj=YΔj−YΔ(j−1) 组成(j=1,…,n),其中每个样本在固定间隔 Δ 处捕捉过程状态。
- 关键细节与过滤规则: 数据按 d 个分量构建,每个分量由 Lévy 密度 νk 支配。作者未采用经验过滤,而是施加理论约束:密度必须属于 Blumenthal-Getoor 类 Bγ(其中 γ>0)以确保无限跳跃活性,具有阶数 p>2 的有限绝对矩,并满足相关时间改变的特定尾部衰减条件。跨分量依赖性被显式建模,模型误设偏差由扩散相关性 Σ(k,l) 界定。
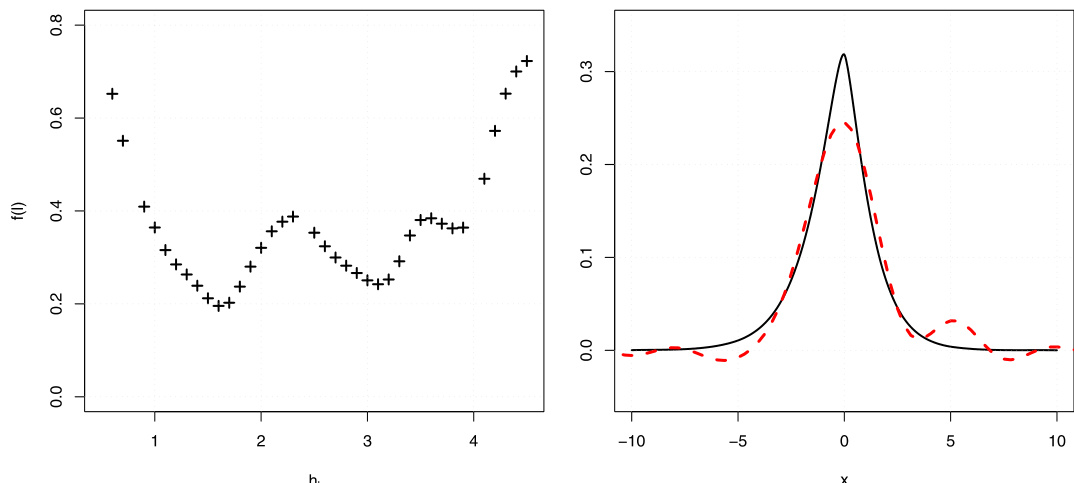
- 数据使用与处理流程: 数据集输入至三步估计程序。首先,计算经验特征函数及其直至三阶的偏导数。其次,利用基于比率的估计量推导特征指数的二阶导数,该估计量根据阈值 κ/n 自适应调整。最后,应用正则化傅里叶逆变换以恢复 Lévy 密度,采用在 [−1,1] 上支撑的核函数 K 以及衰减的带宽序列 hn。
- 结构与分析框架: 该方法不依赖传统的裁剪或元数据标记,而是基于局部光滑类 Hs(x0,δ,D) 评估逐点收敛性。作者在整体光滑性假设 Sβ 下推导了几乎必然一致收敛速率,并根据跳跃活性指数 γ 与时间改变过程拉普拉斯变换的尾部行为动态调整带宽 hn。
方法
作者提出了一种估计时间改变 Lévy 过程 Lévy 密度的方法,重点在于估计 Lévy 密度的二阶矩,记为 νˉk(x)=x2νk(x),其中 νk(x) 是第 k 个分量过程的 Lévy 密度。该框架基于观测过程 Yt=LT(t) 的特征函数,其中 Lt 为 d 维 Lévy 过程,T(t) 为非递减的时间改变过程。估计程序基于增量 Z=YΔ 的特征函数,其表达式为 ϕZ(u)=E[exp(iu⊤Z)]=LΔ(−ψ1(u1)−⋯−ψd(ud)),其中 ψk(u) 为第 k 个分量 Lévy 过程的特征指数,LΔ 为时间改变 T(Δ) 的拉普拉斯变换。
该方法的核心在于恢复特征指数的二阶导数 ψk′′(u),该导数通过关系式 F[νˉk](u)=−ψk′′(u) 与 νˉk(x) 的傅里叶变换相关联。这一目标通过利用特征函数 ϕZ(u) 的导数与特征指数 ψk(u) 之间的关系实现。具体而言,作者推导了将 ψk′′(u) 表示为 ϕZ(u) 导数与非退化分量 Ltl 特征指数的恒等式。这些恒等式见于公式 (3.5),涉及在特定向量 u(k) 处计算的 ϕZ 导数之比,从而隔离第 k 个分量。推导过程假设扩散波动率 σk 已知,模型的可识别性依赖于过程 Ltl 非退化的假设。
