Command Palette
Search for a command to run...
تدخلات SAE غير موثوقة: استعادة السلوك المكبوت بعد التدخل
تدخلات SAE غير موثوقة: استعادة السلوك المكبوت بعد التدخل
Mingyue Cui Linghui Shen Xingyi Yang
الملخص
تفكك المشفرات التلقائية المتفرقة (SAEs) تنشيطات مسار الباقي إلى ميزات قابلة للتفسير. تعتمد آليات الدفاع في الفضاء الكامن الحديثة بشكل متزايد على هذه التفككات، بافتراض أن ميزات المشفرات التلقائية المتفرقة (SAE) "غير الآمنة" المُحددة تُعد مقابض قابلة للتنفيذ لأغراض المراقبة والتدخل. في هذا النموذج، يُتوقع أن يمنع تثبيت ميزة ضارة محددة بشكل موثوق سوء سلوك النموذج. ومع ذلك، نوضح أن هذا النجاح قد يخفي نمط فشل قابلاً للاسترداد: فقد يحجب التثبيت مساراً واحداً ظاهراً نحو سلوك معين دون القضاء على السلوك ذاته. نصيغ هذه الثغرة على أنها عملية استرداد ما بعد التدخل، وهي مشكلة تحسين مقيدة في فضاء الباقي. بدءاً من حالة الباقي بعد التدخل، نقوم بتحسين اضطرابات الباقي لاستعادة سلوك ما قبل التدخل مع الحفاظ على القيم بعد التدخل لميزات SAE المستهدفة. وحتى في ظل نموذج تهديد قوي يظل فيه التدخل نشطاً طوال مراحل التحسين والتوليد، يظل الاسترداد ممكناً. واستبعاداً لاحتمال أن يقتصر الاسترداد على مجرد عكس التدخل، نستخدم تحديثات متعامدة مع المشفر للتدخلات أحادية الطبقة، وجاكوبان خريطة الميزات المقابلة في الإعداد عبر الطبقات. وتشير نتائج هذا الاختبار الإجهادي عبر تجارب TPP، والنسيان، و IOI، وتوجيه الرفض، إلى وجود سلوك قابل للاسترداد على الرغم من نجاح التدخل على مستوى الميزات. ولا سيما في إعداد توجيه الرفض الحرج من حيث السلامة، حققنا معدل استرداد بنسبة 95.8% على العينات الصالحة، مع الحفاظ على الانحراف النسبي للميزات المدافعة عند 0.131، وهو ما يقل بشكل كبير عن النماذج الأساسية القائمة على الملحق. ويحدد تحليل نسب مسار الاسترداد هذه الآلية الاستردادية بشكل أدق في باقي إعادة بناء المشفر التلقائي المتفرق، وهو المكون الذي لم يفسره الـ SAE. وتكشف هذه النتائج عن فجوة بين التحكم على مستوى الميزات والاكتمال السلوكي: فبينما يمكن لميزات SAE دعم التدخل السببي، فإن التحكم فيها لا يضمن بالضرورة التحكم في السلوك الكامن.
One-sentence Summary
The authors demonstrate that clamping unsafe sparse autoencoder features cannot reliably suppress harmful model behavior, as residual perturbations can recover targeted actions while preserving the clamped features, a vulnerability they formalize as post-intervention recovery and validate through constrained residual-space optimization using encoder-orthogonal updates and the feature-map Jacobian to expose the fragility of latent-space defense mechanisms.
Key Contributions
- This work identifies a post-intervention recovery vulnerability in Sparse Autoencoder defenses, demonstrating that clamping targeted features often fails to permanently suppress behaviors because models can route around the intervention through unmonitored residual directions.
- The study formulates post-intervention recovery as a constrained residual-space optimization problem that recovers pre-intervention behavior while preserving defended feature values. This framework employs encoder-orthogonal updates for single-layer interventions and feature-map Jacobian projections for cross-layer settings to ensure recovery does not simply reverse the original clamp.
