Command Palette
Search for a command to run...
催化能力提高 3.5 倍!中科院团队基于扩散模型,开发 P450 酶从头设计方法 P450Diffusion

细胞色素 P450 酶几乎于所有生物体中普遍存在,在生命成长和发育的各种代谢过程中发挥着重要作用。作为自然界中最通用的生物催化剂,P450 酶不仅能催化超过 95% 已报道的氧化还原反应,而且能在温和条件下选择性氧化惰性碳-氢键,被誉为工业应用中的「万能催化剂」。
如今,定向进化已广泛应用于设计具有更好性能的新型 P450 酶,然而,传统方法通常需要多轮随机诱变和高通量筛选,因此无论是执行实际实验还是通过计算机模拟计算,都很难详尽地探索潜在的蛋白质空间。
尽管深度学习在蛋白质结构预测方面取得了显著成就,但理想的功能设计仍然是一项巨大挑战——在进行蛋白质功能设计时,很难收集到足够的高质量功能数据,并训练一个复杂的模型以创建具有所需功能的序列,因此,将知识驱动的技术与强大的深度学习模型相结合,以扩展自然蛋白质序列空间,可能是设计新型 P450 酶的适当方法。
近日,中国科学院天津工业生物技术研究所江会锋、程健等研究员,通过解析 P450 酶黄酮 6-羟化酶 (F6H) 的口袋设计原则,开发了基于扩散模型和口袋设计原则的 P450 酶从头设计方法 P450Diffusion,相关研究以「Cytochrome P450 Enzyme Design by Constraining the Catalytic Pocket in a Diffusion Model」为题发表在 Research 上。
该研究基于 P450Diffusion 生成了比自然界 P450 酶活性更好、稳定性更高的新酶,相较于天然黄酮 6 位羟化酶,新酶的催化能力提升了 1.3 至 3.5 倍。
研究亮点:
* 该研究剖析了 P450 酶进化过程中新功能的起源机制,提出了 P450 酶底物结合的「三点固定原则」
* 通过 P450Diffusion 生成的新酶催化能力提升了 1.3 至 3.5 倍
* 该研究在深度学习扩散模型的框架下,为新功能 P450 酶设计提供了新思路。未来,这一方法有望在生物工程和工业催化等领域发挥作用,并推动新型酶的开发和应用。

论文地址:
https://spj.science.org/doi/10.34133/research.0413
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
数据集:收集数据集并编码
为了构建 P450Diffusion,研究人员从已发表的 P450 酶数据库和公共数据库中,筛选并分析了所有潜在的 P450 酶,过滤掉长度大于 560 的序列,得到了 226,509 个序列作为训练数据集。
随后,研究人员对训练数据集进行编码,蛋白质序列中的每个氨基酸被编码为一个 8 维向量,每批蛋白质序列被编码为一个 64×1×560×8 向量——其中,64 是 Batch 大小,等于训练数据中的样本数;1 表示通道大小;560 表示蛋白质序列的最大长度;8 表示蛋白质序列中每个氨基酸的 VHSE8 编码向量。
如果蛋白质序列短于 560,研究人员会添加间隙,直到达到 560 的长度。在这种情况下,其分配一个由 8 个零组成的向量作为间隙的编码。
模型架构:P450 酶的从头设计方法 P450Diffusion
研究人员以来自灯盏花的一个黄酮 6-羟化酶 (CYP706X1) 为例,该酶属于 CYP706X 亚家族,在灯盏花素生物合成途径中将芹菜素转化为灯盏花素。
