Command Palette
Search for a command to run...
FastContext: تدريب مستكشف مستودعات فعال لـ Coding Agents
FastContext: تدريب مستكشف مستودعات فعال لـ Coding Agents
Shaoqiu Zhang Maoquan Wang Yuling Shi Yuhang Wang Xiaodong Gu Yongqiang Yao Rao Fu Shengyu Fu
الملخص
حققت وكلاء البرمجة (LLM coding agents) نتائج متميزة في مهام هندسة البرمجيات، غير أن استكشاف المستودع يظل عنق زجاجة رئيسي: إذ يستهلك تحديد الكود ذي الصلة ميزانية كبيرة من الـ token ويُلوث سياق الـ agent بشظايا غير ذات صلة. في معظم الـ agents، يستكشف النموذج نفسه المستودع ويحل المهمة، تاركةً عمليات القراءة والاستكشاف والبحث في سجل المحل. نقدم FastContext، وهو وكيل فرعي مخصص للاستكشاف يفصل بين استكشاف المستودع والحل. وعند الاستدعاء عند الطلب، يصدر FastContext استدعاءات لأدوات متعددة بشكل متوازٍ، ويعيد إرجاع مسارات الملفات والنطاقات الخطية بشكل موجز كسياق مركّز. يعتمد FastContext في تشغيله على نماذج استكشاف متخصصة تتراوح بين 4B--30B معلمة. نقوم بتهيئتهم انطلاقاً من مسارات نماذج مرجعية قوية، ونقوم بتحسينها باستخدام مكافآت مستندة إلى المهمة لدعم البحث الواسع في الدور الأول، وجمع الأدلة عبر أدوار متعددة، وتوليد الاستشهادات بدقة. عبر SWE-bench Multilingual و SWE-bench Pro و SWE-QA، يؤدي دمج FastContext في Mini-SWE-Agent إلى تحسين معدلات الحل الشامل بنسبة تصل إلى 5.5%، مع تقليل استهلاك الـ token الخاص بـ coding-agent بنسبة تصل إلى 60%، وذلك مع عبء هامشي. تُظهر هذه النتائج أنه يمكن فصل عملية استكشاف المستودع عن عملية الحل، وأن التعامل معها بفعالية يمكن أن تقوم به نماذج متخصصة. الكود والبيانات: https://github.com/microsoft/fastcontext
One-sentence Summary
FastContext, a dedicated exploration subagent for coding agents, separates repository exploration from solving by using specialized 4B–30B parameter models trained with task-grounded rewards to issue parallel tool calls and return concise file paths and line ranges, improving end-to-end resolution rates up to 5.5% and reducing token consumption up to 60% across SWE-bench Multilingual, SWE-bench Pro, and SWE-QA.
Key Contributions
- FastContext is introduced as a dedicated exploration subagent that decouples repository exploration from the solving LLM by issuing parallel tool calls and returning concise file paths and line ranges as focused context.
- Specialized exploration models (4B–30B parameters) are bootstrapped from strong reference-model trajectories and refined with task-grounded rewards for broad first-turn search, multi-turn evidence gathering, and precise citation generation.
- Integrating FastContext into Mini-SWE-Agent improves resolution rates up to 5.5% and reduces coding-agent token consumption up to 60% on SWE-bench Multilingual, SWE-bench Pro, and SWE-QA, demonstrating that repository exploration can be effectively separated and handled by specialized models.
Introduction
Coding agents that autonomously navigate and modify large codebases are a fast-moving frontier in software engineering, with benchmarks like SWE-bench demanding repository-scale exploration before any fix or answer can be produced. However, existing systems either keep exploration tangled inside a monolithic agent trajectory, rely on expensive graph construction or proprietary subagent designs, or produce overly broad context that burdens the main solver with noise and high token costs. The authors introduce FastContext, a lightweight, trainable exploration subagent that decouples repository search from the main agent. FastContext uses parallel read-only tool calls to return concise file paths and line ranges, and is trained via supervised fine-tuning and task-grounded reinforcement learning on models from 4B to 30B parameters. When integrated into Mini-SWE-Agent, it boosts end-to-end resolution rates by up to 5.5% while cutting main-model token usage by up to 60% across multilingual and professional-grade benchmarks.
Dataset
The authors construct two training corpora from public software-engineering tasks and repositories, plus a fixed evaluation subset.
-
Supervised fine-tuning (SFT) corpus: 2,954 examples generated from Sonnet 4.6 exploration traces, serialized with READ, GLOB, and GREP tool schemas. It contains three subsets:
- parallel_toolcalls (990 examples): first-turn tool calls issued simultaneously, covering diverse signals such as path patterns, symbols, and entry points.