- Evaluations across the TPP, unlearning, IOI, and refusal steering benchmarks demonstrate that this optimization achieves a 95.8% recovery rate in safety-critical steering scenarios while maintaining a defended-feature relative drift of 0.131, which remains substantially below suffix-based baselines. Attribution analysis further localizes the bypass mechanism to the SAE reconstruction residual, highlighting a fundamental gap between feature-level control and behavioral completeness.
Introduction
Sparse autoencoders (SAEs) are increasingly deployed to decompose neural network activations into interpretable features, enabling latent-space safety interventions that clamp harmful signals to steer model behavior. This approach matters for AI alignment because it promises a direct, feature-level mechanism for monitoring and suppressing undesirable outputs. However, prior defenses operate under the assumption that fixing targeted features guarantees behavioral control, neglecting how models can redistribute causal information across correlated directions or conceal it within unexplained reconstruction residuals. The authors introduce post-intervention recovery as a diagnostic framework to stress-test this assumption. By formulating the challenge as a constrained optimization problem, they systematically search for residual perturbations that restore suppressed behaviors while keeping defended features fixed. Their results across multiple steering and unlearning benchmarks demonstrate that models frequently bypass clamps through null-space updates, revealing a fundamental gap between feature-level control and complete behavioral safety.
Dataset
- The provided text contains only author names, affiliations, and contact details, with no dataset information included.
- Please share the relevant paper paragraphs covering dataset composition, sources, filtering rules, processing steps, and model usage so I can draft the requested description.
Method
The authors propose a diagnostic framework to evaluate whether sparse autoencoder (SAE) feature interventions function as complete behavioral bottlenecks or merely local causal handles. The approach centers on a post-intervention recovery mechanism that tests whether suppressed behaviors can be restored while maintaining an active feature clamp. At the core of the architecture is a transformer language model M equipped with an SAE at layer ℓ. The SAE encodes the residual stream activations hℓ(x)∈RT×d into sparse latent features zℓ(x) via an encoder Eℓ, and reconstructs the activation through a decoder Dℓ:
zℓ(x)=Eℓ(hℓ(x)),h^ℓ(x)=Dℓ(zℓ(x)).The coordinates of zℓ(x) represent distinct SAE features, enabling precise isolation and manipulation of specific latent dimensions.
To enforce behavioral suppression, the framework implements a feature-level intervention that selects a target feature set S and clamps their activations to defended values cS. Rather than discarding the reconstruction error, the method preserves the SAE reconstruction residual to maintain model continuity. The defended residual state is computed as:
hℓdef(x)=Dℓ(clampS(zℓ(x);cS))+(hℓ(x)−h^ℓ(x)).This formulation ensures that the clamped features remain fixed at cS while the unexplained residual component continues to propagate through the network. The evaluation protocol restricts recovery testing to a valid flip set, which contains only input sequences where the base model exhibits the target behavior but the clamped intervention successfully suppresses it. This conditioning guarantees that recovery is measured exclusively when a suppressed behavior exists to be restored.
The recovery process searches for a constrained perturbation δx that, when added to the defended state, restores the target behavior without violating the clamp. To attribute the source of successful recovery, the authors introduce a recovery-path decomposition module. Both the defended state hℓdef(x) and the recovered state hℓrec(x)=hℓdef(x)+δx are encoded by the SAE to compute the feature-level change δz. The framework then partitions δz into replayable components, including clamped refusal features, non-clamped SAE features, and the top-k non-clamped features ranked by absolute activation change. The remaining portion of the perturbation is isolated as the unexplained residual component:
δres=δx−(Dℓ(Eℓ(hℓrec(x)))−Dℓ(Eℓ(hℓdef(x)))).Each component is subsequently replayed as an additive residual perturbation under the original active clamp to quantify its individual contribution to behavioral restoration.
As shown in the figure below:
 The decomposition results demonstrate that recovery is predominantly concentrated within the SAE reconstruction residual rather than in the clamped features or a narrow subset of alternative latents. Because SAE decoder directions are not strictly orthogonal, the framework avoids interpreting component norms as variance fractions. Instead, it relies on behavioral replay and knockout experiments to establish robust attribution evidence. This structured decomposition allows the authors to systematically isolate how information bypasses the active clamp and restores the target behavior.
