Command Palette
Search for a command to run...
موبيوس: إطار عمل خفيف الوزن 0.2 مليار لاستكمال الصور بأداء على مستوى 10 مليار
موبيوس: إطار عمل خفيف الوزن 0.2 مليار لاستكمال الصور بأداء على مستوى 10 مليار
Kangsheng Duan Ziyang Xu Wenyu Liu Xiaohu Ruan Xiaoxin Chen Xinggang Wang
الملخص
على الرغم من أن النماذج الأساسية الصناعية ذات الحجم الملياري (10B) قد وسعت حدود مهمة إكمال الصور، فإن تكاليفها الحسابية الباهظة تعيق بشدة نشرها العملي. يُعد بناء متخصص عالي التحسين ومخصص لمهمة معينة حلاً واعدًا؛ غير أن الضغط الهيكلي الشديد يحفز حتمًا عنق زجمة تمثيلي حاد. للتغلب على هذه التحديات، نقترح إطار عمل Moebius، وهو إطار عمل خفيف الوزن وعالي الكفاءة لإكمال الصور. ونعيد بناء العمود الفقري للانتشار بشكل منهجي من خلال إدخال كتلة التفاعل المختلط المحلي-λ (LλMI). ويتألف من وحدتي Local-λ و Interactive-λ، حيث يلخص بشكل أنيق السياقات المكانية والمبادئ الدلالية العالمية في مصفوفات خطية ذات حجم ثابت، مما يحافظ على التفاعلات الكامنة المعقدة مع تقليل عدد المعلمات بشكل كبير. وعلاوة على ذلك، وكشفًا للسعة التمثيلية الكاملة لهذه البنية شديدة الانضغاط، نزاوجها بشكل تآزري مع استراتيجية تقطير تكيفية متعددة الحبيبات. وتعمل هذه الاستراتيجية بشكل صارم ضمن الفضاء الكامن لتجنب عمليات فك التشفير المكلفة في فضاء البكسل، حيث توازن ديناميكيًا بين عدة دوال خسارة قائمة على التدرج لتحقيق محاذاة عالية الدقة. وتُظهر التجارب الواسعة النطاق عبر معايير اللقطات الطبيعية والبورتريه أن هذا التآزر الأمثل يمكّن إطار عمل Moebius من منافسة أو حتى تفوق جودة التوليد للنموذج الصناعي العام FLUX.1-Fill-Dev. وبشكل ملحوظ، يحقق Moebius ذلك باستخدام أقل من 2% من المعلمات (0.22B مقابل 11.9B)، مع تحقيق تسارع يبلغ >15imes في إجمالي وقت الاستدلال، مما يرسخ معيارًا جديدًا للكفاءة في مهمة إكمال الصور عالية الدقة. الصفحة الخاصة بالمشروع على الرابط: https://hustvl.github.io/Moebius.
One-sentence Summary
The authors propose Moebius, a 0.2B lightweight image inpainting framework that overcomes representation bottlenecks via a Local-λ Mix Interaction block compressing spatial and semantic priors into fixed-size linear matrices and an adaptive multi-granularity distillation strategy, enabling it to rival 10B-level FLUX.1-Fill-Dev on natural and portrait benchmarks while utilizing less than 2% of the parameters and delivering over 15× faster inference.
Key Contributions
- The paper introduces Moebius, a lightweight inpainting framework that reconstructs the diffusion backbone using the Local-λ Mix Interaction (LλMI) block. This component compresses local spatial contexts and global semantic priors into fixed-size linear matrices to enable efficient self- and cross-attention operations while reducing the parameter count to 0.22B.
- To address the representation bottleneck inherent in extreme structural compression, the framework employs an adaptive multi-granularity distillation strategy that operates strictly within the latent space. By dynamically balancing multiple gradient-based losses, this optimization aligns the compact model with a high-capacity teacher without reintroducing architectural overhead.
- Extensive evaluations across natural and portrait benchmarks demonstrate that the model matches or exceeds the generation quality of the 11.9B-parameter FLUX.1-Fill-Dev foundation model. This configuration achieves a greater than 15× acceleration in total inference time while maintaining high-fidelity output, establishing a new performance-latency trade-off for inpainting tasks.
Introduction
High-parameter diffusion models have revolutionized image inpainting, yet their massive computational demands and memory footprints prevent practical deployment on resource-constrained or latency-sensitive devices. Previous attempts to compress these architectures using standard lightweight operators trigger a severe representation bottleneck, causing catastrophic quality degradation and limiting essential cross-attention capabilities. To overcome this, the authors leverage a novel Local-lambda Mix Interaction block that efficiently encodes spatial and semantic contexts into fixed-size matrices, synergizing it with an adaptive multi-granularity distillation strategy. This approach enables their 0.2B-parameter Moebius framework to rival 10B-level industrial models in generation fidelity while achieving over 15 times faster inference.