- multiturn_traj (983 examples): full exploration trajectories filtered to keep those with a final assistant message and at least one assistant–tool interaction; only role, content, tool-call arguments, and raw tool observations are retained.
- linerange (981 examples): final citation generation, where the model learns to output a narrow
<final_answer>block with file paths and line ranges given the query and retrieved file contents. Filtering ensures tool calls use the runtime tool set and final answers fit the required file-line format. Before prompt construction, the top-level directory listing of each task workspace is recorded and inserted into the explorer system prompt alongside the workspace path.
-
Reinforcement learning (RL) corpus: 400 prompts across 395 repositories. Each example includes a two-message input (explorer system instruction and user query), metadata with workspace and instance ID, and a label field derived from the reference patch. The label is built by parsing the patch, skipping newly created files (old-side hunk starts at line 0), and converting remaining hunks into target file paths and old-file line ranges. Labels average 11.07 citation ranges per prompt (min 1, max 68) and are used only for reward computation, not as teacher-forced continuations.
-
Evaluation subset: A fixed 200-instance SWE-bench Pro subset, released as a JSONL file.
How the paper uses the data: The SFT corpus is used for supervised fine-tuning to initialize the explorer policy. The RL corpus is then used for task-grounded policy refinement, where rollouts are scored against the patch-derived labels. During RL, the explorer runs with the same READ, GLOB, and GREP tools; tool observations are appended to the conversation, and multiple concurrent tool calls are allowed. Rollouts are limited to 8 model turns, with a final instruction to stop exploring and return the best answer. For the 4B model, 16 trajectories are sampled per prompt with temperature 1.0, rollout context length 65,536 tokens, and SGLang context length 128K.
Method
The authors presentFastContext, a dedicated exploration subagent designed to separate repository exploration from the main agent's issue-solving process. In standard coding agents, the same model handles both exploration and solving, which often results in the solver's context being polluted with irrelevant snippets and excessive token consumption. FastContext addresses this by acting as a lightweight delegation mechanism. When the main coding agent requires repository context, it issues a context query to FastContext. The subagent explores the target repository using read-only tools and returns compact file-line evidence, allowing the main agent to proceed with editing and testing without retaining the lengthy exploratory history.
As shown in the figure below:
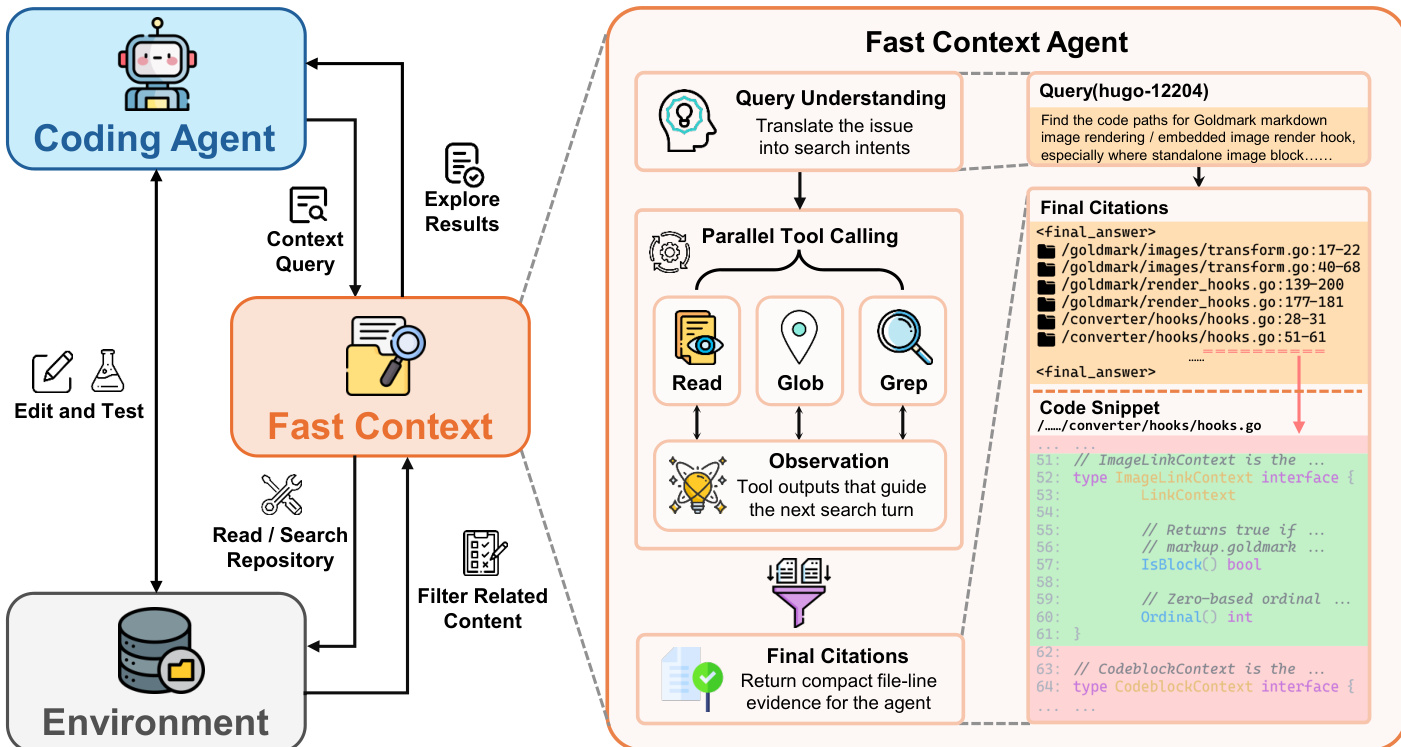
