Command Palette
Search for a command to run...
أعمال OCR غير محدودة: مرحبًا بعصر التفكيك طويل المدى بنمط الضربة الواحدة
أعمال OCR غير محدودة: مرحبًا بعصر التفكيك طويل المدى بنمط الضربة الواحدة
Baoding Zhou Jingyun Wang Xiaolin Wei Jianwei Niu Hui Lin Zhenyu Li Zhiwei Xu Xiaojun Wan
الملخص
في الآونة الأخيرة، أعادت نماذج التعرف الضوئي على الحروف (OCR) من طرف إلى طرف، والتي يُعد نموذج DeepSeek OCR مثالاً بارزاً لها، إلقاء الضوء مجدداً على هذا المجال. يسود اعتقاد واسع مفاده أن استخدام نموذج لغوي كبير (LLM) كمُشفِّر (decoder) يتيح للنموذج الاستفادة من التوزيع المسبق للغة، مما يؤدي إلى تحسين أداء التعرف الضوئي على الحروف. ومع ذلك، فإن الجانب السلبي واضح أيضاً: فمع ازدياد طول تسلسل المخرجات، يؤدي تراكم ذاكرة المفاتيح والقيم (KV cache) إلى زيادة استهلاك الذاكرة وإبطاء عملية التوليد بشكل تدريجي. وهذا يتعارض بشدة مع الكفاءة البشرية، إذ لا تظهر لدى البشر أي تدهور في الكفاءة أثناء مهام النسخ طويلة المدى.في هذا التقرير التقني، نقترح نموذجاً جديداً باسم Unlimited OCR، مصمم لمحاكاة ذاكرة العمل الخاصة بالمعالجة البصرية لدى البشر. وباستخدام DeepSeek OCR كنقطة انطلاق، استبدلنا جميع طبقات الانتباه (attention layers) في المُشفِّر بآلية انتباه نافذة انزلاقية مرجعية (Reference Sliding Window Attention - R-SWA) التي اقترحناها، والتي تقلل من تكاليف حساب الانتباه مع الحفاظ على حجم ثابت لـ KV cache طوال عملية فك التشفير بأكملها. ومن خلال الجمع بين معدل الضغط العالي في مُشفِّر DeepSeek OCR وتصميمنا لـ KV cache الثابت، يمكن لـ Unlimited OCR نسخ عشرات صفحات المستندات في تمرير أمامي (forward pass) واحد، ضمن حد أقصى قياسي للطول يبلغ 32K. والأهم من ذلك، أن R-SWA هي آلية انتباه معالجة أغراض عامة؛ فهي لا تنطبق فقط على التعرف الضوئي على الحروف، بل يمكن أيضاً تطبيقها على مهام أخرى مثل التعرف التلقائي على الكلام (ASR) والترجمة الآلية، وغيرها.أصبح الكود المصدري وأوزان النموذج متاحين علناً على الرابط التالي: http://github.com/baidu/Unlimited-OCR.
One-sentence Summary
Researchers from Baidu propose Unlimited OCR, a model that emulates human parsing working memory by replacing all decoder attention layers in the DeepSeek OCR baseline with Reference Sliding Window Attention (R-SWA), maintaining a constant KV cache to enable efficient one-shot transcription of dozens of document pages under a standard 32K maximum length without the memory and speed degradation typical of LLM-based OCR systems.
Key Contributions
- Unlimited OCR is introduced as an end-to-end model that replaces all decoder attention layers with Reference Sliding Window Attention (R-SWA), maintaining a constant KV cache throughout decoding to eliminate the memory and speed degradation of long-sequence generation.
- R-SWA is a general-purpose parsing attention mechanism inspired by human working memory, where the model learns a soft-forgetting behavior by passing only essential historical information into a fixed window rather than retaining the full context.
- Replacing all decoder self-attention with causal R-SWA yields lossless OCR parsing performance, enabling transcription of dozens of document pages in a single 32K-token forward pass, and the approach is applicable to other long-horizon reference-based tasks such as ASR and translation.
Introduction
Recent end-to-end OCR models that use large language model decoders have brought significant accuracy gains, but they suffer from a critical bottleneck: as the output sequence grows longer, the accumulated key-value cache consumes more memory and slows generation. This stands in contrast to human working memory, which maintains a constant cognitive load during long copying tasks without consulting the entire history. Prior approaches handle multi-page documents by processing pages in a loop and resetting memory each time, which fragments the task rather than solving it natively.
