Command Palette
Search for a command to run...
OPID: تقطير المهارات ضمن السياسة للتعلم التعزيزي الوكيلى
OPID: تقطير المهارات ضمن السياسة للتعلم التعزيزي الوكيلى
الملخص
يوفر التعلم المعزز القائم على النتائج هيكلًا أساسيًا مستقرًا للتحسين لوكلاء اللغة agents، لكن مكافآته المتفرقة على مستوى المسار تقدم توجيهًا ضئيلًا بشأن القرارات الوسيطة التي ينبغي تعزيزها أو كبتها. يوفر التلطف الذاتي على السياسة إشرافًا كثيفًا على مستوى token، إلا أن المتغيرات المشروطة بالمهارات الحالية غالبًا ما تعتمد على ذاكرات المهارات الخارجية أو السياق المميز المسترجع، والتي تتطلب تكلفة عالية للصيانة وقد لا تتطابق مع توزيع الحالة الناتج عن السياسة الحالية في التفاعل متعدد الجولات. نقترح إطار عمل OPID (التلطف المهاراتي على السياسة)، والذي يستخرج الإشراف المهاراتي مباشرة من مسارات السياسة المكتملة. يمثل OPID البصيرة اللاحقة للمسار كمهارات هرمية: حيث تلتقط مهارات مستوى الحلقة سير العمل العالمية أو قواعد تجنب الفشل، بينما تلتقط مهارات مستوى الخطوة المعرفة المحلية لاتخاذ القرار في الأوقات الحرجة. تستخدم آلية التوجيه ذات الأولوية للحسم مهارات مستوى الخطوة عند تحديد القرارات الحرجة، وتعود إلى مهارات مستوى الحلقة كتوجيه افتراضي في الحالات الأخرى. يتم حقن المهارة المختارة في تاريخ التفاعل، مما يسمح للسياسة القديمة بإعادة تقييم نفس الاستجابة المُعاينة تحت كل من السياقات الأصلية والمُثراة بالمهارات. ينتج عن ذلك تحول في الاحتمال اللوغاريتمي يولد ميزة تلطف ذاتي على مستوى token، والتي يتم دمجها مع ميزة النتيجة لتحسين السياسة. يحافظ OPID بذلك على التعلم المعزز RL كهدف تدريبي أساسي، مع تقديم إشراف لاحق كثيف ومتطابق مع التوزيع. تُظهر التجارب على ALFWorld و WebShop و Search-based QA أن OPID يحسن بشكل عام أداء agent، وكفاءة العينة، والمتانة مقارنة بالتعلم المعزز القائم على النتائج فقط والأسس المرجعية الحالية للتلطف المهاراتي. يتوفر كودنا على الرابط https://github.com/jinyangwu/OPID/tree/main.
One-sentence Summary
The authors propose OPID, an on-policy skill distillation framework that extracts episode-level and step-level skills from completed on-policy trajectories and uses a critical-first routing mechanism to inject the appropriate skill into the interaction history, enabling the old policy to re-score the same response under original and skill-augmented contexts to provide dense token-level supervision without external skill memories and guide intermediate decisions in multi-turn reinforcement learning.
Key Contributions
- On-policy hindsight skill extraction obtains skill supervision from completed trajectories sampled by the current policy, removing the need for external skill memories and keeping the guidance distribution-matched.
- A hierarchical skill representation encodes episode-level global workflows or failure-avoidance rules and step-level critical local decisions, combined with a critical-first routing mechanism that selects the most specific skill for each trajectory step.
- Skill-based self-distillation is integrated into outcome-driven reinforcement learning, converting routed hindsight skills into dense token-level shaping signals while preserving the primary outcome reward objective; evaluations on ALFWorld, WebShop, and Search-based QA show consistent gains over outcome-only RL and skill-distillation baselines, along with improved sample efficiency and fewer repetitive or invalid behaviors.