The decomposition results demonstrate that recovery is predominantly concentrated within the SAE reconstruction residual rather than in the clamped features or a narrow subset of alternative latents. Because SAE decoder directions are not strictly orthogonal, the framework avoids interpreting component norms as variance fractions. Instead, it relies on behavioral replay and knockout experiments to establish robust attribution evidence. This structured decomposition allows the authors to systematically isolate how information bypasses the active clamp and restores the target behavior.
Experiment
For larger feature sets, the clamp increasingly enters a broad side-effect regime in which base-like recovery drops, consistent with the defended state becoming more degraded rather than recovery paths disappearing.
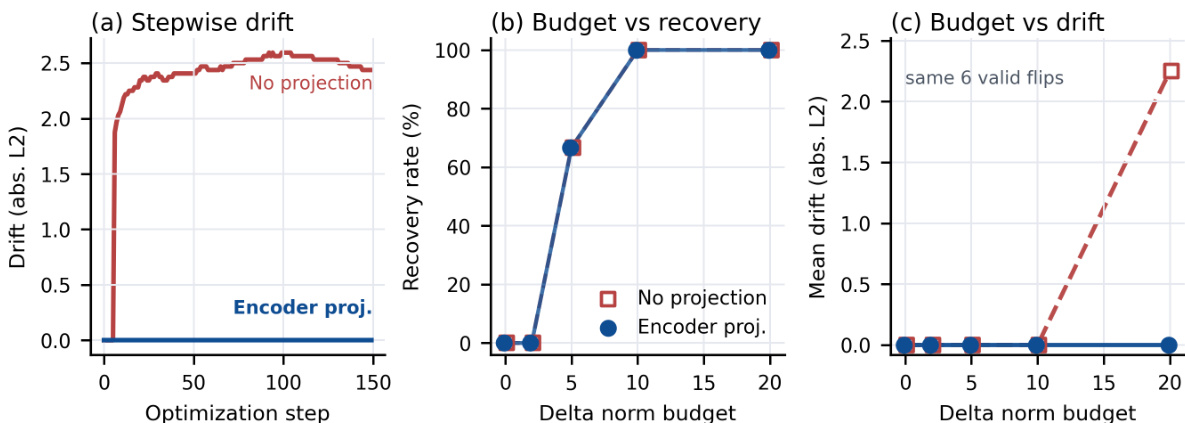
the figure: Budget and optimization diagnostics for unlearning recovery. the paper evaluate a small matched strict WMDP slice of six valid answer-choice flips under the same SAE clamp and post-hoc evaluator. (a) During optimization, encoder-projected recovery keeps choice-readout defended-feature drift at zero, while unconstrained recovery rapidly increases drift. (b) Recovery improves with the perturbation budget: encoder-projected recovery reaches 4/6 at budget 5 and 6/6 at budget 10. (c) Increasing the budget does not force defended-feature drift under the encoder projection; drift remains zero even at budget 20, whereas unconstrained recovery reaches mean drift 2.25 at the same budget
the figure: Refusal recovery across feature-set sizes. Left: broader SAE feature clamps affect more prompts, increasing the number of K-specific valid cases. For K≥30, the shaded region marks the relaxed valid/refusal judge used to count safety-cue and negative/degenerate openings as clamp-induced suppression. Right: non-refusal recovery remains high across the sweep, while base-answer fidelity decreases as the clamp becomes broader. The broad-K behavior is a side-effect regime consistent with capability and over-refusal trade-offs reported for SAE refusal steering.

the table: Refusal recovery across feature-set sizes. Each row recomputes the valid set induced by that specific K-feature clamp. Recovery remains high in the stable K=5–20 range, so the phenomenon is not explained by an obviously tiny feature set. For larger K, base-like recovery decreases as the clamp enters a broad side-effect regime.
the table: Experimental details for reproducing the main recovery results. The the table summarizes the essential configuration for each experiment; full command lines and logs are provided in the supplemental material.
