Command Palette
Search for a command to run...
不共享数据,也能联合训练!UCL 团队用联邦学习重塑血液形态学检查

血液形态学检查是临床诊断血液疾病的重要环节,通过观察外周血涂片(PBS)或骨髓穿刺(BMA)中的细胞形态,医生可以判断白血病、贫血、感染及遗传性血液疾病的类型。然而,这一过程不仅劳动强度大,而且高度依赖经验丰富的专业人员。尤其在低收入和中等收入国家(LMICs),技能专家稀缺,使得快速、可靠且可扩展的血液学诊断成为急需解决的问题。
近年来,人工智能和深度学习的发展为血液形态分析提供了新的解决方案。 AI 模型能够自动识别不同类型的白细胞,并辅助医生进行快速诊断。研究表明,深度学习在自动化血液学诊断中具备显著潜力,但现实应用中仍面临重要挑战——模型训练对数据的依赖性极强,而临床数据通常分布在不同医院,且存在染色方法差异、成像设备差异以及少数罕见细胞类型的问题。这种数据异质性会导致模型在新机构或新患者群体中泛化能力下降。
更重要的是,医疗数据涉及患者隐私,跨机构共享数据受到严格限制。传统集中式训练方法通常需要汇集大量敏感医疗数据并依赖高性能计算资源,在很多机构难以实现。如何在保护隐私的前提下,实现多机构协作训练,成为医疗 AI 领域亟待解决的关键问题。
在此背景下,来自伦敦大学学院(UCL)计算机科学系的研究团队提出了一种用于白细胞形态分析的联邦学习框架,使各机构能够在不交换训练数据的情况下进行协同训练。利用来自多个临床站点的血液涂片,该联邦模型在保证完全数据隐私的同时,学习到稳健且域不变的特征表示。在卷积网络和基于 Transformer 的架构上的评估表明,与集中式训练相比,联邦训练在跨站点性能和对未知机构的泛化能力上表现出色。
相关研究成果以「MORPHFED: Federated Learning for Cross-institutional Blood Morphology Analysis」为题,已发布预印本于 arXiv 。
研究亮点:
* 与集中式训练相比,联邦训练在跨站点性能和对未知机构的泛化能力上表现出色
* 该方法能够在不共享原始数据的情况下,实现跨机构模型协作训练,为资源有限的医疗环境提供了一种可行的解决方案。

论文地址:
https://arxiv.org/abs/2601.04121
关注公众号,后台回复「MORPHFED」获取完整 PDF
数据集:反映现实临床中的异质性
本研究使用了来自多个医疗机构的血液涂片数据,确保训练数据既能覆盖不同细胞类型,又能反映现实临床中的异质性。
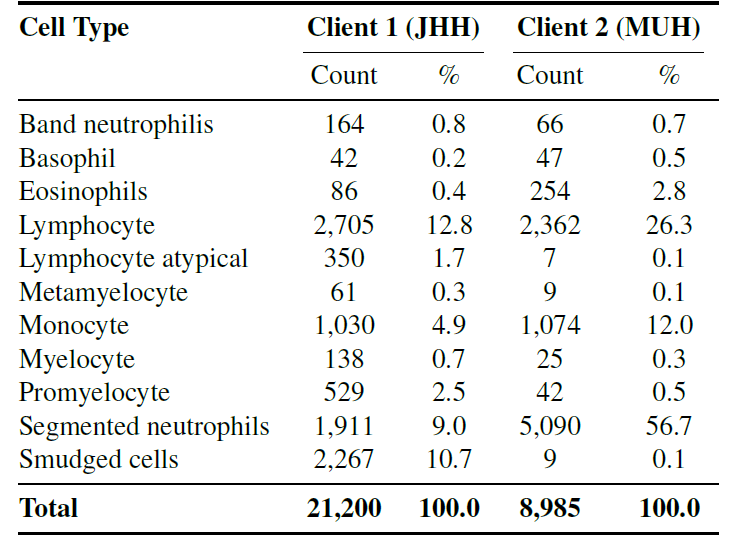
具体而言,研究使用了来自两个中心的独立数据集,这两个数据集包含 11 种共同细胞类型(如中性粒细胞、嗜酸性粒细胞、嗜碱性粒细胞、早幼粒细胞等),保证分类目标一致,同时保留了染色和成像的差异,用于测试联邦学习在真实异质环境下的泛化能力。