Introduction
Large language models are increasingly deployed as interactive agents that must reason over long sequences of tool calls and environment observations, making post-training with outcome-based reinforcement learning (e.g., GRPO) attractive because it directly optimizes for task success. However, such outcome rewards are sparse and delayed, offering only coarse trajectory-level feedback without fine-grained credit for individual decisions. Prior work addresses this by distilling token-level guidance from skills or privileged contexts, but existing skill-conditioned methods depend on external skill libraries that require careful maintenance and often retrieve skills mismatched to the current policy’s state distribution. The authors introduce OPID (On-Policy Skill Distillation), a framework that extracts hierarchical hindsight skills (episode-level workflows and step-level critical guidance) directly from trajectories produced by the current policy. It uses a critical-first routing mechanism to inject the most relevant skill into the agent’s context, computes a token-level self-distillation advantage from the resulting log-probability shift, and combines it with the outcome reward for optimization, thereby densifying supervision without any external retrieval or privileged context at inference time.
Dataset
The authors evaluate on three agentic domains using separate datasets, each with its own training split. For embodied reasoning, they use ALFWorld, a text-based household environment. For web navigation, they rely on WebShop, a simulated e-commerce setting. For search-augmented question answering, they consolidate multiple knowledge-intensive QA benchmarks under a unified retrieval-augmented setting.
Key details per subset:
- ALFWorld: 2,400 training examples sampled from six task types (Pick, Look, Clean, Heat, Cool, Pick2). The agent receives natural-language goals and textual observations and must produce admissible action sequences.
- WebShop: 2,400 training examples sampled from the product search and purchase environment. Performance is measured with a normalized task-completion score and a binary exact-match success signal.
- Search-augmented QA: 19,200 training examples drawn from Natural Questions, TriviaQA, PopQA, HotpotQA, 2WikiMultiHopQA, MuSiQue, and Bamboogle. The agent interacts with a search environment before generating a final answer, following the Search-R1 protocol.
Training setup and data processing:
- Training is conducted separately for each benchmark setting, meaning the model is not trained on a mixture across domains.
- No additional cropping strategy, metadata construction, or filtering beyond the sampling step is described; the original dataset structures are preserved, and the sampling sizes directly determine the training corpora for each domain.
Method
Theauthors propose OPID (On-Policy Skill Distillation), a framework that converts completed on-policy trajectories into hierarchical skills and distills their behavioral effect back into the policy. The overall pipeline is illustrated in the framework diagram below.
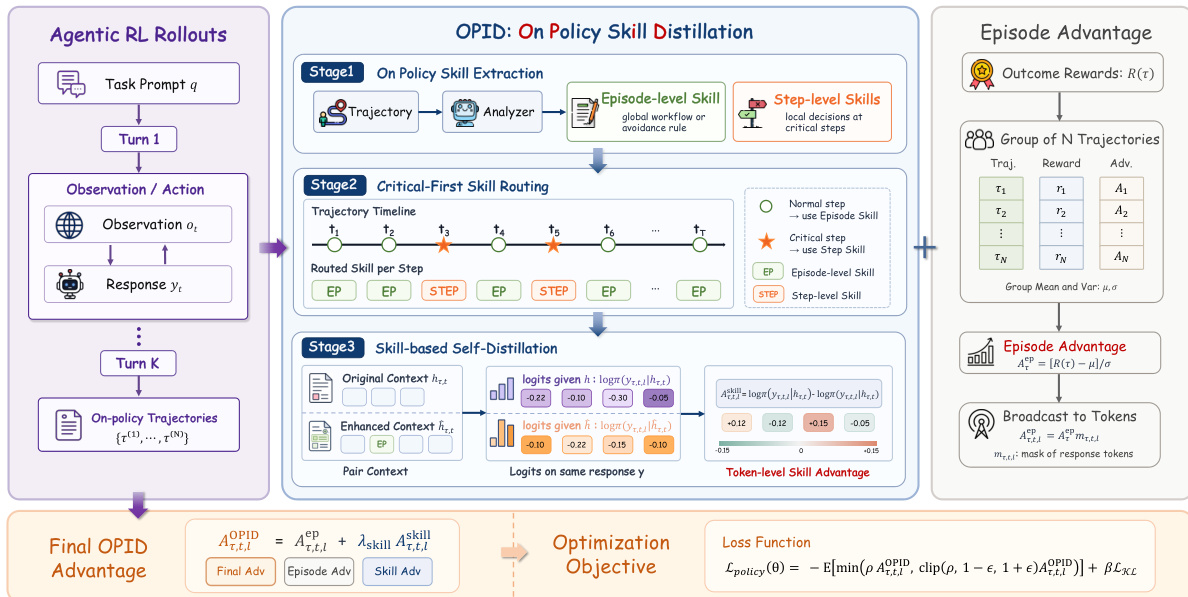