The authors introduce Unlimited OCR, which replaces the decoder’s standard attention with Reference Sliding Window Attention (R-SWA). In this design, each generated token attends to all reference tokens (visual and prompt tokens) while only attending to a small sliding window of preceding output tokens. This keeps the key-value cache size constant throughout decoding and avoids the progressive blurring of visual features that occurs in standard sliding window attention. By combining this constant-cache decoder with a high-compression image encoder, the model can transcribe dozens of document pages in a single forward pass under a standard 32K context length, while also improving general OCR accuracy over the baseline.
Dataset
Here is a concise dataset description based on the provided text.
Dataset Composition and Sources
- The authors construct a specialized dataset of roughly 2 million document OCR samples to train the Unlimited OCR model.
- The data is split with a 9:1 ratio between single-page and multi-page documents.
- A separate in-house benchmark is built for long-horizon evaluation, sourcing novels, documents, and papers grouped by page count.
Key Details for Each Subset
- Single-Page Data: The source is PDF documents. The authors use Paddle OCR for annotation, extracting block coordinates and content to create ground truth for end-to-end detection and parsing.
- Multi-Page Data: This subset is entirely synthetic. The authors generate around 200,000 samples by concatenating single-page documents. Each sample contains between 2 and 50 pages, with a
<page>token used as a separator. - In-House Benchmark: This test set is organized by document length, with categories for books of 2, 5, 10, 20, and 40+ pages. Each category contains no fewer than ten books.
Data Usage in the Model
- The constructed dataset is used to train the Unlimited OCR model.
- The authors pack all training data into sequences with a fixed length of 32,000 tokens.
Processing and Metadata Details
- Coordinate Normalization: For single-page data, the coordinates of each detected element are normalized to a range of 0–1000.
- Metadata Construction: The ground truth for single-page data is built by concatenating the normalized coordinates with the corresponding textual content of each block.
Method
The authors proposeUnlimited OCR, a unified end-to-end architecture designed for long-horizon parsing. As shown in the figure below, the model features a high-compression encoder paired with a Mixture-of-Experts (MoE) LLM decoder.
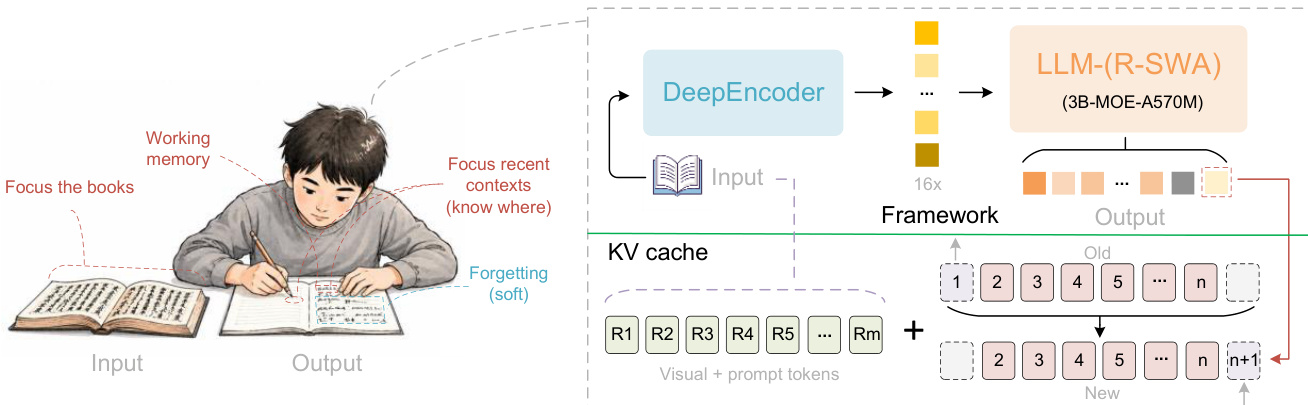
The framework adopts DeepSeek OCR as its baseline, comprising the DeepEncoder and an MoE-LLM decoder with 3B total parameters and 500M activated parameters. The DeepEncoder provides exceptional visual token compression, drastically reducing the KV cache footprint during the prefill stage while preserving robust optical text feature extraction. A key departure from the original baseline is the replacement of vanilla Multi-Head Attention (MHA) with the proposed R-SWA mechanism. This allows long-horizon parsing by augmenting the original reference KV cache m with a fixed-capacity output KV buffer of width n.