The internal architecture of FastContext is structured around query understanding, parallel tool calling, and evidence synthesis. The subagent deliberately exposes only three language-agnostic tools: READ for retrieving line-numbered file contents, GLOB for path discovery, and GREP for regex-based text search. At each turn, the explorer can issue one or more tool calls or stop with a final evidence list. Crucially, multiple tool calls within the same turn are executed in parallel, enabling the explorer to cover complementary hypotheses efficiently before synthesizing the observations. The output contract is a compact final answer block containing file paths and line ranges, optionally followed by short relevance notes. This format ensures the explorer's output is directly consumable as focused context for the main agent.
To train the specialized exploration models, the authors employ a two-stage training recipe. The first stage is supervised fine-tuning (SFT) to initialize exploration behavior. The authors utilize Qwen-family backbones, specifically Qwen3-4B-Instruct and Qwen3-Coder-30B-A3B, training them for 3 epochs using the Slime/Megatron stack with assistant-token-only loss masking.
Since SFT imitation does not directly optimize whether the final citations cover the code locations necessary to solve the issue, the authors refine the explorer with task-grounded reinforcement learning (RL). They construct a dataset from issue-resolution tasks with reference patches, parsing the patches into target file-and-line ranges to serve as exploration labels. The model is rolled out as the actual FastContext subagent, interacting with the tools for a bounded number of turns. The reward function is deterministic and tied to the output contract, combining patch-derived localization accuracy, a bonus for structured parallel exploration, and penalties for invalid outputs. Let Gf and Gl denote the target file and line sets induced by the reference patch, and let Pf and Pl denote the corresponding sets parsed from the model's final citations. The scalar reward is defined as:
R=task outcomeF1(Pf,Gf)+F1(Pl,Gl)+parallelrparallel−penaltyrformat.Here, the task-outcome term represents the sum of file-level and line-level F1 scores after path normalization. The authors initialize the RL stage from the SFT checkpoint and optimize the policy using GRPO, sampling multiple trajectories per prompt to align the model with the practical goal of returning a minimal citation set that highlights the most relevant code regions.
Experiment
The evaluation spans end-to-end agent benchmarks (SWE-bench Multilingual, SWE-bench Pro, and SWE-QA) with Mini-SWE-Agent and frontier main models, plus a standalone patch-localization test on SWE-bench Verified. FastContext is a read-only exploration subagent that decouples repository search from the main solver, returning compact file-and-line citations; trained 4B–30B explorers using SFT and RL are compared against direct solving and same-model exploration. Results show that FastContext consistently improves resolution accuracy while reducing main-agent token consumption by up to 60%, with the RL-trained 4B explorer often outperforming larger SFT variants and narrowing evidence toward patch-relevant code regions. Standalone localization confirms that trained explorers recover edited locations more precisely, validating that task-grounded RL can produce small, efficient exploration subagents.