首先,研究人员通过祖先序列重建、回复突变试验、渐进式正向积累和晶体学分析,确定了构成催化口袋的创始残基,其负责 P450 酶基因功能的创新;其次,研究人员通过深入的结构分析,阐明了功能创新的催化口袋的设计原理;最后,其将催化口袋设计原理与在图像生成中表现出色的去噪扩散概率模型相结合,设计了人工 P450 酶生成模型 P450Diffusion 。
第一步:确定构成催化口袋的创始残基,负责 P450 酶基因功能的创新。
在已鉴定的 CYP706 家族 P450 酶中,仅 CYP706X 亚家族 P450 酶能够催化黄酮类底物,这表明 P450 酶黄酮 6-羟化酶 (F6H) 的功能可能是在 CYP706X 亚家族的祖先中从头创新的。
为了阐明形成具有 F6H 功能的催化口袋的分子机制,研究人员提出,分析无功能性 ancXY (CYP706X 和 CYP706Y 亚家族的共同祖先) 和功能性 ancX (CYP706X 亚家族共同祖先) 催化口袋之间,残基组成的变化。在距活性中心 8 Å 范围内,48 个残基中有 16 个不同。
如下图 A 所示,ancX 和 ancXY 的残基分别染成青色和洋红色;而当这 16 个残基全部被替换为 ancX 中相应的残基时,突变体(称为 ancXY-16)获得了 F6H 功能,如下图 B 所示。
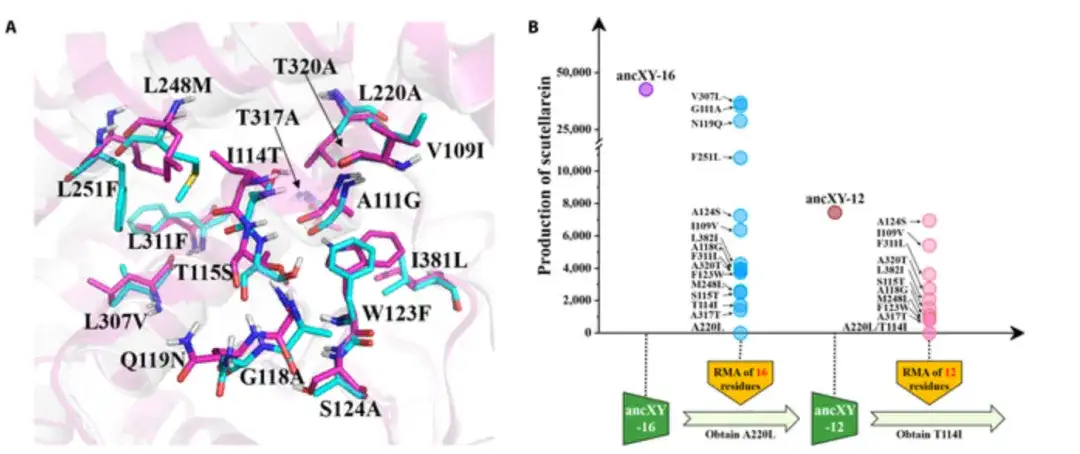
鉴于催化口袋中残基在三维空间内的位置不同,并非所有残基都对底物识别和结合有显著贡献,研究人员尝试通过回复突变试验(RMA:通过将 ancXY-16 催化口袋中每个残基回复为祖先类型来评估其突变效应)找出催化口袋中的创始残基。为了更快地识别创始残基,研究人员还采用渐进式前向积累 (PFA) 策略,逐步将重要的突变添加到 ancXY 中,直至突变体获得 F6H 功能。
最终,实验发现 5 个氨基酸的突变 (L220A/I114T/T317A/W123F/L248M) 在 F6H 从 ancXY 到 ancX 的功能创新过程中起着奠基者的作用(创始残基)。
第二步:阐明功能创新的催化口袋的设计原理。
通过深入分析 ancXY-5 中芹菜素结合模型,研究人员进一步解读了 5 个创始残基参与功能创新的潜在机制。基于 5 个创始残基的突变,催化口袋似乎遵循「三点固定」原则。
「三点固定」指的是与芹菜素分子中三个枢纽的关键相互作用,包括:芹菜素分子中的 4’-OH (第一个枢纽) 由 T114 提供的氢键固定,芹菜素的「B」环 (第二个枢纽) 由 F123 和 M248 的 π 堆积相互作用固定,芹菜素的 7-OH (第三个枢纽) 通过与 CpdI 铁-氧基的氢键固定。
该模型将底物芹菜素保持在一个接近反应的构象 (NAC),维持芹菜素反应位点与 CpdI 铁-氧基之间的相对方向处于有利的距离和角度 (3.6 Å和 155°),从而在催化过程中启动芹菜素的 6-羟基化反应。
研究人员提出,「三点固定」可以作为 F6H 自然功能创新的催化口袋设计原则,这也为设计具有期望功能的 P450 酶提供了新思路。
第三步:将催化口袋设计原理与在图像生成中表现出色的去噪扩散概率模型相结合,设计人工 P450 酶生成模型 P450Diffusion 。
研究人员将扩散模型与 F6H 催化口袋的设计原理相结合,从头设计具有所需功能的 P450 酶,如下图所示。新 P450 酶的设计过程包括 P450Diffusion 模型构建 (Model construction) 、序列生成 (Sequence generation) 、筛选和实验验证 (Screening and experimental verification) 。