The DeepEncoder cascades SAM-ViT with CLIP-ViT and applies a 16× token compression at the bridge. The first half relies entirely on window attention to process original image tokens, while global attention is reserved exclusively for the compressed tokens. This design keeps activation values low when encoding high-resolution images, thereby conserving GPU memory. The encoder natively supports multiple resolution modes, including a Base model for multi-page inputs and a Gundam mode for dynamic resolution single-page inputs. For instance, it can compress a 1024×1024 PDF-image to just 256 tokens. This high compression ratio is critical because visual tokens do not undergo state transitions alongside the output; they are encoded once and remain static throughout the entire parsing process.
The decoder directly affects inference cost, specifically regarding LLM activation values and KV cache size. To address the former, the authors utilize an MoE architecture, keeping activation at only 500M during inference. To address the latter, where KV cache typically grows continuously with decoding contexts, the model implements R-SWA.
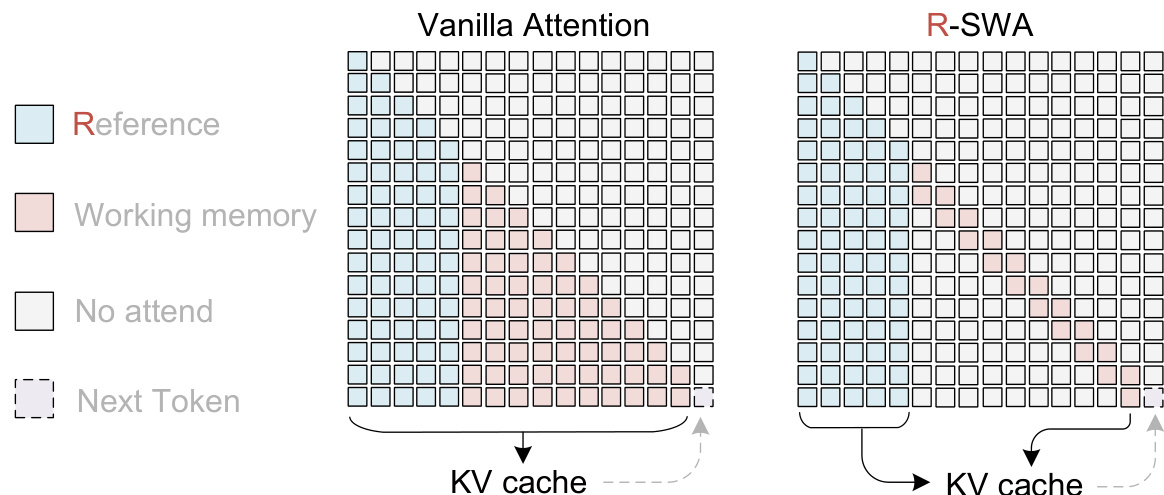
As illustrated in the comparison above, unlike Vanilla Attention where the KV cache grows indefinitely, R-SWA implements the KV cache as a queue with a capacity of m+n. Each time a new token is generated, the KV corresponding to the (m+1)-th token in the queue is evicted. This ensures that both computational cost and memory usage do not progressively increase during the generation process, mimicking the human process of copying books by focusing on recent contexts while retaining reference information.
Starting from the DeepSeek OCR checkpoint, the authors continue training Unlimited OCR for 4,000 steps with a global batch size of 256 and a maximum sequence length of 32K on 8×16 A800 GPUs, using random packing for all data. During training, the DeepEncoder is frozen as it is already sufficiently optimized, and only the LLM parameters are trained. The authors use the AdamW optimizer and a cosine annealing scheduler with an initial learning rate of 1e-4. To support 32K training, they adopt DeepEP with expert parallelism set to 4. The entire training pipeline is built on the Megatron-LM framework. For inference, KV cache management for R-SWA is implemented in the Transformers library, along with corresponding support and optimizations in the SGLang inference engine, allowing the model to operate under constant tokens per second and GPU memory usage.
