Command Palette
Search for a command to run...
含 284 个数据集,覆盖 18 项临床任务,上海 AI Lab 等发布多模态医疗基准 GMAI-MMBench

「有这样一台智能医疗设备,患者只需躺在智能医疗设备上便可完成从扫描、诊断、治疗、修复的全过程,实现健康的重启」。这是 2013 年上映的科幻电影「极乐空间」中的一个情节。

如今,随着人工智能技术的飞速发展,科幻电影中展示的医疗场景将有望成为现实。面向医疗领域,大型视觉语言模型 (LVLMs) 能够处理成像、文本甚至生理信号等多种数据类型,如 DeepSeek-VL 、 GPT-4V 、 Claude3-Opus 、 LLaVA-Med 、 MedDr 、 DeepDR-LLM 等,在疾病诊断和治疗中彰显出巨大的发展潜力。
然而,在 LVLMs 真正投入到临床实践之前,还需要建立基准测试进行模型的有效性评估。但目前的基准测试通常基于特定的学术文献,且主要集中在单一领域,缺乏不同的感知粒度,因此难以全面地评估 LVLMs 在真实临床场景中的有效性和表现。
针对于此,上海人工智能实验室联合华盛顿大学、莫纳什大学、华东师范大学等多家科研单位提出了 GMAI-MMBench 基准。 GMAI-MMBench 由来自全球的 284 个下游任务数据集构建而成,涵盖 38 种医学影像模态、 18 项临床相关任务、 18 个科室以及视觉问题解答 (VQA) 格式的 4 种感知粒度,具有完善的数据结构分类和多感知粒度。
相关研究以「GMAI-MMBench: A Comprehensive Multimodal Evaluation Benchmark Towards General Medical AI」为题,入选 NeurIPS 2024 Dataset Benchmark,并在 arXiv 发表预印本。

论文地址:
https://arxiv.org/abs/2408.03361v7
HyperAI 超神经官网现已上线「GMAI-MMBench 医疗多模态评估基准数据集」,一键即可下载!
数据集下载地址:
https://go.hyper.ai/xxy3w
