Command Palette
Search for a command to run...
实现 1.4—3.7 倍推理加速,MIT 提出 DRiffusion 破解扩散模型采样延迟瓶颈

在生成式 AI 领域,扩散模型凭借其独特的迭代去噪机制,有效克服了传统模型在生成质量与多样性上的局限,已广泛应用于图像、视频、音频、分子设计等多个前沿方向。然而,这种「以时间换质量」的精炼过程通常需要数十甚至上百次迭代才能输出高保真结果,导致采样速度极慢、推理成本高昂,成为扩散模型迈向实时应用与规模化部署的核心瓶颈。
为破解采样慢的难题,研究者提出了整流流、蒸馏法等加速方案:前者通过优化去噪路径减少无效迭代,后者借助知识蒸馏将模型轻量化。但当采样步数被大幅压缩以追求高加速比时,两者都会显著牺牲生成质量(如细节丢失、纹理模糊),蒸馏法甚至可能严重降低结果多样性。
并行化技术虽提供了无需牺牲质量的补充思路,但现有系统级方法受限于模型架构(如 U-Net 、 Transformer),通用性较差;数学方法将扩散过程建模为微分方程并设计高效求解器,却常与主流框架兼容性不佳,且易偏离原始采样分布。这些方案均未能从根本上突破扩散模型固有的串行依赖——每一步去噪都依赖于上一步的输出。
针对这一困境,麻省理工学院的研究人员近期从根本问题出发,通过一项简洁的数学发现与创新的调度模式,首次证实了扩散框架中未被挖掘的内在并行性。基于此,研究人员提出了 DRiffusion 草稿-精炼(draft-and-refine)扩散模型,融合系统级方法与数学方法的优势,在不牺牲生成质量的前提下实现了显著加速,为兼顾扩散模型的高保真度与采样效率提供了全新的解决方案。
相关研究成果以「DRiffusion: Draft-and-Refine Process Parallelizes Diffusion Models with Ease」为题,已发表预印本于 arXiv 。
研究亮点:
* 首创 DRiffusion「草稿-精炼」并行框架,揭示扩散模型内在并行性
* 提供激进与保守两种加速模式,实现质量与速度的灵活折中
* 在多模型实测中实现 1.4~3.7 倍真实加速,生成质量近无损且全面优于现有方法

论文地址:
https://arxiv.org/abs/2603.25872
关注公众号,后台回复「DRiffusion」获取完整 PDF
MS‑COCO 数据集:包含 5 千图像与 2.5 万描述
实验采用 MS‑COCO 2017 验证集作为基准数据集,该数据集包含 5,000 张图像,每张配有 5 条描述文本。遵循常规做法,仅使用每张图像的第一条描述进行生成与图文对齐评估,以确保生成图像与参考文本一一对应,保障评估的严谨性。