下图显示了不同客户端的类别分布情况
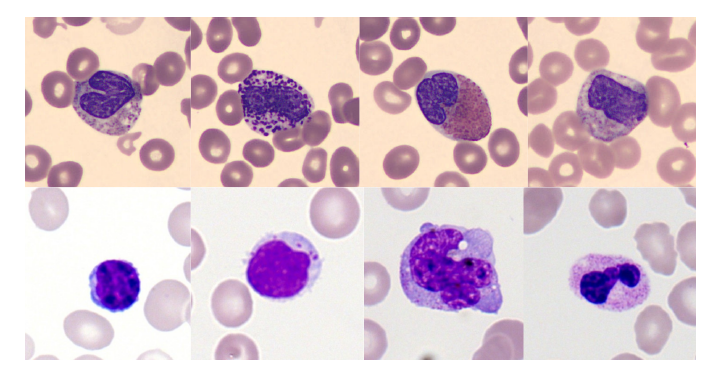
下图则展示了两个训练数据集中部分细胞类型的示例,可以明显观察到染色风格的差异,这正是模型需要克服的数据偏移。
此外,为了独立评估模型在完全未见过机构数据上的表现,研究保留了来自巴塞罗那临床医院(Client 3)的 12,992 张图像,作为外部验证集。该数据集具有不同的成像设备、染色方法及患者群体,用于测试模型在真实跨机构场景下的泛化能力。
两类深度学习架构和四种联邦聚合策略
本研究采用了两类深度学习架构:
* ResNet-34:基于卷积神经网络(CNN)的经典架构,使用 ImageNet 预训练权重。
* DINOv2-Small:基于自监督视觉 Transformer(Vision Transformer, ViT),通过自监督学习捕捉图像全局特征。
训练遵循统一协议:联邦模型进行了 5 轮全局通信,每轮每个客户端进行 5 个本地训练周期,总计 25 个训练周期;集中式基线模型使用 25 个训练周期,并进行 4 折交叉验证,如下图所示。数据划分为 60% 训练集、 13.33% 验证集、 13.33% 本地测试集和 13.33% 全局测试集;所有图像均调整为 224×224 像素,并采用保守的数据增强策略(平移 ±10%,旋转 ±5°)以保持诊断形态信息。
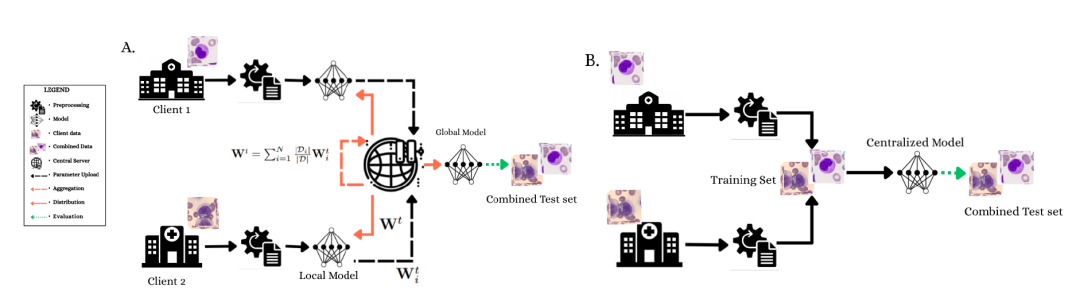
(A) 联邦学习框架展示了隐私保护的协作训练过程,其中 Client 1 和 Client 2 在本地进行模型训练,参数在中央服务器进行聚合。
(B) 集中式训练范式,完全访问合并数据集,并使用 4 折交叉验证。
两种架构均采用选择性微调:ResNet-34 冻结早期层,仅训练最后三个残差块(约 11M 参数);DINOv2-Small 冻结前 8 个 Transformer 块(0-7),训练第 8 至 11 块(约 9M 参数)。 Client 3 的数据在所有训练过程中保持隔离,仅用于评估最终模型对新机构数据的泛化能力。
在联邦学习框架中,中央服务器负责协调训练并分发全局参数,但不访问原始数据;客户端在本地训练,仅返回参数更新。
研究采用了四种联邦聚合策略:
* FedAvg:计算客户端参数的加权平均,对极端类别分布敏感。
* FedMedian:逐坐标取中值,对异常客户端和拜占庭错误具有稳健性,但可能抑制少数类信号。
* FedProx:在本地目标函数中加入近端约束,增强非 IID 数据下的收敛稳定性。
* FedOpt:在聚合梯度上使用自适应优化(Adam),动态调整学习率以应对客户端异质性,并加快收敛。