- K Experimental Details and Compute Resources
Experimental details. the table summarizes the model, SAE release, intervention target, recovery objective, and evaluator used in each experiment. Exact script paths and configuration files are included in the supplemental material.
Compute resources. All experiments use frozen language models and frozen SAEs. the paper do not train new language models or new SAEs; the reported experiments optimize only per-example recovery perturbations or soft suffix baselines.
- L Limitations
the results are not a universal impossibility result for SAE-based interventions. the paper claim that recovery paths exist in the evaluated settings, not that every possible SAE intervention must be recoverable. They are feature-selection and SAE-release dependent: the tested defenses act on selected SAE features in specific dictionaries and model settings. Different SAE objectives, denser dictionaries, broader multi-layer clamps, or interventions trained explicitly against post-clamp recovery may change the observed trade-offs.
the table: Approximate compute resources for the reported experiments. Runtime varies with batching and cluster availability; the values are intended to document the scale needed to reproduce the reported diagnostics.
the recovery procedure is a white-box diagnostic rather than a black-box attack. It assumes access to internal activations and gradients and optimizes per-input residual perturbations. This is appropriate for testing intervention completeness, but it should not be interpreted as a directly deployable jailbreak.
Finally, the refusal case study uses a strict valid-filtering protocol, which improves interpretability but leaves a relatively small main set of clean recovery examples. Therefore, broader evaluation across models, prompts, clamp strengths, and SAE releases is needed to determine the full scope of the phenomenon.
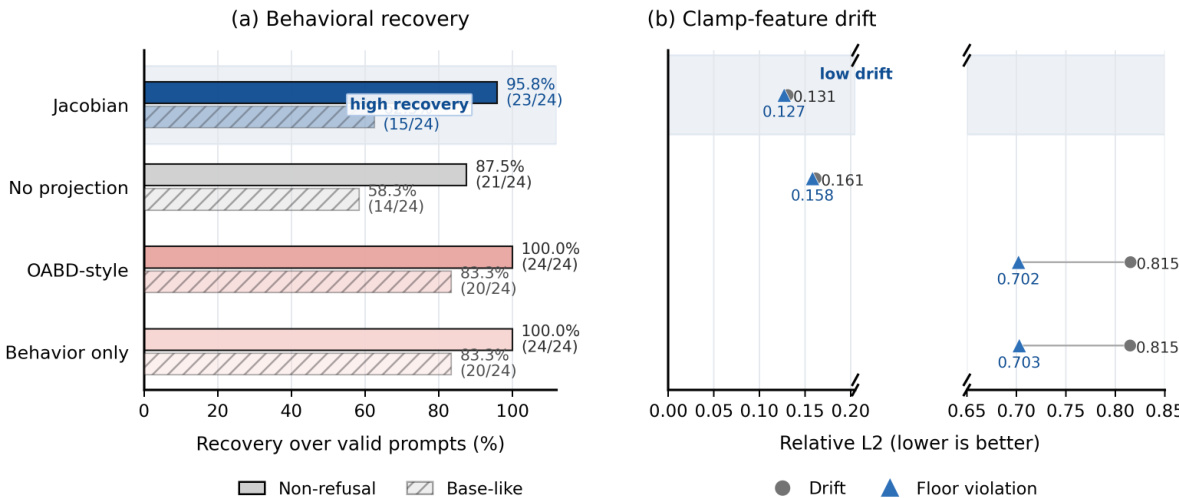
The the the table compares recovery metrics on the AdvBench and HarmBench-Test datasets, showing high non-refusal recovery rates alongside low feature drift. The authors demonstrate that non-refusal behavior can be largely restored from the defended residual state even when the active SAE clamp remains enforced. This recovery occurs with minimal movement of the defended feature state, indicating that the intervention does not form a complete behavioral bottleneck. Non-refusal behavior is successfully restored for the vast majority of strict-valid examples across both evaluated datasets. The recovery process maintains the defended feature state close to its clamped values, indicating minimal activation drift. Attribution analysis reveals that recovered behavior is primarily carried by the SAE reconstruction residual rather than visible SAE features.