OPID performs on-policy skill distillation in three main stages. First, it extracts hierarchical skills from completed on-policy trajectories. Second, it routes the appropriate skill to each decision step and converts the skill effect into token-level self-distillation signals. Third, it combines these token-level skill advantages with group-relative outcome advantages for policy optimization.
Problem Formulation The authors model an agentic task as a partially observable Markov decision process defined by (S,A,O,T,R,γ). At timestep t, the agent maintains an interaction history ht=(o0,y0,o1,y1,…,ot), where yi denotes the textual response or executable action generated at step i. The policy πθ generates the next response as yt∼πθ(⋅∣ht). A completed trajectory is represented as τ={(ot,yt,rt)}t=0T−1. Following GRPO-style training, for each task prompt q, a group of N trajectories is sampled from the current policy: Gq={τ(1),τ(2),…,τ(N)}.
On-Policy Skill Extraction Outcome rewards reveal whether a trajectory succeeds, but not why. OPID represents post-hoc trajectory knowledge as hierarchical skills extracted from completed on-policy rollouts. The hierarchy contains two complementary levels:
- Episode-level skills (sτep): Summarize the global behavioral pattern of a complete trajectory. For successful trajectories, they capture reusable workflows; for failed ones, they capture failure-avoidance rules.
- Step-level skills (sτ,tstep): Capture local decision knowledge at critical timesteps where the final outcome depends strongly on a specific choice.
Given a completed trajectory τ, an LLM-based analyzer A maps the trajectory record to structured natural-language skills. The prompt used for this analyzer is shown in the figure below.

The analyzer outputs A(τ)=(sτep,{sτ,tstep}t∈Cτ), where Cτ is the sparse set of critical timesteps identified by the analyzer.
Critical-First Skill Routing Applying the same skills to every step is suboptimal. Episode-level skills are robust but may be too coarse at decisive states, whereas step-level skills are precise but sparse. OPID introduces a critical-first skill routing mechanism. For trajectory τ and timestep t, the routed skill is:
sτ,t={sτ,tstep,sτep,if t∈Cτ,otherwise.This ensures that step-level skills are prioritized at critical states, while episode-level skills serve as default guidance otherwise.
Skill-Based Self-Distillation After routing, OPID converts the selected skill into token-level self-distillation supervision. Let H(⋅,⋅) denote a deterministic skill-injection function that appends or prepends the routed skill to the interaction history. The skill-augmented history is h~τ,t=H(hτ,t,sτ,t).
The old policy πθold scores the same sampled response yτ,t under both the original and skill-augmented histories. For token ℓ in response yτ,t, the log-probabilities are:
ℓτ,t,ℓold=logπθold(yτ,t,ℓ∣hτ,t,yτ,t,<ℓ) ℓτ,t,ℓskill=logπθold(yτ,t,ℓ∣h~τ,t,yτ,t,<ℓ)The skill-based self-teacher advantage is defined as:
Aτ,t,ℓskill=(ℓτ,t,ℓskill−ℓτ,t,ℓold)mτ,t,ℓwhere mτ,t,ℓ∈{0,1} is the valid response-token mask. If Aτ,t,ℓskill>0, the selected skill makes the token more likely, suggesting consistency with the skill.