估计过程始于构建 ψk(u) 的估计量 ψk(u),该估计量定义为经验特征函数导数之比的归一化积分。随后利用该估计量通过推导出的恒等式获得 ψk′′(u) 的估计值。最后一步应用正则化傅里叶逆变换,从估计的 ψk′′(u) 中估计 νˉk(x)。该方法还通过考虑特征指数的更高阶导数(例如与 νk(x)=x4νk(x) 的傅里叶变换相关的 ψk(4)(u))来处理扩散波动率未知的情况。
该方法的理论分析涉及证明所提估计量的一致性与收敛速率。作者通过界定真实函数 νˉk(x) 与其估计量 νk(x) 之间的偏差来建立逐点收敛速率,该偏差被分解为随机项与偏差项。随机项通过分析经验特征函数与其期望之间的差值进行探讨,并利用关于加权上确界范数大偏差的命题进行界定。该命题为经验矩与理论矩之差的上确界提供了集中不等式界,这对控制随机误差至关重要。偏差项则利用 Lévy 密度的光滑性属性与正则化核进行界定。整体框架确保了在关于 Lévy 密度与时间改变过程的光滑性及尾部行为的适当假设下,估计量能够达到最优收敛速率。
实验
评估工作采用时间改变的 Normal Inverse Gaussian 过程仿真研究,结合 Gamma 与积分 CIR 时间改变机制,以测试自适应 Lévy 密度估计量的有限样本性能。通过应用准最优带宽选择策略,实验验证了算法在不同模型参数与样本量下恢复真实底层密度的准确度。结果表明,该方法始终能提供合理的近似,在不同配置下保持稳健性能,且仅随样本量减少而呈现可预测的性能下降,这证实了其在建模复杂随机过程方面的实用价值。
作者分析了时间改变 Lévy 过程中 Lévy 密度估计量的收敛速率,重点考察 Gamma 过程与积分 CIR 过程两种时间改变类型。收敛行为取决于底层 Lévy 过程与时间改变过程的属性,当 Lévy 过程均值为正与为零时观察到不同的渐近速率。结果显示,收敛速率通常较慢,尤其是对于多项式衰减的时间改变过程,但所提估计方法在有限样本下表现良好。Lévy 密度估计量的收敛速率依赖于 Lévy 过程的均值,在均值为正与为零时表现出不同的渐近行为。收敛速率通常较慢,呈现对数或多项式衰减,并受时间改变与底层 Lévy 过程属性的影响。自适应估计及其恢复 Lévy 密度关键泛函的能力表明,该方法在有限样本下展现出合理性能。

本研究评估了时间改变 Lévy 过程中 Lévy 密度的统计估计量,重点考察 Gamma 与积分 CIR 时间改变,以验证正均值与零均值条件下的收敛行为。分析表明,渐近收敛本质上较慢,通常遵循由时间改变机制与底层过程相互作用决定的对数或多项式衰减模式。尽管存在这些理论局限,所提方法仍展现出稳健的有限样本性能,通过自适应估计技术成功恢复了关键密度泛函。最终,研究结果证实了该估计量的实用价值,同时强调了复杂随机建模中收敛缓慢的持续挑战。