此外,为解决严重类别不平衡问题,研究结合了 Focal Loss 、加权随机采样以及梯度累积策略,保证少数类细胞的训练信号不被忽略。梯度裁剪(最大范数 1.0)确保训练过程稳定收敛。
模型性能通过平衡准确率(balanced accuracy)进行评估,重点关注跨机构泛化能力,以测试模型在遇到不同成像协议和患者群体的数据时的稳健性。
联邦训练在跨站点性能和对未知机构的泛化能力上表现出色
为了验证联邦学习框架的有效性,研究人员分别进行了联合测试集评估和外部分布数据泛化评估。
①联合测试集评估
模型在包含两个客户端数据的联合数据集上进行评估,结果如下表所示,不同聚合方法在不同架构上的表现存在显著差异。
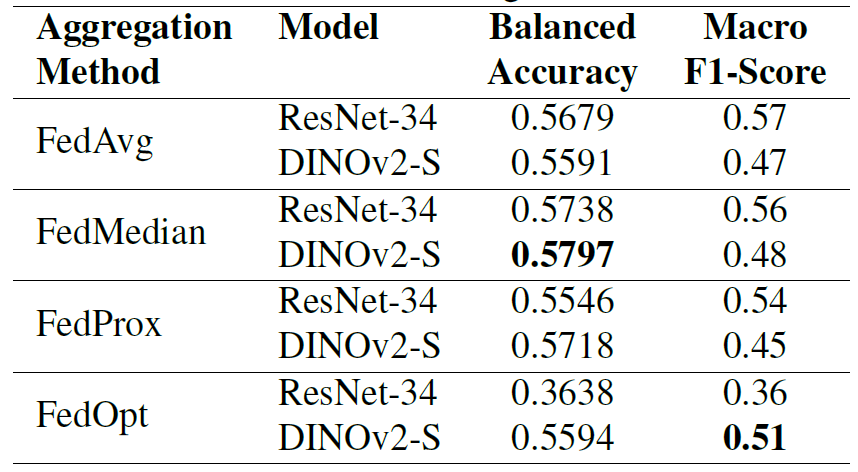
值得注意的是,FedOpt 表现出极大的波动性:在 ResNet-34 上表现极差(平衡准确率 0.3638),而在 DINOv2-S 上保持了有竞争力的性能(平衡准确率 0.5594);相比之下,FedAvg 和 FedProx 在两种模型上表现相对稳定;FedMedian 在两种架构上表现最一致,分别达到 ResNet-34 的平衡准确率 0.5738 和 DINOv2-S 的 0.5797 。
结果表明,联邦学习显著提升了性能,相比仅使用单个机构数据训练的模型(58% vs 52% 平衡准确率),证明了无需共享数据即可进行协同训练的优势。尽管联邦模型的性能略低于对所有数据进行集中训练的模型,但它们在保持完整数据隐私的同时,仍能达到可比精度。
②外部分布数据泛化评估
对来自巴塞罗那的 Client 3 外部验证数据集的评估显示,两种联邦方法(FedMedian 和 FedOpt)在完全未见过的机构数据上的泛化能力均优于集中式训练(平衡准确率 67% vs 64%),如下表。这表明,在联邦训练过程中接触到异质的机构特征(如成像设备、患者群体和染色方法)有助于模型学习更具泛化性的形态特征。
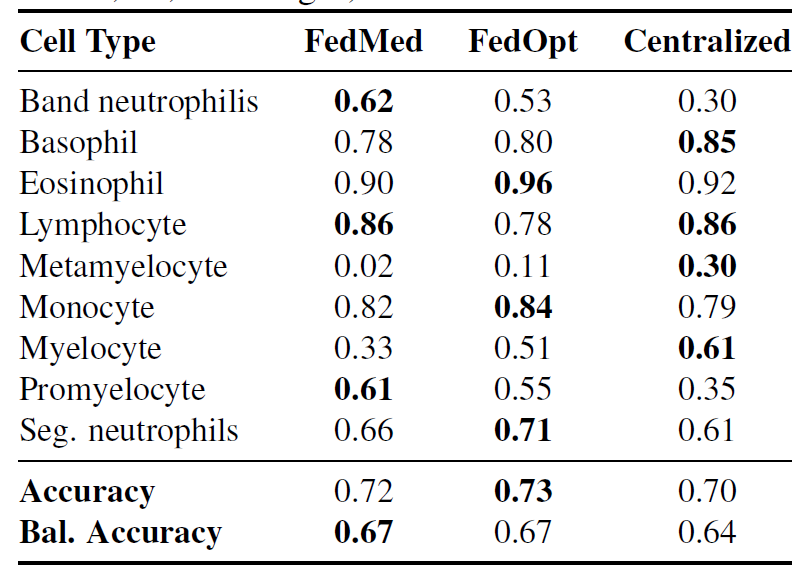
FedMedian 在少数类细胞上表现出特别显著的提升:带状中性粒细胞(Band neutrophils)F1: 0.62 vs 集中式 0.30(提升 107%),早幼粒细胞(Promyelocytes)F1: 0.61 vs 0.35(提升 74%),显示在不同机构协议下诊断相关特征得到了有效保留。然而,对中幼粒细胞(Metamyelocytes)的识别对所有方法仍然具有挑战性(F1: 0.02-0.30),反映出从极其罕见类别学习稳健表征的根本困难
③架构-聚合策略相互作用规律
研究人员还进一步识别出关键的架构-聚合策略相互作用规律:FedMedian 提供跨架构稳健性,但对罕见类别不利;FedOpt 在少数类细胞信号保真上表现更好,但对架构敏感。 DINOv2-S 的预训练 Transformer 架构对非 IID 数据分布表现出更高鲁棒性,而 ResNet-34 对梯度冲突更敏感。