Experiment
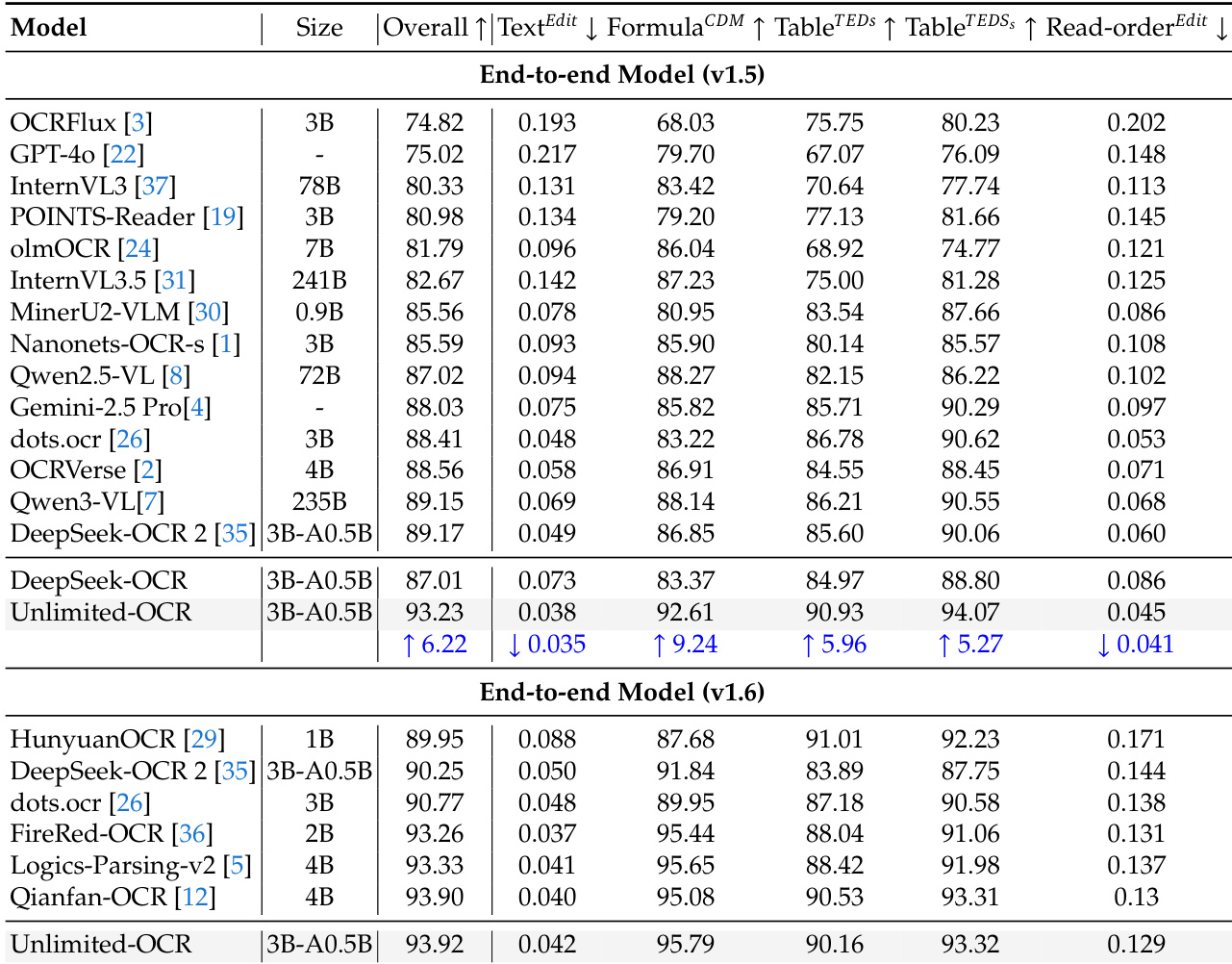
By continue-training DeepSeek OCR on a small set of PDF-specific data, Unlimited OCR replaces standard decoder attention with recurrent sliding window attention (R-SWA), achieving end-to-end state-of-the-art performance on OmniDocBench while increasing inference speed by over 12%. Subcategory evaluations across nine document types confirm consistent gains with no compromises, even on complex layouts like newspapers and magazines. The R-SWA design enables long-horizon parsing by keeping the KV cache fixed, allowing the model to process tens of pages with stable latency and strong edit distance scores. Efficiency analysis shows that as output length grows, Unlimited OCR’s speed advantage widens, reaching a 35% lead over standard attention at 6,000 tokens, though future work aims to overcome prefill length constraints and extend the approach to tasks like ASR and translation.
Theauthors demonstrate that Unlimited OCR achieves state-of-the-art end-to-end performance on the OmniDocBench benchmarks by replacing standard attention with R-SWA. Results show consistent and significant improvements across all evaluation metrics, including text edit distance, formula recognition, and the the table structure, compared to previous models like DeepSeek OCR. Unlimited OCR outperforms all compared models on both OmniDocBench v1.5 and v1.6 datasets across overall metrics and specific sub-tasks. The model achieves substantial gains in text editing distance and the the table recognition scores over its baseline, DeepSeek OCR. The approach delivers consistent improvements across various document types without compromising inference efficiency.