考虑到传统指标对细粒度视觉偏好的敏感性不足,该研究进一步引入 PickScore 和人类偏好得分 v2.1(HPSv2.1)作为补充评估。效率评估方面,使用最多 4 块 NVIDIA V100 GPU,通过多次稳态运行测量平均采样延迟,报告相对于单 GPU 扩散模型基线的相对加速比,以及方法带来的额外内存开销。
对比基线选择了两种具有代表性的扩散模型加速方法:直接跳步(即减少采样步数)和 AsyncDiff(通过将子网络分布在不同设备上并执行异步采样实现去噪并行化)。为保证评估的统一性,研究人员基于 AsyncDiff 的官方实现,在相同测量设置下复现了其实验结果。
DRiffusion:通过草稿-精炼流程轻松实现扩散模型的并行化
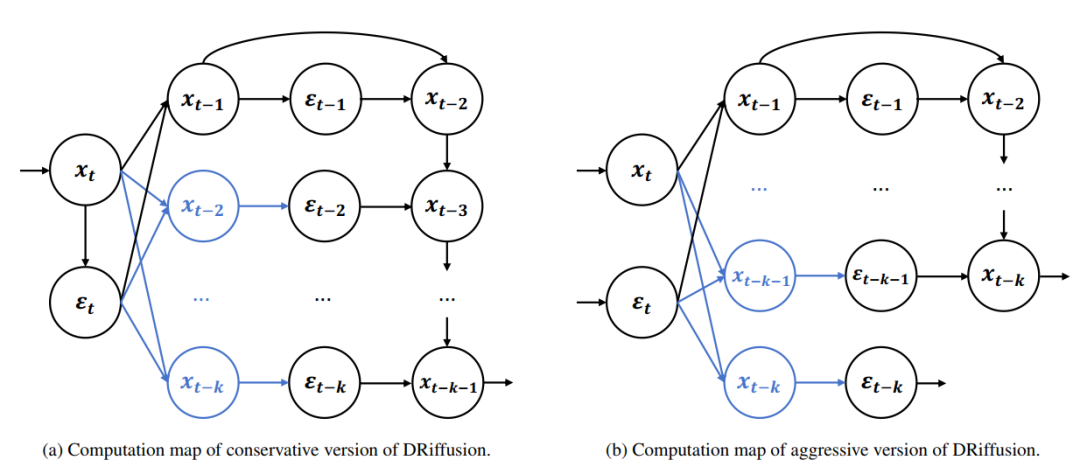
DRiffusion 的设计出发点是一个基础性问题:扩散模型能否同时计算多个时间步的噪声预测?在原始扩散模型中,由于每一步去噪都依赖上一步的输出状态,这一目标难以直接实现。跳跃转移(skip-step transition)为突破这一限制提供了新的视角:若能将跳步操作视为一个可独立调用的局部算子,则无需沿着完整轨迹逐步推进,即可直接构造中间状态,从而实现跨时间步的并行计算。
跳跃转移本身并非新概念。如下图所示,从连续时间的视角看,系统动力学本可以在更长的时间区间上进行积分,跳过中间步骤是一种自然操作。然而,现有扩散模型框架通常仅在全局层面利用这一自由度(例如通过重新选择时间步子序列),缺乏一个可局部调用、按需使用的跳步机制。

为此,DRiffusion 首先将跳跃转移算子化,即针对 DDPM 、 DDIM 以及基于常微分方程(ODE)的求解器等主流扩散模型,推导出统一的跳跃转移公式,使得任意两个扩散状态之间均可直接建立联系,无需重新制定全局时间步调度。
以 DDPM 为例,从当前状态 x_t 到未来状态 x_t-k 的跳跃转移存在闭式解;DDIM 基于边缘分布一致性同样可完成推广;而在 ODE 建模下,跳过中间步等价于直接采用更大的数值积分步长。该算子的引入显著提升了采样模式设计的灵活性,也为后续并行化奠定了基础。
基于跳跃转移算子,DRiffusion 的核心流程可概括为草稿生成与精炼两个阶段。在给定锚点时间步 t 的状态 x_t 后,首先利用跳跃转移并行生成后续 k 个时间步的状态,得到草稿估计值。这些草稿由于步长增大,精度略低于逐次迭代的结果,但整体仍与原始去噪轨迹保持一致。
随后,将这些草稿并行输入噪声预测器,获得对应的噪声估计值,再执行标准的去噪更新,对每个草稿进行精炼,最终得到精炼后的状态及其对应的噪声,作为下一轮迭代的锚点。
这一设计面临一个潜在问题:较大的跳跃步长可能因噪声预测的不完美而导致生成质量下降。已有研究确实指出这一风险,但本文的实验观察发现两个缓解因素。第一,轻微的感知质量下降并不等同于表征能力的显著降低,生成的图像或隐向量通常仍保留大部分底层语义与结构信息。第二,噪声预测器虽非完全精确,但其泛化能力足以将合理样本附近的邻域映射为合理的结果。基于这两点,DRiffusion 即使在采用较大步长时,仍能输出足够高质量的图像。