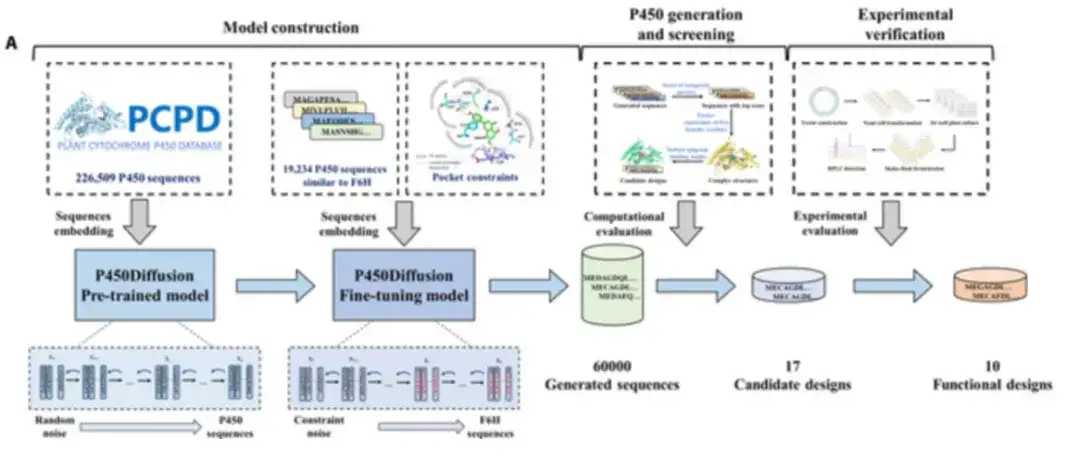
P450Diffusion 主要包含两个模型,即预训练 (pre-trained model) 和微调扩散模型 (fine-tuning model) 。
首先,收集 226,509 个天然 P450 酶序列,训练预训练的 P450 序列扩散模型。
该预训练模型由两个子过程组成:一个正向扩散子过程 (forward diffusion subprocess),逐渐将高斯噪声添加到 P450 酶序列的表示中,直到变为随机噪声;一个反向生成子过程 (reverse generation subprocess),从随机噪声开始,逐渐对 P450 酶序列的表示进行去噪,以生成新的 P450 序列。经过 150,547 轮训练,预训练扩散模型可以生成各种各样的序列,与自然序列的相似性从 20% 到 50% 不等。
其次,使用与 CYP706X 亚家族具有明显相似性的 19,202 个 P450 酶序列对预训练扩散模型进行微调,以确保生成的序列具有与 F6H 相似的结构骨架。
此外,对 T114 、 F123 、 A220 、 M248 、 A317 这 5 个创始残基进行了约束,以确保在从头生成的序列中能重现「三点固定」设计原理,将训练集微调与约束生成相结合的模型称为微调扩散模型。
随后,为了提高实验验证的成功率,研究人员采用了三项标准对 6 万个生成的序列进行了虚拟筛选:评估生成序列质量的综合指标的计算得分、 5 个创始残基的三维口袋约束以及芹菜素结合模式的稳健性。
虚拟筛选之后,研究人员精心挑选了 17 个有前景的非天然 P450 酶进行进一步探索。
研究结果:催化能力提高了 1.3 至 3.5 倍
研究人员通过实验测试了 P450Diffusion 生成的序列是否为真正的 P450 酶,并执行 F6H 功能。
虚拟筛选之后,研究人员合成了挑选的 17 个设计并在酵母表达系统中表达。与 CYP706X1 相比,这些设计表现出 70% 到 87% 的序列同一性,突显了它们作为新型催化剂的潜力。
通过喂养芹菜素作为底物培养重组酵母 4 天,并进行 HPLC 分析,研究人员发现了 10 个设计具有显著的 F6H 活性,如下图所示。
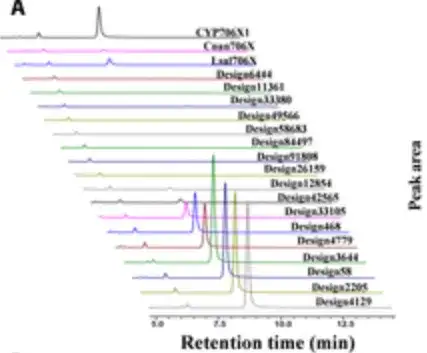
令人惊讶的是,有 6 个设计在黄花夹竹桃苷生产方面的催化能力相比 CYP706X1 表现出 1.3 到 3.5 倍的增加,如下图右边的 6 根柱状所示,其余 4 个活性设计也表现出与其他天然 F6H 酶 (即 Cnan706X 和 Lsal706X) 相当的活性。
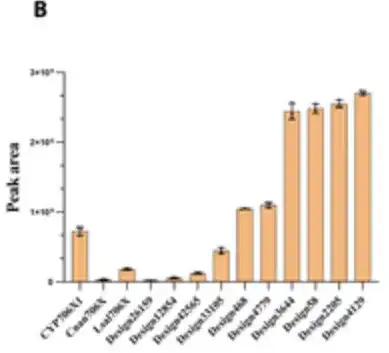
结果表明,P450Diffusion 不仅能够捕捉 F6H 催化口袋的基本设计原则,并有效生成具有 F6H 活性的 P450 酶序列,还能够从 P450 酶序列空间中筛选出比天然序列更好的 P450 酶。
数据驱动,机器学习助力酶进化加速
自然界中存在的酶拥有多种多样的功能,已经被应用在工业生产和学术研究中,但其中许多酶的性质和功能还不能完全满足应用需要,通过改造来提升这类酶的某些特性是酶工程的重要任务。