总体而言,这些发现将联邦学习定位为稳健、隐私保护且具泛化能力的血液学影像分析框架。
联邦学习成为破解医疗「数据孤岛」的关键
联邦学习是一种面向分布式数据环境的协同机器学习范式,其核心理念是在不集中原始数据的前提下完成模型联合训练。在联邦学习框架中,各参与机构(如医院、实验室或研究中心)在本地进行模型训练,仅向中央服务器上传模型参数或梯度更新,服务器负责对这些更新进行聚合并生成全局模型,再将模型下发至各节点继续迭代训练。通过这种「数据不出域、模型可协作」的机制,联邦学习在实现跨机构知识共享的同时,能够有效保护数据隐私并满足严格的数据合规要求。
过去几年,已有不少机构在推进如何用联邦学习赋能医疗行业,典型的比如端到端人工智能生物技术公司 Owkin——该公司曾获得法国 20 家值得关注的人工智能初创企业、 2023 年最值得关注的医疗和技术初创公司之一、最佳医疗技术大奖、福布斯 AI 50 强。
让 AI 技术在多模态患者数据中识别不同的生物标志物,并对患者进行亚群分类,将每类患者与最佳治疗靶点匹配,推动靶点药物研发、优化疾病诊断工具,实现真正意义上的个性化医疗,是 Owkin 公司正在走的路。而实现以上目标的关键在于——如何既能进行数据共享,又能保证患者的数据隐私?针对此,Owkin 采用联邦学习来解决。为了推动相关技术的普及,Owkin 开源了联邦学习软件 Substra ,可用于临床研究、药物研发等。
开源地址:
而在医疗影像领域,联邦学习同样被视为破解「数据孤岛」和隐私合规难题的关键技术路径。医疗影像数据高度敏感,涉及患者隐私与严格监管(如 GDPR 、 HIPAA 等),传统集中式训练往往面临伦理审批、法律风险和数据跨境传输限制等现实障碍。联邦学习使得不同医院能够在不共享原始影像数据的情况下联合训练模型,从而提升模型对不同设备、不同染色协议、不同患者群体的泛化能力。已有研究表明,联邦学习在放射影像、数字病理、超声影像等领域可实现接近甚至超过集中式训练的跨机构泛化性能,尤其在外部数据测试中表现出更强的鲁棒性。
从更宏观的角度看,联邦学习所代表的「分布式协同智能」模式,正在成为未来医疗 AI 规模化部署的重要基础设施。它不仅为隐私保护型医学大模型的训练提供了可行路径,也为跨机构临床决策支持系统和全球协作医学研究平台奠定了技术基础。在血液形态分析等细分领域,联邦学习有望推动 AI 从单机构实验室应用走向跨区域、跨体系的临床级智能诊断服务,为精准医学和数字化医疗提供关键支撑。
参考文献:
1.https://arxiv.org/abs/2601.04121
2.https://mp.weixin.qq.com/s/Lf6N7EUHlhibLNc9YXWjTQ