在具体实现上,DRiffusion 包含激进与保守两个版本。
如下图所示,激进版本将一次迭代中的多个噪声预测完全并行化,在忽略通信等微小开销的条件下,理想加速比可达 k 倍,即运行时间缩短为原来的 1/k 。
保守版本则先独立计算一次高精度的当前噪声(由精炼后的状态生成),再以此为基础复现激进版本的流程,并额外多推进一个时间步,理想加速比可达 2k+1 倍。两个版本的核心思路一致:以草稿换取并行计算能力,以精炼保障输出质量。
在 3 块 GPU 上实现了近 3 倍的实际加速
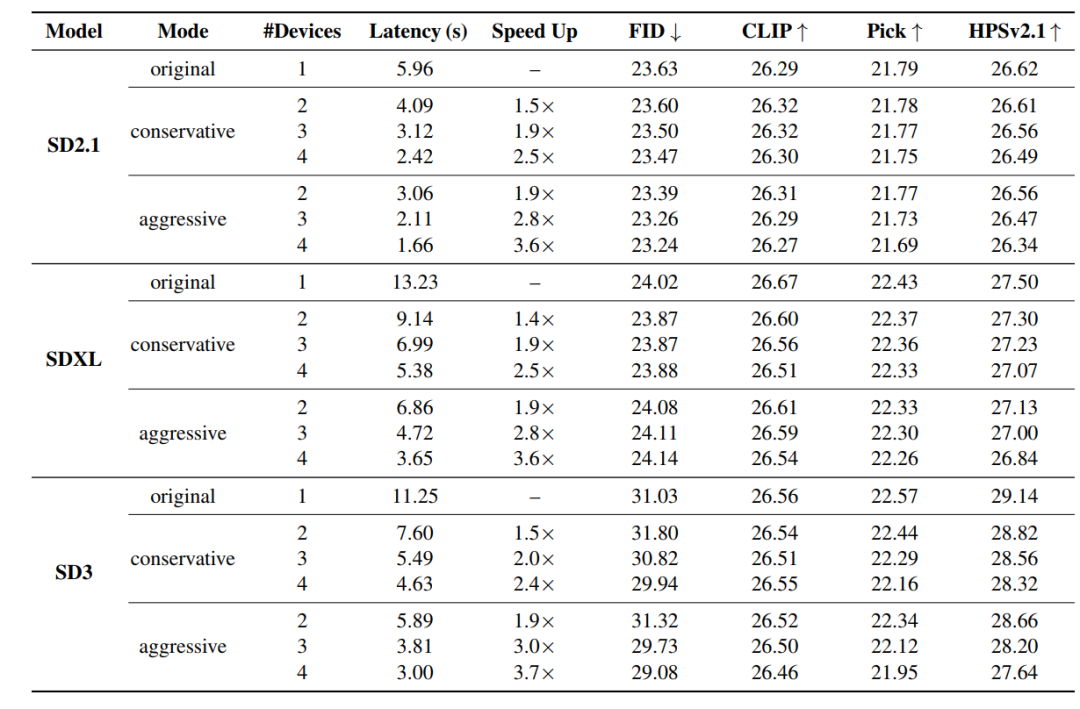
为验证 DRiffusion 的性能,实验覆盖了多种架构与规模的扩散模型,包括基于 U‑Net 的 Stable Diffusion 2.1(SD2.1)、基于 U‑Net 的 Stable Diffusion XL(SDXL),以及基于 Transformer 的流匹配模型 Stable Diffusion 3(SD3)。这种多模型覆盖的设置,既便于与现有方法进行公平对比,也能充分检验方法的通用性。
定性结果如下图所示,在高加速比下,DRiffusion 虽难以完全复现基线的逐像素输出,但始终能保持语义一致性,并有效保留细粒度细节(如木质纹理、猫咪胸前高光)。适度跳过部分噪声采样步骤后,加速版本有时反而能生成对比度更强、细节更锐利的图像(如猫眼反光)。激进加速(接近 4 倍)可能导致轻微质量折损,例如色彩过饱和或细微伪影,但整体仍与基线保持较高一致性。

定量结果如下表所示,所有配置下 FID 值与基线高度接近,CLIP 得分最大降幅不超过 0.16 。部分场景中 FID 略有提升,主要源于统计方差而非方法改进。补充的 PickScore 和 HPSv2.1 评估显示:平均下降分别为 0.17 和 0.43 。唯一例外是 SD3 在 4 设备激进模式下 HPSv2.1 下降 1.50,这是因为 SD3 默认采样步数仅 28 步,极端步长放大了近似误差。综合考虑四个指标的稳定性与显著的加速收益,该质量折损是可以接受的。
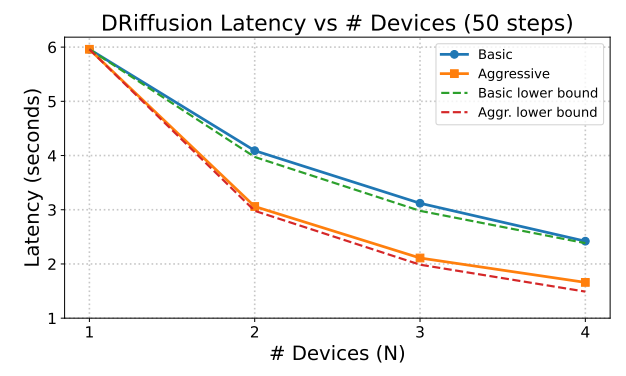
加速性能方面,实际加速比在 1.4~3.7 倍之间,每份样本的总计算量与原模型几乎相同。实验数据显示,激进模式的延迟缩放接近理论下界 O(1/N),保守模式则与 O(2/(N+1)) 高度吻合,证明 DRiffusion 实现了高效、可缩放的并行化。
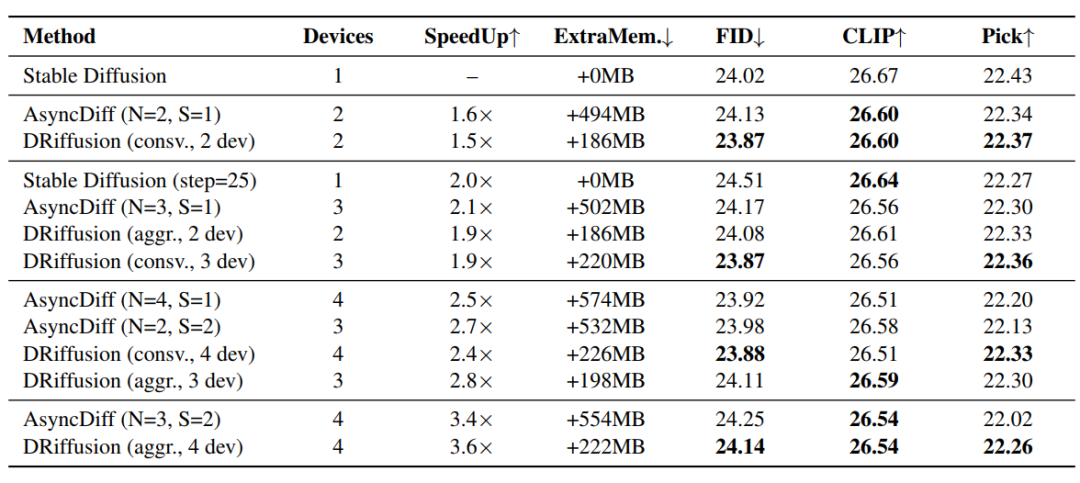
