Command Palette
Search for a command to run...
JoyAI-VL-Interaction: ذكاء التفاعل البصري-اللغوي في الزمن الحقيقي
JoyAI-VL-Interaction: ذكاء التفاعل البصري-اللغوي في الزمن الحقيقي
الملخص
لا تنتظر العديد من اللحظات في العالم الحقيقي من المستخدم أن يطرح سؤالاً. فقد يشتعل حريق على شاشة مراقبة أمنية، أو تومض تعابير وجه عبر مكالمة فيديو، أو يمر منتج يريده المشاهد بسرعة في بث مباشر. ومع ذلك، تظل النماذج الكبيرة اليوم قائمة في الغالب على نظام تبادل الأدوار بالتصميم: فهي تجيب فقط عند مخاطبتها، وحتى تطبيقات مكالمات الفيديو التي تبدو تفاعلية لا تزال تعمل كنظم سؤال وجواب، ولا تتفاعل إلا عند الاستفسار أو التوجيه. ندعو إلى نموذج مختلف: نموذج يكون حاضرًا في العالم كما هو الحال مع الشخص. فهو يراقب باستمرار ما يحدث في الوقت الراهن، ويقرر بمفرده ما إذا كان سيتحدث أم سيصمت، ويتفاعل في الزمن الحقيقي، ويحوّل المهمة إلى نموذج خلفي عندما تكون المشكلة معقدة. وتسهيلاً لتطوير نماذج التفاعل واعتمادها عبر مختلف المجالات، نقدم مساهمتين مفتوحتي المصدر بالكامل. أولاً، نطلق نموذج JoyAI-VL-Interaction، وهو نموذج تفاعل بصري-لغوي (VL-interaction) بحجم 8 مليار معلمًا، يعتمد على الرؤية كأولوية. ويتخذ النموذج قرار الاستجابة داخليًا، حيث يختار كل ثانية ما بين الصمت أو الرد أو التحويل إلى نموذج خلفي، ويتفوق في الاستجابة المحفزة بصريًا والوعي الزمني. ونقترن ذلك بوصفة تدريب قابلة للنقل، حيث تظهر قدرات لم نقم بتدريب النموذج عليها صراحةً، مثل توجيه مستخدم للتسوق عبر شاشات تطبيق متغيرة، أو إلقاء محاضرة بشكل عفوي بناءً على عرض شرائح. ثانيًا، نطلق نظامًا كاملاً وقابلًا للنشر مُصممًا حول ذلك النموذج. حيث يقوم النظام ببث أي فيديو جاري إلى النموذج، مما يجعله حاضرًا فعليًا في العالم. وتعد جميع المكونات الأخرى قابلة للتوصيل والإضافة، بما في ذلك وحدات ASR/TTS، والذاكرة، وواجهة المستخدم المرئية، وعقل خلفي يمكنه الاتصال بأي واجهة برمجة تطبيقات (API) أو agent. وفي ستة سيناريوهات واقعية، فضّل المقيّمون البشر نموذج JoyAI-VL-Interaction على مساعدي مكالمات الفيديو المدمجين في تطبيقَي Doubao و Gemini بهامش واسع. وإلى علمنا، يُعد هذا أول نموذج تفاعل مدفوع بالرؤية ومفتوح المصدر يُطلق مع وصفة التدريب الخاصة به، والبيانات، والنظام الكامل القابل للنشر.
One-sentence Summary
The authors introduce JoyAI-VL-Interaction, an 8B-scale vision-language interaction model that continuously monitors visual environments and autonomously decides when to respond, replacing turn-based architectures with a proactive, real-time paradigm that delegates difficult tasks to a background model to enable a watch-and-do collaboration mode aligned with embodied intelligence.
Key Contributions
- The paper introduces JoyAI-VL-Interaction, an 8B-scale vision-first model that replaces turn-based querying with a proactive, event-driven paradigm that decides whether to respond every second. This architecture unifies real-time responsiveness, continuous temporal memory, and autonomous speech generation within a single system.