Policy Optimization with Skill Advantage For each rollout group Gq, the group-relative outcome advantage is computed by normalizing the trajectory outcome reward R(τ) within its prompt group:
Aτep=σqR(τ)−μq,τ∈Gqwhere μq and σq are the mean and standard deviation of the group rewards. This scalar is broadcast to all valid response tokens: Aτ,t,ℓep=Aτepmτ,t,ℓ.
The final OPID advantage combines group-relative outcome feedback with token-level skill supervision:
Aτ,t,ℓOPID=Aτ,t,ℓep+λskillAτ,t,ℓskillThe authors optimize the standard clipped policy objective:
Lpolicy(θ)=−Eτ,t,ℓ[min(ρτ,t,ℓ(θ)Aτ,t,ℓOPID,clip(ρτ,t,ℓ(θ),1−ϵ,1+ϵ)Aτ,t,ℓOPID)]+βLKL(θ)where ρτ,t,ℓ(θ) denotes the token-level importance ratio. This formulation keeps outcome reward as the primary RL signal while adding token-level shaping. At inference time, the learned policy acts from the ordinary interaction history alone without requiring analyzer calls or skill retrieval.
Experiment
Evaluated on ALFWorld, WebShop, and Search-based QA against prompting, outcome-only RL, and hybrid baselines, OPID consistently improves over GRPO and matches or exceeds the strongest distillation methods while internalizing hindsight skills so the policy no longer depends on skill prompts at inference. Training dynamics reveal accelerated policy refinement with shorter, more direct action trajectories, and the approach yields strong sample efficiency gains and cross-domain generalization by learning reusable behavioral structure. Ablations confirm that combining episode-level and step-level skills with critical-first routing effectively targets supervision at decision points, outperforming uniform guidance and validating the complementary role of hierarchical skill granularity.
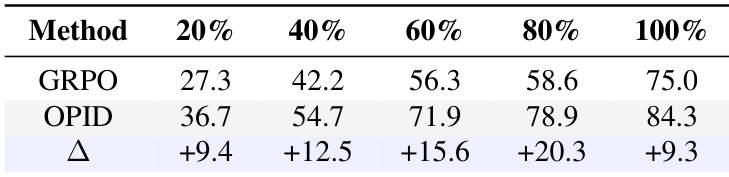
The authors evaluate sample efficiency by comparing OPID and GRPO across varying fractions of training data on the ALFWorld benchmark. Results show that OPID consistently outperforms GRPO at all data scales, with the performance gap widening significantly in the mid-data regimes. Notably, OPID trained on a subset of the data achieves performance comparable to or better than GRPO trained on the full dataset, demonstrating improved data efficiency through skill supervision. OPID consistently achieves higher success rates than the GRPO baseline across all tested training data fractions. The performance advantage of OPID over GRPO is most pronounced in the mid-data regimes. OPID demonstrates strong sample efficiency by matching or exceeding the full-data performance of GRPO when trained on a reduced portion of the dataset.
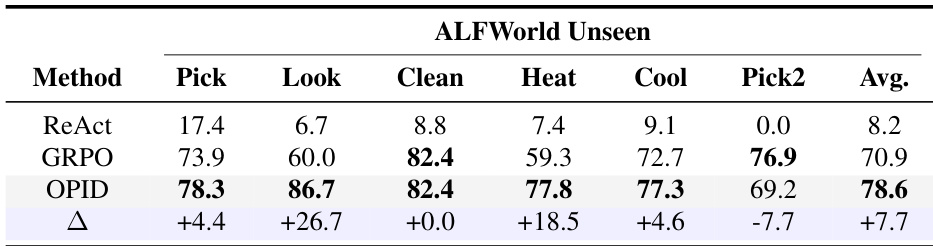
The authors evaluate cross-domain generalization on an unseen split of the ALFWorld benchmark to demonstrate that the proposed method captures reusable behavioral structures rather than merely memorizing training trajectories. Results show that the method consistently outperforms the outcome-only reinforcement learning baseline on average, with particularly substantial improvements on specific task types like Look and Heat. The proposed method achieves the highest average success rate across all unseen task types, significantly outperforming the reinforcement learning baseline. Performance gains over the baseline are most pronounced in Look and Heat tasks, indicating strong transfer of high-level task workflows and local decision rules. While the method improves performance on most task categories, it shows mixed results on the Pick2 task, suggesting some task-specific limitations in generalization.