Experiment
Evaluated across natural and portrait inpainting benchmarks using standardized inference profiling and dataset-specific fine-tuning following a multi-granularity distillation process, the experiments validate the model's ability to bridge the scale gap between extreme compactness and high-fidelity generation. Qualitative assessments and human preference studies consistently demonstrate that the approach matches its heavy teacher and significantly outperforms massive industrial generalists by delivering structurally coherent restorations free from common artifacts like blurring and semantic inconsistency. Further validation on complex real-world object removal tasks and ablation analyses confirms that holistic architectural integration and latent-space distillation objectives are essential for achieving robust contextual understanding and optimal quality-efficiency trade-offs.
The authors evaluate Moebius against the teacher model Pixel Hacker and large industrial models using a user study. The results indicate that Moebius achieves an average user preference score that closely matches the teacher model and significantly outperforms the industrial baselines. Moebius demonstrates particular strength in portrait scenes, where it achieves the highest preference score among all methods. Moebius achieves an average user preference score that closely matches the teacher model and significantly outperforms industrial baselines like FLUX.1 and SD3.5. In portrait scenes, Moebius attains the highest preference score, surpassing the teacher model and all other compared methods. For real-world object removal, Moebius performs nearly on par with the teacher model and is substantially better than the industrial baselines.

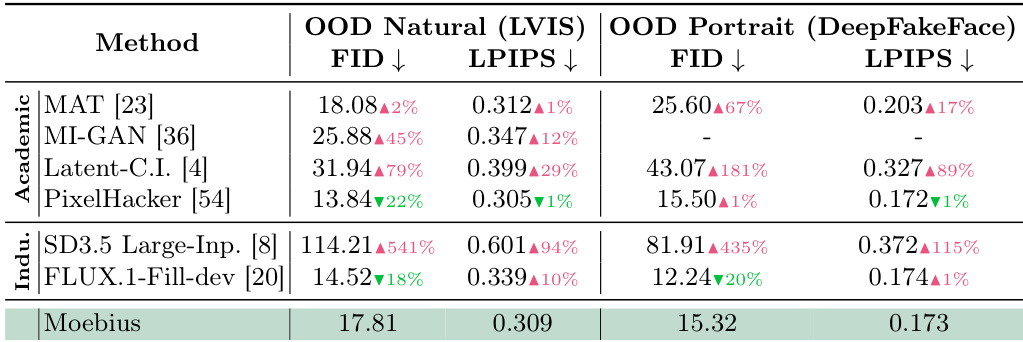
The authors evaluate Moebius against academic and industrial baselines on out-of-distribution natural and portrait tasks. Results indicate that Moebius bridges the performance gap with massive industrial models, achieving competitive fidelity and perceptual quality comparable to both specialized academic methods and large-scale generalists. The method significantly outperforms other industrial baselines that struggle with generalization, while maintaining high stability across diverse domains. Moebius achieves performance comparable to large industrial models and specialized academic methods on out-of-distribution natural and portrait tasks. The proposed method significantly outperforms the SD3.5 industrial baseline, which shows poor generalization and high error rates. Moebius achieves better perceptual quality scores than the FLUX industrial model across both natural and portrait domains.
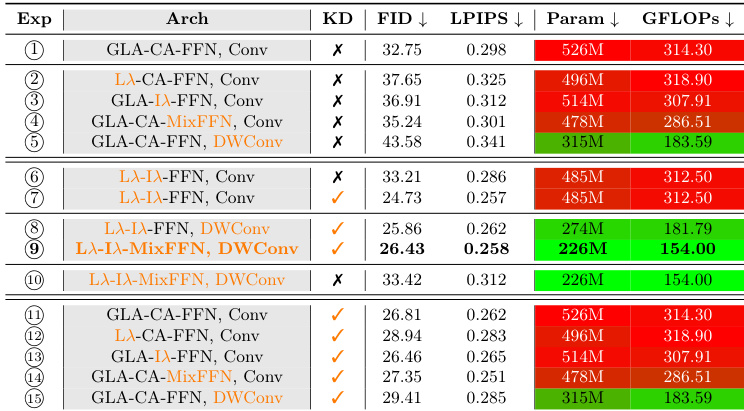
{
"summary": "The experiments evaluate the impact of architectural modifications and knowledge distillation on model efficiency and generation quality. Results demonstrate that knowledge distillation is critical for high performance, as models lacking it exhibit significantly higher error metrics despite similar resource usage. The configuration utilizing L$\lambda$-L$\lambda$-MixFFN with DWConv and knowledge distillation achieves the optimal balance, delivering superior generation quality alongside the lowest parameter count and computational cost.",
"highlights": [
"Knowledge distillation is essential for quality, as models without it suffer significant performance drops despite comparable efficiency.",
"The L$\lambda$-L$\lambda$-MixFFN architecture with DWConv achieves the best performance-efficiency trade-off, outperforming heavier GLA-based models.",
"Lightweight components like DWConv only yield high-quality results when combined with knowledge distillation."