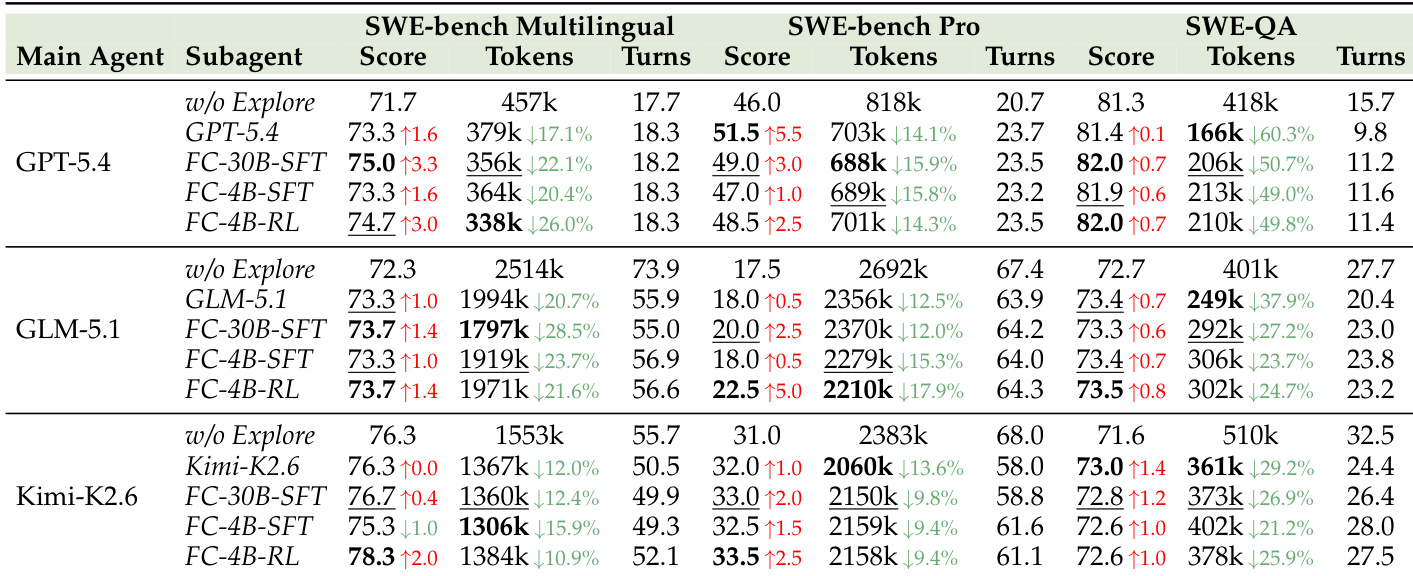
The authors conduct a token and cost audit for the main agent run on the SWE-bench Multilingual benchmark to evaluate the overhead of the exploration subagent. Results show that integrating the compact explorer significantly reduces the main agent's token consumption and API costs. Even when accounting for the subagent's own token usage and estimated API cost, the augmented system achieves a substantial net saving compared to direct solving. The main agent's token usage per task decreases notably when augmented with the compact explorer compared to direct solving. The API cost for the main agent drops significantly in the augmented setting, outweighing the minimal cost incurred by the explorer subagent. The total system cost remains lower than the direct solving baseline, demonstrating that the exploration subagent adds negligible overhead while providing efficiency gains.
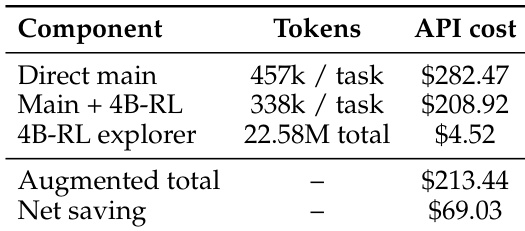
The authors evaluate the standalone exploration quality of FastContext by measuring how accurately it recovers code locations implicated by reference patches. Results show that trained FastContext variants achieve the highest performance across file and module granularities compared to other localization scaffolds. Furthermore, applying supervised fine-tuning and reinforcement learning consistently improves the compact explorer, with reinforcement learning primarily boosting recall. Trained FastContext models outperform other non-frontier localization scaffolds at file and module levels. The compact 4B explorer with reinforcement learning achieves performance competitive with larger untrained models. Reinforcement learning improves the compact explorer mainly by increasing recall while maintaining precision.