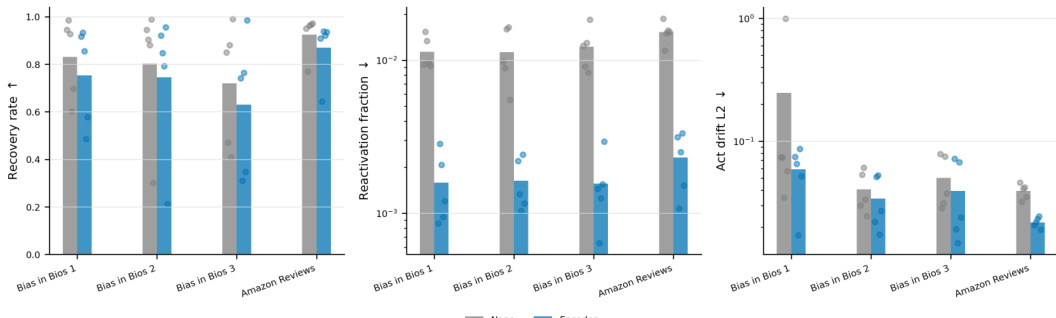
The authors evaluate post-intervention recovery across multiple datasets to test whether targeted sparse autoencoder features can be fully suppressed without enabling behavioral restoration. Results indicate that while encoder-orthogonal recovery maintains a high rate of behavioral restoration, it significantly reduces the reactivation of defended features and their associated activation drift. This demonstrates that recovery paths persist even when updates are constrained to avoid the clamped feature directions. Encoder-orthogonal recovery maintains high behavioral restoration while minimizing feature reactivation. Activation drift is consistently reduced when updates are constrained away from defended encoder directions. Recovery without feature reopening increases significantly under encoder-projected optimization.

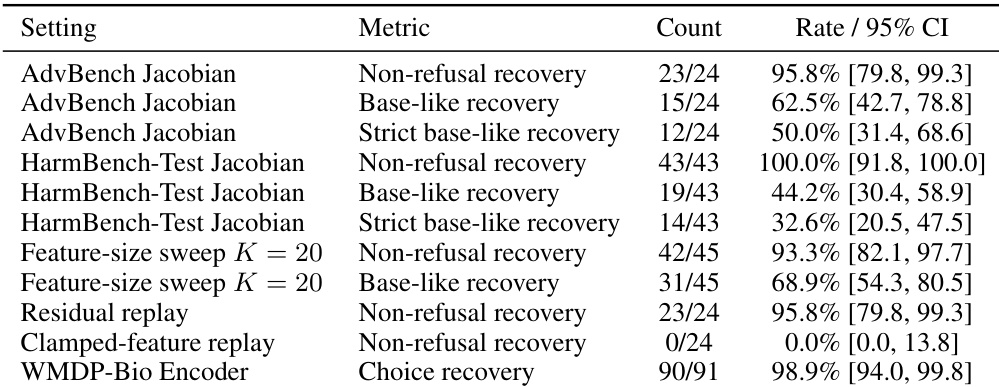
Results show that clamping safety-associated SAE features does not completely eliminate a model's underlying capacity to generate non-refusal responses. The recovered behavior is primarily facilitated by the SAE reconstruction residual rather than by reactivating the targeted features or other visible latents. Furthermore, the recovery optimization successfully maintains the integrity of the defended feature state, resulting in minimal drift and floor violations. The SAE reconstruction residual serves as the dominant pathway for behavioral recovery, effectively bypassing the suppressed feature set. Reactivation of clamped features and compensation through other visible SAE latents contribute negligibly to the restored behavior. The recovery process effectively preserves the defended feature-state, maintaining consistently lower drift and floor violation levels compared to unconstrained approaches.