The authors compare the inference efficiency of Unlimited OCR and DeepSeek OCR by measuring tokens per second across varying output lengths. Results indicate that while both models perform similarly at shorter output lengths, the efficiency of DeepSeek OCR degrades as the sequence length increases, whereas Unlimited OCR maintains a consistent and higher speed. Unlimited OCR maintains stable inference speed as output length increases, unlike DeepSeek OCR which shows a steady decline. At longer output sequences, Unlimited OCR demonstrates a significant speed advantage over the baseline model due to the R-SWA mechanism. The consistent generation speed of Unlimited OCR makes it particularly suitable for long-horizon OCR tasks.

The authors assess the model's long-horizon parsing capabilities by testing it on documents with increasing page counts. The results show that the model maintains high output diversity and low error rates even for very long documents, validating the effectiveness of the recurrent sliding window attention mechanism. The authors note that minor errors at extreme lengths are due to image resolution limits rather than the model losing context. The model sustains high diversity scores and low edit distances across documents ranging from 2 to 20 pages. Performance remains satisfactory even for documents with over 40 pages, showing the model does not lose direction during long sequences. The stable metrics confirm that the sliding window attention approach effectively supports continuous parsing without significant degradation.

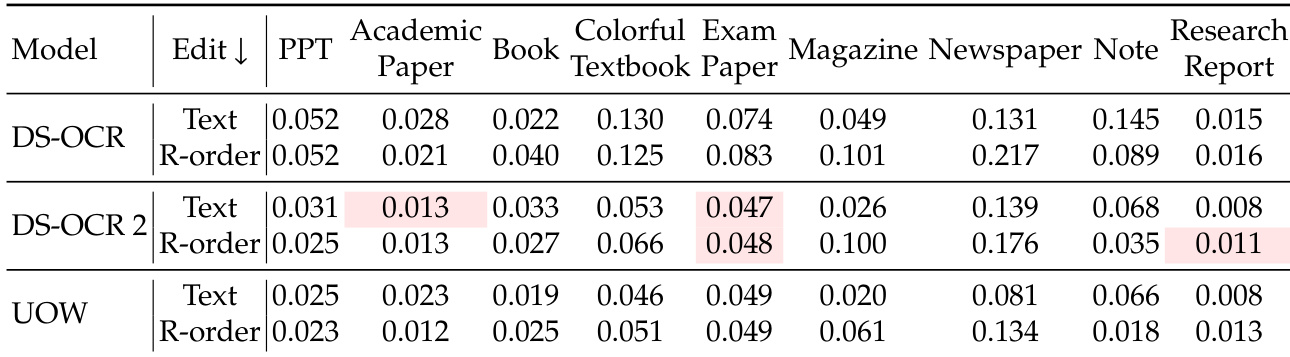
The authors present a subcategory comparison of Unlimited OCR against DeepSeek OCR and DeepSeek OCR 2 across nine document types. Results show that Unlimited OCR achieves consistent improvements over the original DeepSeek OCR across all metrics and document categories. Additionally, the model outperforms DeepSeek OCR 2 in the majority of cases, demonstrating particular effectiveness on complex layouts such as newspapers and notes. Unlimited OCR shows clear and consistent gains over DeepSeek OCR across every metric and document type. The model surpasses DeepSeek OCR 2 in seven out of nine categories for both text edit distance and reading order scores. Performance remains strong for documents with complex layouts like newspapers and notes, showing significant improvements over baseline models.
The evaluation benchmarks Unlimited OCR against prior models on OmniDocBench, where replacing standard attention with recurrent sliding window attention yields consistent gains across text, formula, and the table structure metrics without sacrificing speed. Inference efficiency experiments show that while both models perform similarly at short outputs, Unlimited OCR maintains stable generation speed as sequence length grows, unlike the baseline which degrades. Long-horizon parsing tests on multi-page documents confirm that the approach sustains high output diversity and low error rates even beyond 40 pages, with any minor errors attributed to image resolution rather than context loss. A breakdown by document type further reveals that Unlimited OCR outperforms DeepSeek OCR across all categories and surpasses DeepSeek OCR 2 on most, with particularly strong results on complex layouts such as newspapers and notes.