HyperAI
Command Palette
Search for a command to run...
BRIGHT 文本检索基准数据集
* 该数据集支持在线使用,点击此处跳转。
该数据集是由香港大学、普林斯顿大学、华盛顿大学和 Google Cloud AI Research 于 2024 年推出的新型文本检索基准测试,相关论文成果为「BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval」。
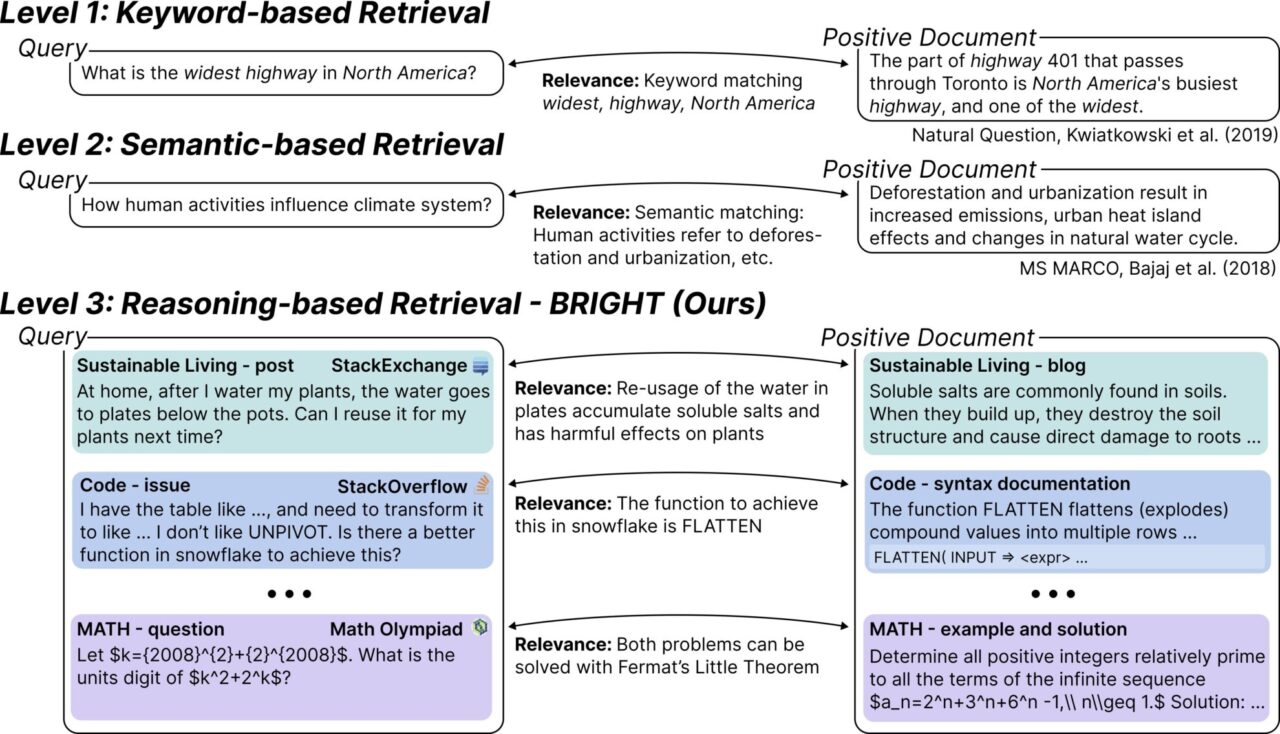
BRIGHT 是第一个需要深入推理才能检索相关文档的文本检索基准。研究团队从不同领域(StackExchange 、 LeetCode 和数学竞赛)收集了 1,385 个真实查询,这些查询全部来自真实的人工数据。团队将这些查询与 StackExchange 答案中链接的网页、数学奥林匹克问题中标记的定理配对。
它专门设计用来评估和挑战检索系统在处理复杂查询时的表现。这些查询不仅需要关键词匹配,还需要深入的推理能力来识别相关文档。简单来说,BRIGHT 测试的是检索系统是否能够「理解」查询背后的逻辑和上下文,而不仅仅是表面的文字。例如,一个经济学家想要找到关于「人类活动如何影响气候系统」的文档。这个问题不仅仅是关于关键词的匹配,而是需要理解人类活动(如砍伐森林和城市化)与气候变化之间的关系。
BRIGHT.torrent
做种 1正在下载 0已完成 190总下载量 336
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。