其中,定向进化法通过模拟自然界的进化过程,可提高酶的进化速度,成为酶分子改造的关键技术。定向进化在生物催化以及药物设计等方面发挥着重要作用,但因突变的随机性所产生的数量庞大的突变体,使得实验筛选的能力面临巨大挑战。近年来,人工智能、大数据处理等新兴技术已经发展成为生物催化领域的重要研究手段。其中,机器学习通过数据驱动的方式获得序列/结构到酶功能的映射,为提高酶工程的效率提供帮助。
尽管编码酶的基因可以很容易地被识别出来,但在绝大多数 (超过 99%) 的情况下,合成酶的确切功能是未知的,这是因为酶功能的实验表征——即特定酶将哪些起始分子转化为哪些具体的末端分子,非常耗时。
针对这一挑战,杜塞尔多夫大学 (HHU) 的研究人员开发了用于预测酶-底物对的通用机器学习模型 ESP,在独立和多样化的测试数据上的准确度超过 91% 。 ESP 可以成功应用于训练数据中包含的广泛不同的酶和广泛的代谢物,优于为单独的、经过充分研究的酶家族设计的模型。
该研究以「A general model to predict small molecule substrates of enzymes based on machine and deep learning」为题于 2023 年 5 月发布在 Nature Communications 。
论文链接:
https://www.nature.com/articles/s41467-023-38347-2
从头酶设计虽然令人兴奋,但也受到酶催化的复杂性的挑战。无细胞酶工程公司 Enzymit 的研究人员引入 CoSaNN(使用神经网络的构象采样),这是一种酶设计的新策略,利用深度学习的进步进行结构预测和序列优化。通过控制酶的构象,研究人员可以扩展化学空间,使其超出简单诱变的范围。
此外,该团队还进一步开发了 SolvIT,这是一种经过训练可预测大肠杆菌中蛋白质溶解度的图神经网络,作为生产高表达酶的额外优化层。通过这种方法,研究人员设计了具有优异表达水平的新型酶,其中 54% 的设计在大肠杆菌中表达,并提高了热稳定性,超过 30% 的设计具有比模板酶更高的 Tm 。
该研究以「Context-Dependent Design of Induced-fit Enzymes using Deep Learning Generates Well Expressed, Thermally Stable and Active Enzymes」为题,于 2023 年 8 月发布在 bioRxiv 预印平台。
论文链接:
https://www.biorxiv.org/content/10.1101/2023.07.27.550799v3

数据显示,2023 年,仅工业酶的全球市场规模价值就达到 74 亿美元。未来,利用人工智能的力量,学习有关蛋白质构成和进化的特征信息,研究人员能够解决许多类型的酶工程问题,例如预测具有有益影响的突变、优化蛋白质的稳定性、提高催化活性等等….. 这都将进一步降低生物制造的成本,并带来更高的商业价值。
参考资料:
1.https://spj.science.org/doi/10.34133/research.0413
2.https://www.cas.cn/syky/202407/t20240718_5026250.shtml
3.https://biotech.aiijournal.com/CN/10.13560/j.cnki.biotech.bull.1985.2022-0724
4.https://www.jiqizhixin.com/articles/2023-06-25-12
5.https://www.jiqizhixin.com/articles