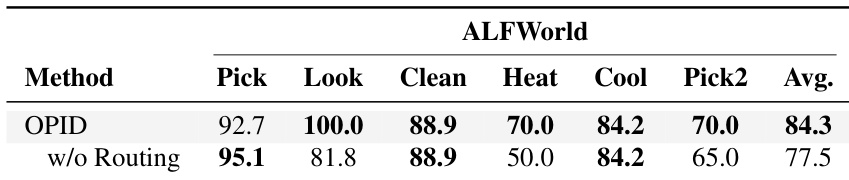
The authors conduct an ablation study to evaluate the impact of critical-first skill routing on the ALFWorld benchmark. Results indicate that the complete model with routing achieves a higher average success rate compared to a variant without routing. This demonstrates that selectively applying the most appropriate skill granularity is more effective than simply combining global and local guidance at all steps. The full model outperforms the non-routed variant in the overall average success rate across ALFWorld tasks. The routing mechanism provides substantial gains on specific task types such as Look and Heat, while the non-routed variant performs slightly better on the Pick task. Selectively routing skills proves more effective than superimposing episode-level and step-level guidance at every timestep.
The authors conduct an ablation study to evaluate the impact of hierarchical skill granularity on agent performance. Results show that the complete hierarchy of episode-level and step-level skills achieves the best aggregate performance across both ALFWorld and WebShop benchmarks. Removing either skill level leads to a noticeable decline in success rates, demonstrating the complementarity of global workflows and local decision guidance. The full hierarchical skill setup outperforms variants that lack either episode-level or step-level skills. Removing episode-level skills causes a significant drop in performance, indicating that global workflows provide an important default signal. Removing step-level skills also degrades performance, confirming that precise guidance at critical decision points is necessary for optimal results.
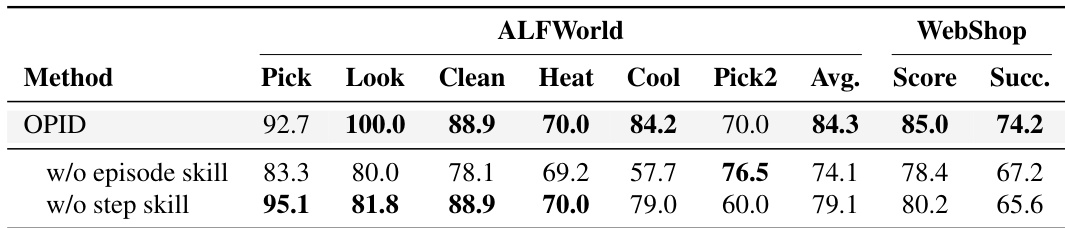
The authors evaluate OPID across multiple agentic benchmarks and model scales, demonstrating that it consistently strengthens outcome-only reinforcement learning. Results show that OPID matches or surpasses strong hybrid and self-distillation baselines by internalizing hindsight skills into the policy rather than relying on them at inference time. OPID consistently outperforms the outcome-only GRPO baseline across most model and domain combinations, with particularly large gains on long-horizon embodied and web-shopping tasks. The method achieves top aggregate performance on several benchmarks, competing effectively with hybrid training approaches that use auxiliary token-level or skill-conditioned supervision. Unlike methods that depend on skill prompts during validation, OPID successfully transfers trajectory-derived knowledge into model parameters, maintaining strong performance without external skill context.