- A fully open-sourced deployment stack is released that pairs the model with time-aligned data and a modular framework engineered for sustained real-time presence, serving, memory, and background task delegation.
- Evaluations across streaming scenarios demonstrate that this vision-driven approach provides practical advantages for live applications such as security monitoring, automated narration, and step-by-step guidance compared to traditional polled systems.
Introduction
The authors leverage a continuous interaction paradigm to address the critical need for AI systems that operate proactively rather than waiting for explicit user prompts. Current large models and consumer applications remain structurally turn-based, relying on conversational turn-taking or external polling cycles that cannot react to spontaneous, time-sensitive events. Existing streaming video research similarly isolates individual capabilities like latency or memory without providing a cohesive framework for sustained real-world deployment. To bridge this gap, the authors introduce JoyAI-VL-Interaction, an 8B vision-first model that learns to autonomously decide each second whether to respond, remain silent, or delegate complex tasks to a background processor. They pair this architecture with a fully open-source, modular system that supports sub-second latency streaming and asynchronous reasoning, enabling genuine event-driven assistance that aligns with the demands of embodied intelligence.
Method
The authors present JoyAI-VL-Interaction, a vision-language model designed for real-time streaming video. Unlike conventional turn-based models, this system operates in a continuous loop, evaluating the visual stream every second to determine the next action. The model is capable of three distinct behaviors: providing a timely warning, maintaining sustained commentary, or delegating a complex task to a background model.

As illustrated in the interaction diagram, the model handles various scenarios such as detecting a fire in a live stream, recreating a mobile app screen in HTML, or commentingating on an art video. When the model decides to delegate, it passes the task to an asynchronous background brain, allowing the main loop to continue processing the live stream while the background task is resolved. This design establishes a "watch-and-do" premise where the model observes the physical world and delegates actions in the digital world.
The core architecture is built upon JoyAI-VL 1.0, which initializes the language model from Qwen3-8B and the visual encoder from Qwen3-VL ViT. To manage the computational load of unbounded video streams, the model utilizes a native streaming video codec called AdaCodec. This codec employs a predictive coding strategy to minimize token usage by transmitting only what prediction cannot explain.