GMAI-MMBench :迄今为止最全面的且开源的通用医疗 AI 基准
GMAI-MMBench 的整体构建过程可以分为 3 个主要步骤:
首先,研究人员从全球公开数据集和医院数据中搜索了数百个数据集,经过筛选、统一图像格式和标准化标签表达后,保留了 284 个高质量标签的数据集。
值得一提的是,这 284 个数据集涵盖了 2D 检测、 2D 分类和 2D/3D 分割等多种医学影像任务,并由专业医生标注,确保了医学影像任务的多样性以及高度的临床相关性和准确性。
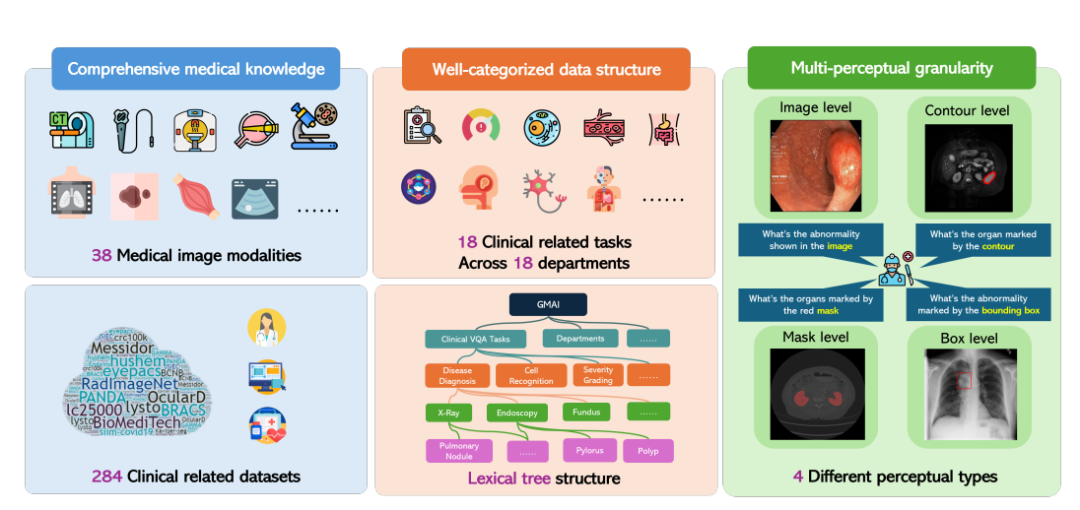
紧接着,研究人员将所有标签分类为 18 个临床 VQA 任务和 18 个临床科室,使其可以全面评估 LVLMs 在各个方面的优劣,方便模型开发者和有特定需求的用户。
具体来说,研究人员设计了一个名为词汇树 (lexical tree) 结构的分类系统,将所有病例分为 18 项临床 VQA 任务、 18 个科室、 38 种模态等。「临床 VQA 任务」、「科室」、「模态」是可用于检索所需评估病例的词汇。例如,肿瘤科可以选择与肿瘤学相关的病例来评估 LVLMs 在肿瘤学任务中的表现,从而极大地提高了针对特定需求的灵活性和易用性。
最后,研究人员根据每个标签对应的问题和选项池生成了问答对。每个问题必须包含图像模态、任务提示和对应的标注粒度信息。最终的基准通过额外的验证和人工筛选获得。
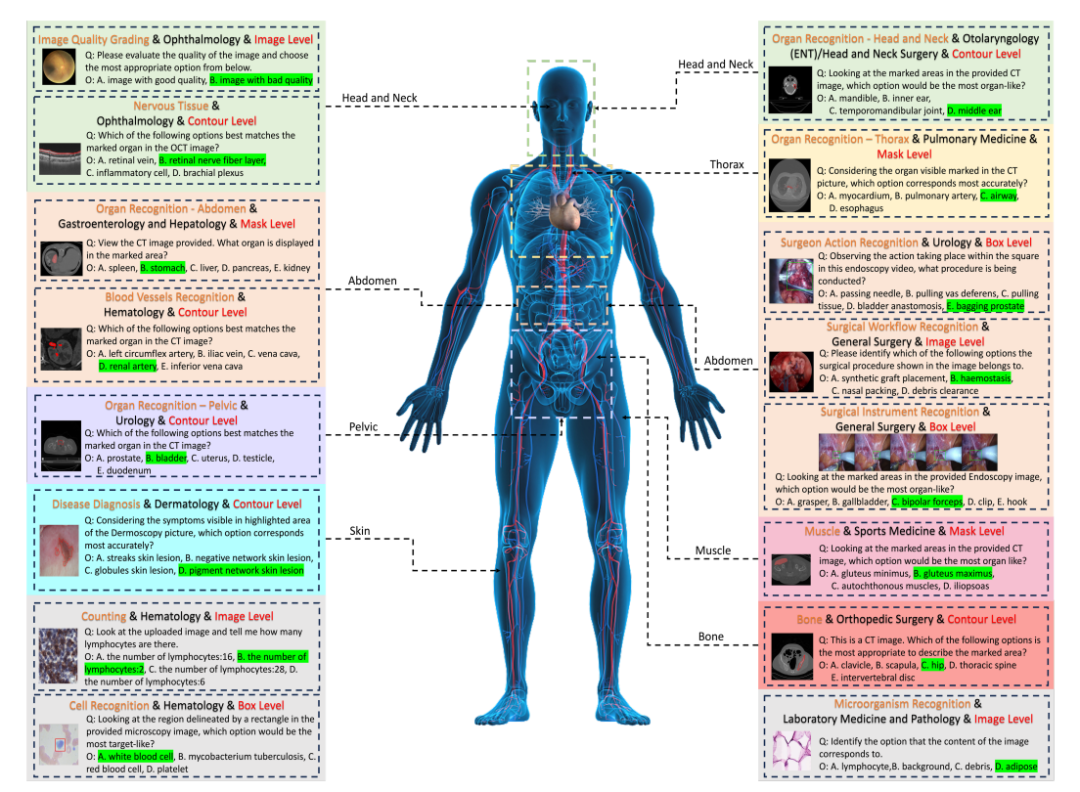
50 个模型评估,谁能在 GMAI-MMBench 基准测试中更胜一筹
为了进一步推动 AI 在医疗领域的临床应用,研究人员在 GMAI-MMBench 上评估了 44 个开源的 LVLMs(其中包括 38 个通用模型和 6 个医学特定模型),以及商用闭源 LVLMs,如 GPT-4o 、 GPT-4V 、 Claude3-Opus 、 Gemini 1.0 、 Gemini 1.5 和 Qwen-VL-Max 。
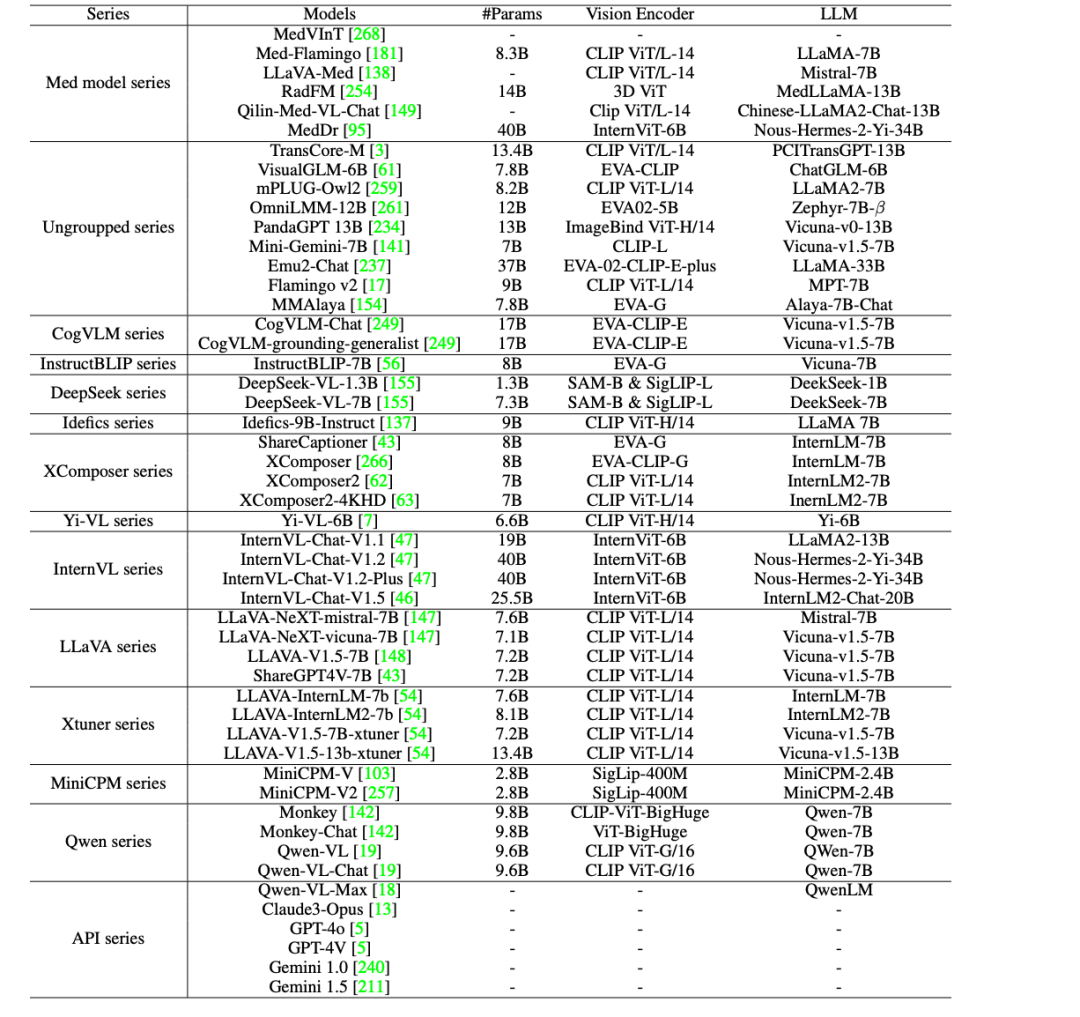
结果发现,当前的 LVLMs 中仍有 5 大不足之处,具体如下:
* 临床应用仍有进步空间:即使是性能最优的模型 GPT-4o,虽达到了临床实际应用的要求,但准确率也仅为 53.96%,这表明当前的 LVLMs 在处理医学专业问题方面存在不足,仍有巨大进步空间。
* 开源模型与商业模型的对比:MedDr 和 DeepSeek-VL-7B 等开源 LVLM 的准确率约为 44%,在某些任务上优于商业模型 Claude3-Opus 和 Qwen-VL-Max,并且与 Gemini 1.5 和 GPT-4V 的表现相当。然而,与表现最佳的 GPT-4o 相比,仍具有明显的性能差距。
* 大多数医学专用模型难以达到通用 LVLMs 的一般性能水平(约 30% 的准确率),但 MedDr 除外,其准确率达到 43.69% 。
* 大多数 LVLMs 在不同的临床 VQA 任务、科室和感知粒度上表现不均衡。特别是在不同感知粒度的实验中,框选层级 (box-level) 的注释准确率始终最低,甚至低于图像层级的注释。
* 导致性能瓶颈的主要因素包括感知错误(如图像内容识别错误)、缺乏医学领域知识、无关的回答内容以及由于安全协议拒绝回答问题。
综上,这些评估结果表明,当前 LVLMs 在医疗应用中的性能还有很大提升空间,需要进一步优化以满足实际临床需求。
集聚医学开源数据集,助力智慧医疗纵深发展
在医疗领域,高质量的开源数据集已经成为推动医疗研究和临床实践进步的重要驱动力。为此,HyperAI 超神经为大家精选了部分医学相关的数据集,简要介绍如下:
PubMedVision 大规模医学 VQA 数据集
PubMedVision 是一个大规模且高质量的医疗多模态数据集,由深圳市大数据研究院、香港中文大学和 National Health Data Institute 的研究团队于 2024 年创建,包含 130 万个医学 VQA 样本。
为了提高图文数据的对齐度,研究团队采用视觉大模型 (GPT-4V) 对图片进行重新描述,并构建了 10 个场景的对话,将图文数据改写为问答形式,增强了医疗视觉知识的学习。
直接使用:https://go.hyper.ai/ewHNg
MMedC 大规模多语言医疗语料库