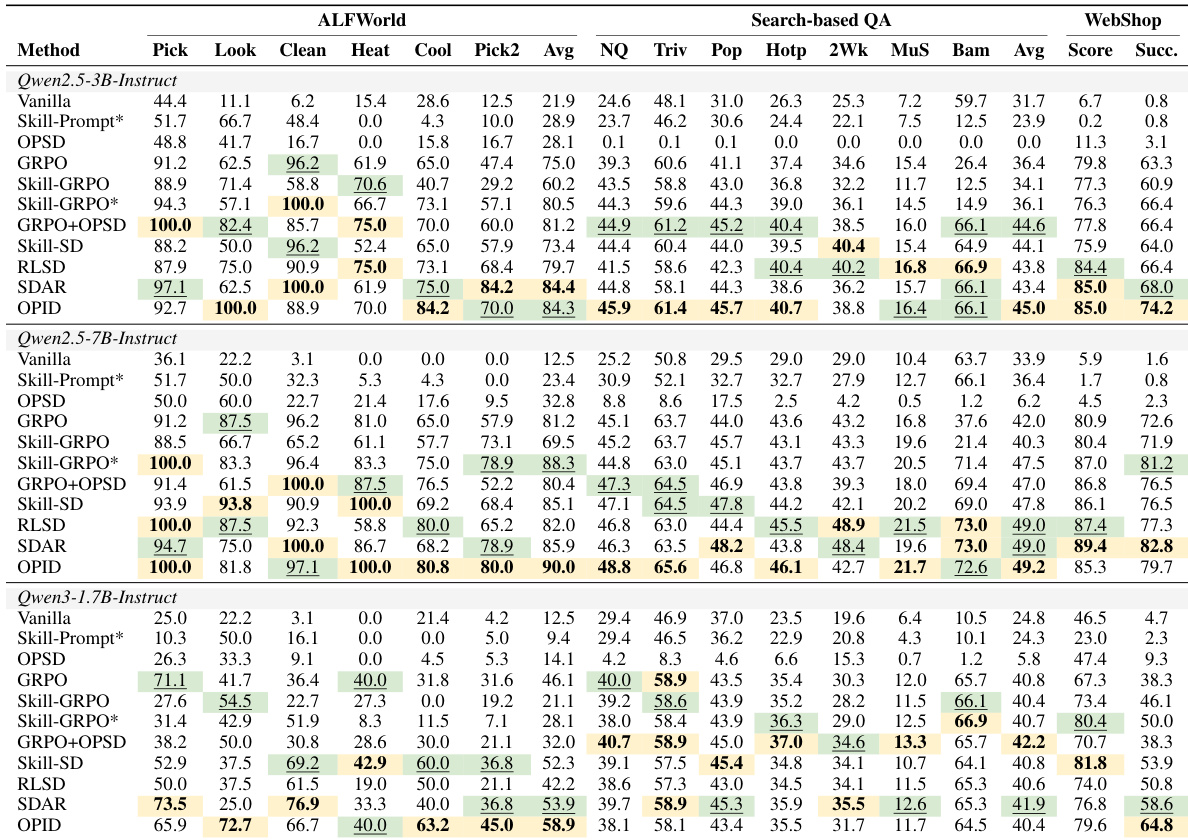
Across ALFWorld and WebShop benchmarks, OPID consistently outperforms outcome-only RL baselines like GRPO, demonstrating improved sample efficiency and cross-domain generalization by learning reusable behavioral structures. Ablation studies show that both hierarchical skill granularity and critical-first routing contribute to performance, with the full model achieving the best results. When evaluated across multiple benchmarks and model scales, OPID matches or surpasses hybrid and self-distillation baselines, effectively internalizing hindsight skills into the policy without requiring external skill context at inference.