As shown in the figure below: the encoding process distinguishes between reference frames and predictable frames. In the first round, a full RGB frame is processed by a ViT to generate 256 visual tokens. In subsequent rounds, the system processes residuals and motion vectors using a P-Tokenizer, which generates only 16 visual tokens. This approach reduces the token count by approximately 16 times for predictable frames, ensuring that the computational budget scales with scene changes rather than frame count.
The system architecture is designed to decouple the autonomous decision-making core from interchangeable input and output components.
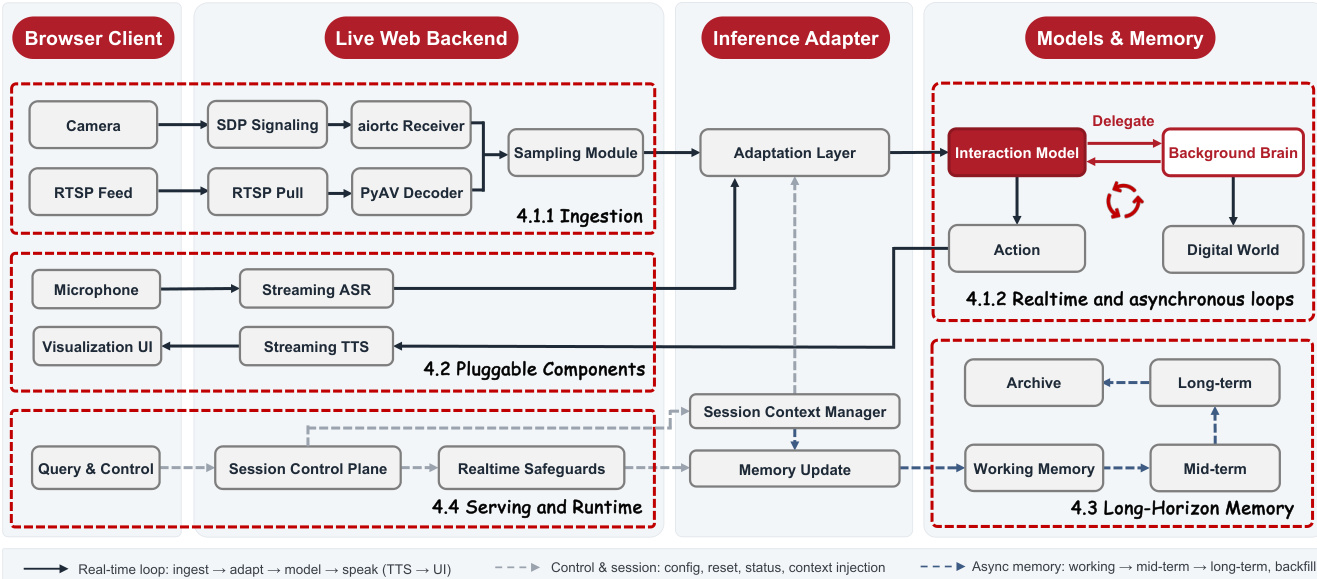
Refer to the system overview which details the Browser Client, Live Web Backend, Inference Adapter, and Models & Memory modules. The system runs two concurrent loops: a real-time loop with the user and an asynchronous loop with the background brain. The ingestion module samples the video stream at a fixed interval, typically 1 Hz, and passes it to the interaction model. The system also incorporates a hierarchical long-horizon memory to maintain context over hours of streaming, organized into short-term, mid-term, and long-term tiers.
The training process begins with continue training using a mixed corpus of time-aligned interaction data and conventional turn-based data. To address the class imbalance where silence steps vastly outnumber response steps, the authors employ a weighted cross-entropy loss. The objective function assigns different weights to silence and response tokens:
L(θ)=−∣A∣1i∈A∑wjlogpθ(yj∣y<j).Specifically, repeated silence tokens are down-weighted, while response onsets are up-weighted. Following supervised fine-tuning, the model undergoes reinforcement learning using the GRPO algorithm. This stage optimizes the per-second policy against stream-level rewards, encouraging correct timing, appropriate silence, and effective delegation.
Experiment
The evaluation compares the compact JoyAI-VL-Interaction model against mature, turn-based video-call assistants from Doubao and Gemini across six event-driven scenarios that validate real-time operation, proactive response, and long-horizon memory. Human assessments reveal that the interaction model consistently outperforms the baselines, particularly in time-sensitive tasks where timely and context-aware engagement is critical. While the larger baseline systems frequently exhibit delayed reactions, erratic triggering, or premature session cutoffs, the proposed architecture natively internalizes timing decisions and seamlessly delegates complex subtasks to background processes. These qualitative results confirm that treating interactivity as a core architectural capability allows a smaller model to surpass significantly larger turn-based products in live streaming environments, with emergent behaviors further validating the approach.