MMedC 是一个由上海交通大学人工智能学院智慧医疗团队于 2024 年构建的多语言医疗语料库,它包含了约 255 亿个 tokens,涵盖了 6 种主要语言:英语、中文、日语、法语、俄语和西班牙语。
研究团队还开源了多语言医疗基座模型 MMed-Llama 3,该模型在多项基准测试中表现卓越,显著超越了现有的开源模型,特别适用于医学垂直领域的定制微调。
直接使用:https://go.hyper.ai/xpgdM
MedCalc-Bench 医疗计算数据集
MedCalc-Bench 是一个专门用于评估大语言模型 (LLMs) 在医疗计算能力方面的数据集,由美国国立卫生研究院国家医学图书馆和弗吉尼亚大学等 9 个机构于 2024 年共同发布,这个数据集包含了 10,055 个训练实例和 1,047 个测试实例,涵盖了 55 种不同的计算任务。
直接使用:https://go.hyper.ai/XHitC
OmniMedVQA 大规模医学 VQA 评测数据集
OmniMedVQA 是一个专注于医疗领域的大型视觉问答 (Visual Question Answering, VQA) 评测数据集。这个数据集由香港大学与上海人工智能实验室于 2024 年联合推出,包含 118,010 张不同的图片,涵盖 12 种不同的模态,涉及超过 20 个人体不同的器官和部位,且所有图像都来自真实的医疗场景,旨在为医学多模态大模型的发展提供评测基准。
直接使用:https://go.hyper.ai/1tvEH
MedMNIST 医疗图像数据集
MedMNIST 由上海交通大学于 2020 年 10 月 28 日发布,是一个包含 10 个医学公开数据集的集合,共计包含 45 万张 28*28 的医疗多模态图片数据,涵盖了不同的数据模式,可用于解决医学图像分析相关问题。
直接使用:https://go.hyper.ai/aq7Lp
以上就是 HyperAI 超神经本期为大家推荐的数据集,如果大家看到优质的数据集资源,也欢迎留言或投稿告诉我们哦!
更多高质量数据集下载:https://go.hyper.ai/jJTaU
参考资料:
https://mp.weixin.qq.com/s/vMWNQ-sIABocgScnrMW0GA