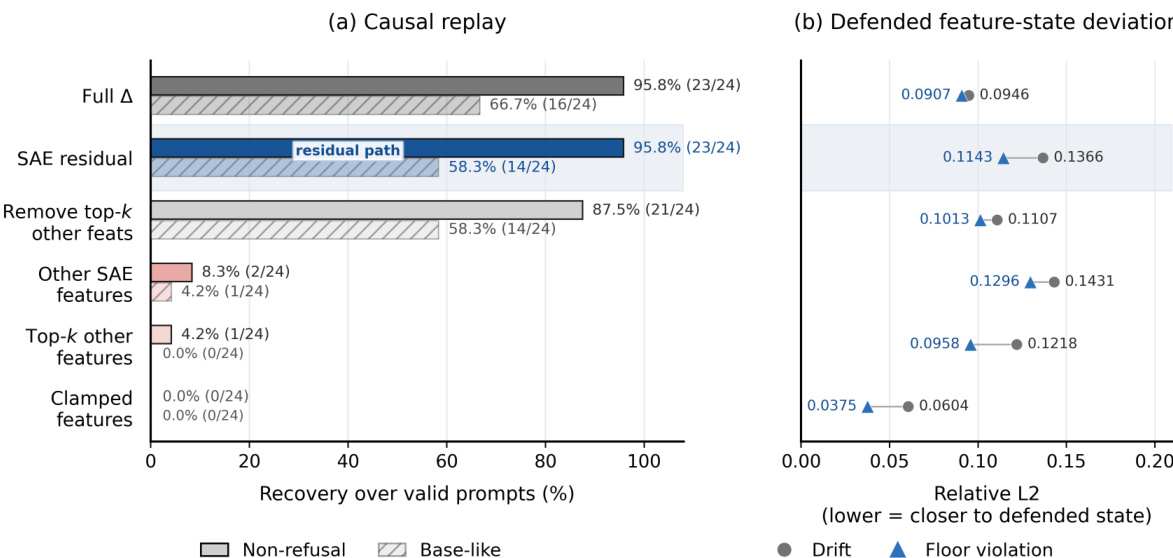
The authors evaluate post-intervention recovery across multiple experimental settings to test whether sparse autoencoder feature clamping functions as a complete behavioral bottleneck. Results demonstrate that target behaviors can be successfully restored from the defended residual state even when optimization updates are constrained to prevent the reactivation of clamped features. This recovery pattern holds consistently across latent, output, and circuit-level tasks, with attribution analysis indicating that the SAE reconstruction residual primarily carries the restored behavior. Projected recovery methods successfully restore target behaviors across latent, output, and circuit-level tasks while maintaining minimal defended-feature drift. Behavioral recovery remains robust across varying perturbation budgets and feature-set sizes, indicating that clamping does not eliminate all underlying computational pathways. Attribution analysis reveals that the SAE reconstruction residual serves as the dominant carrier for recovered behavior, bypassing the need to reactivate clamped or alternative visible features.

The experiments demonstrate that targeted sparse autoencoder feature clamping does not completely eliminate model behaviors, as suppressed responses can be effectively restored through post-intervention optimization. Recovery is primarily driven by the SAE reconstruction residual rather than by reactivating the clamped features or compensating through other visible latent directions. Consequently, SAE interventions serve as partial causal handles but fail to establish complete behavioral bottlenecks across various benchmarks and settings. Recovery rates for non-refusal outputs remain consistently high across multiple benchmarks, whereas attempts to recover behavior by replaying only the clamped features result in complete failure. The the the table indicates that base-like and strict base-like recovery metrics are generally lower than non-refusal recovery, suggesting that while the targeted behavior can be restored, it often deviates from the original response format. Results across different feature-size sweeps and replay conditions demonstrate that behavioral restoration is robust and primarily relies on the SAE reconstruction residual rather than the clamped latent directions.
The experiments evaluate post-intervention behavioral recovery across multiple benchmarks, optimization constraints, and feature-set configurations to validate whether clamping safety-associated sparse autoencoder features creates a complete behavioral bottleneck. Results consistently demonstrate that targeted suppression does not eliminate underlying computational pathways, as models successfully restore non-refusal and other target behaviors through the SAE reconstruction residual rather than reactivating clamped latents or compensating through visible directions. This recovery process maintains minimal activation drift and preserves the integrity of the defended feature state across diverse experimental settings. Ultimately, the findings indicate that SAE interventions function as partial causal handles that effectively modulate but cannot fully constrain model behavior.