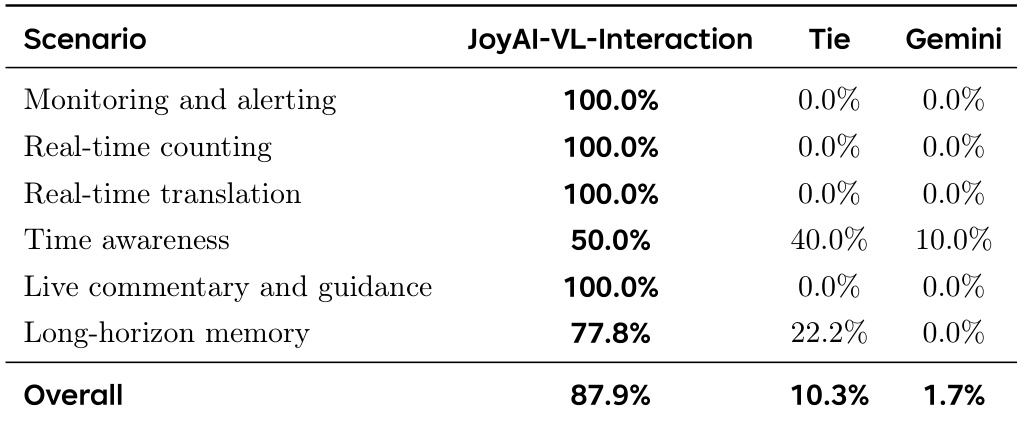
The authors evaluate JoyAI-VL-Interaction against the Gemini assistant across six event-driven scenarios. JoyAI-VL-Interaction demonstrates a decisive advantage, winning the overwhelming majority of comparisons. The model excels in tasks requiring immediate, proactive responses, achieving a perfect record in several categories, while Gemini struggles to win outside of specific time-based tasks. JoyAI-VL-Interaction achieves a perfect win rate against Gemini in scenarios requiring immediate reaction, including monitoring, real-time counting, translation, and live commentary. The time awareness scenario is the most contested, with JoyAI winning half the cases and Gemini securing a minority of wins. JoyAI-VL-Interaction maintains a strong lead in long-horizon memory tasks, winning the majority of comparisons while Gemini wins none.
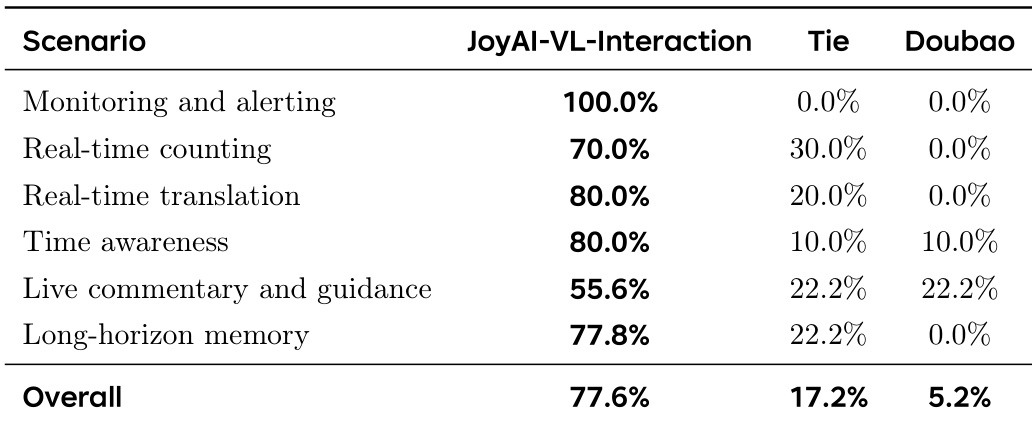
The evaluation shows JoyAI-VL-Interaction significantly outperforming the Doubao baseline in most event-driven scenarios. The proposed model demonstrates superior capabilities in real-time tasks like monitoring, translation, and memory, while the baseline only shows limited competitiveness in live commentary. JoyAI-VL-Interaction achieves a dominant performance in monitoring and alerting scenarios. The model maintains a strong lead over the baseline in real-time translation and counting tasks. Although the baseline model shows some presence in live commentary, JoyAI-VL-Interaction secures a significant overall advantage.
The evaluation compares JoyAI-VL-Interaction against leading commercial assistants across multiple event-driven scenarios to assess its real-time responsiveness and contextual memory capabilities. Qualitative analysis reveals that the model consistently outperforms its counterparts, particularly in tasks demanding immediate reactions, continuous monitoring, and long-horizon information retention. While baseline systems show only limited competitiveness in specific time-sensitive categories, JoyAI-VL-Interaction demonstrates a decisive advantage in proactive interaction and sustained contextual awareness. These results confirm the model's superior alignment with dynamic interaction requirements.