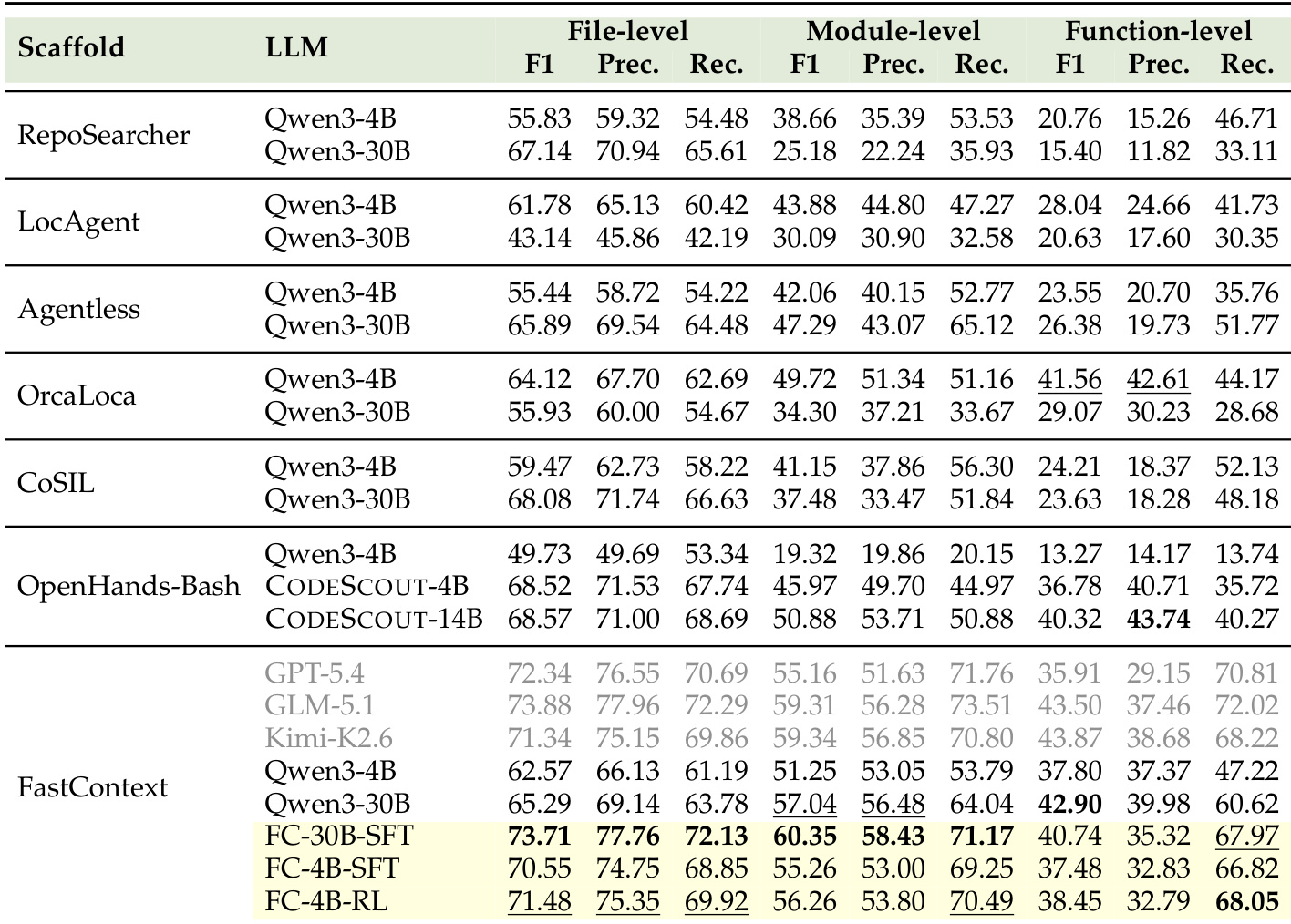
The authors evaluate FastContext as an exploration subagent integrated with various main coding agents across multiple benchmarks. Results demonstrate that incorporating trained FastContext explorers consistently improves task resolution accuracy while substantially reducing the main agent's token consumption and interaction turns compared to direct solving. The compact reinforcement learning variant often matches or exceeds the performance of larger models and same-model exploration, proving that task-grounded optimization enables efficient repository search. Trained FastContext explorers consistently improve end-to-end accuracy and significantly reduce main-agent token usage across all tested main models and benchmarks. The compact reinforcement learning explorer frequently outperforms same-model exploration and larger supervised fine-tuned variants in both success rate and token efficiency. Token savings are most pronounced on complex benchmarks, where the subagent effectively offloads expensive reading and searching operations from the main solver.
The authors evaluate FastContext as an exploration subagent through token-cost audits, standalone localization accuracy tests, and integration with various coding agents across multiple benchmarks. The compact explorer substantially reduces the main agent's token consumption and API costs, yielding net savings even after accounting for its own overhead. Trained with reinforcement learning, it achieves high file- and module-level localization recall while preserving precision, and consistently improves end-to-end task resolution across all tested models. The compact RL variant often matches or exceeds larger models and same-model exploration, with the most pronounced token savings on complex tasks where it offloads expensive search and reading operations.