方法对比结果如下表所示,在所有加速比组别中,DRiffusion 的生成质量均优于 AsyncDiff 和简单跳步基线。采用对加速更敏感的 PickScore 作为核心指标,DRiffusion 将性能下降差距平均缩小 48.6%,4 设备下最大缩小 58.5% 。加速效果与设备数量呈近线性关系,相近设备数下加速比持平或略优于 AsyncDiff 。
内存效率优势更为突出:AsyncDiff 额外内存最高达 574MB 且随设备数增加,而 DRiffusion 仅引入 186~226MB 的稳定开销。相比 SDXL 基线约 13GB 的内存需求,这一开销可忽略不计。在批次大小为 5 时,AsyncDiff 在 32GB 节点上出现内存不足异常,DRiffusion 则运行正常。原因在于 DRiffusion 仅修改采样迭代过程,与模型结构和核心计算解耦。
综上,DRiffusion 在保持生成质量与细粒度细节的同时,在 3 块 GPU 上实现近 3 倍加速,显著提升了推理速度,将简洁的理论特性与实用的并行实现相结合,取得了高质量且稳定的实验结果。
扩散模型并行化提速
扩散模型并行化已成为全球学术界与企业界共同追逐的核心热点。在学术界,多所顶尖机构围绕这一方向取得突破。麻省理工学院与香港大学联合提出的 Fast-dLLM,在不重新训练模型的前提下,实现了扩散大规模语言模型的 27.6 倍端到端加速(长文本生成任务),准确率损失控制在 2% 以内。
论文名称:FAST-DLLM V2: Efficient Block-Diffusion LLM
论文链接:https://arxiv.org/pdf/2509.26328
伯克利大学研发的 StreamDiffusionV2 流式系统,针对视频扩散模型整合了 SLO‑aware 批处理调度器与运动感知噪声控制器,在多 GPU 环境下将视频生成帧率提升至 58 FPS,突破了实时生成的算力瓶颈。
论文名称: StreamDiffusionV2: A Streaming System for Dynamic and Interactive Video Generation
论文链接:https://arxiv.org/abs/2511.07399
在企业界,英伟达将并行化技术深度融入硬件与软件生态,通过优化计算路径与多设备协同,显著提升扩散模型推理速度,降低图像与视频生成场景的算力成本。 Stability AI 则在 Stable Diffusion 系列模型中探索并行采样策略,通过优化批处理参数与启用 DDIM 、 PLMS 等支持并行处理的采样器,在保持生成质量的前提下将图像生成效率提升 3‑5 倍。
综上,学术界与产业界的共同发力已使扩散模型并行化成为技术突破的热点。 DRiffusion 作为其中的典型方案,验证了挖掘内在并行性的可行性与高效性。未来,随着硬件与算法的深度协同,扩散模型有望在保持高保真度的同时,实现真正实时的生成体验,为更广泛的 AI 应用落地扫清效率障碍。