]
}
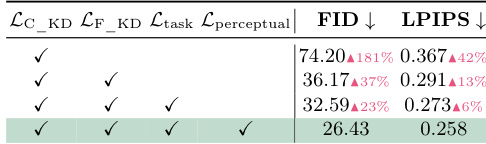
The ablation study evaluates the contribution of different loss functions to the distillation process. Starting with only coarse knowledge distillation results in the worst performance, but progressively adding fine-grained distillation, task loss, and perceptual constraints systematically improves the metrics. The full configuration achieves the best results, validating the multi-granularity optimization strategy. Relying solely on coarse knowledge distillation yields the highest error rates for both FID and LPIPS. Integrating fine-grained distillation and task loss significantly improves generation quality. The complete set of optimization objectives achieves the best performance, confirming the necessity of the multi-granularity approach.
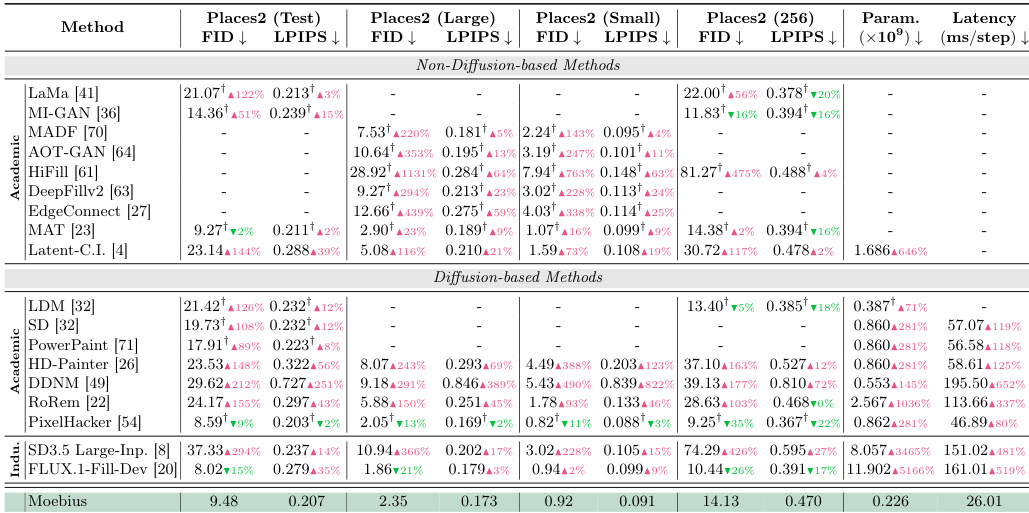
The authors introduce Moebius, a compact inpainting model that achieves superior efficiency and performance compared to both academic specialists and massive industrial generalists. Despite having the fewest parameters and lowest inference latency among all compared methods, the model delivers the best quantitative results across all tested natural scene benchmarks. It effectively bridges the capacity gap with much larger systems, matching their visual fidelity while operating with a fraction of the computational resources. Moebius achieves the highest efficiency metrics, possessing the lowest parameter count and fastest inference speed among all evaluated methods. The model secures the top performance across all Places2 benchmarks, outperforming heavy industrial models and academic baselines in both FID and LPIPS scores. Moebius successfully matches the generation quality of its large teacher model while maintaining a significantly smaller footprint and faster processing time.
The experiments evaluate Moebius through user preference studies, cross-domain benchmarks, and ablation tests to validate its generation quality, generalization capabilities, and architectural efficiency against specialized academic methods and large industrial baselines. Qualitative results indicate that the model successfully bridges the capacity gap with significantly larger systems, delivering visual fidelity and perceptual stability that closely match or exceed the teacher model across natural and portrait scenes. Furthermore, component analysis confirms that knowledge distillation and a multi-granularity optimization strategy are essential for high performance, ultimately establishing Moebius as a highly efficient compact framework that achieves superior results with minimal computational overhead.