Command Palette
Search for a command to run...
إجبار الوسائط لتوليد مكاني قابل للتوسع
إجبار الوسائط لتوليد مكاني قابل للتوسع
Bardienus Pieter Duisterhof Deva Ramanan Jeffrey Ichnowski Justin Johnson Keunhong Park
الملخص
تحتوي نماذج توليد الصور من النص (T2I) على معرفة مسبقة غنية بالمساحة (spatial priors). ويصعب تركيب مشاهد واقعية مليئة بالتفاصيل المعقدة دون فهم الهندسة ثلاثية الأبعاد، بما في ذلك المنظور (perspective) والنسب المئوية النسبية للأحجام. وقد استخدمت الأعمال السابقة نماذج T2I لاستغلال هذه المعرفة المسبقة في التنبؤ بالعمق، لكنها كانت تتطلب بيانات عمق كثيفة، وتنطوي على خطوات تدريبية معقدة.نقدم في هذا البحث منهجية "فرض النمط" (Modality Forcing)، وهي وصفة تدريبية بسيطة وقابلة للتوسع، تُطبَّق ما بعد التدريب، بهدف توليد الصور والعمق معاً باستخدام نموذج DiT واحد، يتم تدريبه على بيانات عمق متفرقة. وتتيح منهجية "فرض النمط" التوليد الشرطي والمشترك للصورة والعمق بأي ترتيب، من خلال تخصيص مستويات ضوضاء منفصلة لكل نمط من الأنماط. وتمكّننا المفككات الخاصة بكل نمط (per-modality decoders) من التدريب على بيانات عمق واقعية ومتفرقة، مما يؤدي إلى تحقيق دقة عالية في التنبؤ بالعمق وقابلية قوية للتعميم.نوضح أيضاً أن منهجية "فرض النمط" ترث قابلية توسع تدريب التهيئة المسبقة لنماذج T2I: فمن خلال تدريب مجموعة من نماذج T2I من الصفر (بأحجام تتراوح بين 370 مليون و3.3 مليار معلمة)، نجد أن النماذج الأكبر حجماً المدربة على بيانات صور أكثر تنتج تنبؤات أكثر دقة للعمق. ونموذجنا الأقوى يُظهر نتائج تنافسية مع أحدث مُقدِّرات العمق أحادية الكاميرا، ويقلل نسبة الخطأ المطلق النسبي (AbsRel) بنسبة 57% مقارنة بنماذج التوليد المشتركة الحالية للصور والعمق.وتوفر هذه النتائج دليلاً قوياً على أن مهمة توليد الصور يمكن أن تكون هدفاً قابلاً للتوسع في التدريب المسبق لتحسين الإدراك المكاني (spatial perception).
One-sentence Summary
The authors propose Modality Forcing, a scalable post-training recipe for conditional and joint image-depth generation using a single DiT trained on sparse depth data that assigns separate noise levels per modality, demonstrating through training T2I models from scratch across 370M to 3.3B parameters that larger models produce more accurate depth and the strongest model reduces AbsRel by 57% relative to existing joint image-depth generative models, providing strong evidence that image generation is a scalable pre-training objective for spatial perception.
Key Contributions
- This work introduces Modality Forcing, a post-training recipe that unifies monocular depth estimation, depth-to-image, and joint image-depth generation within a single DiT model. The method enables conditional and joint generation in any permutation by assigning separate noise levels per modality and utilizing per-modality decoders trained on sparse depth data.
- A controlled scaling study reveals that depth prediction accuracy increases as T2I model parameters grow from 370M to 3.3B and training data expands to 1.92B images. These findings provide evidence that image generation serves as a scalable pre-training objective for spatial perception.
- The strongest model competes with state-of-the-art monocular depth estimators and reduces AbsRel error by 57% relative to existing joint image-depth generative models. Performance benchmarks on FLUX.2-klein-9B demonstrate significant improvements over prior baselines without requiring dense supervision.
Introduction
Text-to-image models hold rich spatial priors for synthesizing photorealistic scenes, but adapting them for geometry tasks remains difficult. Prior approaches often rely on complex adapters or dense synthetic depth data, limiting scalability and excluding sparse real-world annotations. The authors introduce Modality Forcing, a streamlined post-training recipe that unifies image and depth generation within a single Diffusion Transformer. By assigning separate noise levels to each modality, the method enables flexible conditional and joint generation using sparse data. Their controlled scaling study further reveals that depth prediction accuracy improves with larger T2I models, confirming image generation as a scalable objective for spatial perception.
Method
The authors introduce Modality Forcing, a framework designed to unify joint RGB and depth generation, image-to-depth, and depth-to-image tasks within a single model. The core methodology involves post-training a pretrained text-to-image Diffusion Transformer (DiT) to model the joint distribution pθ(x,d∣c). This approach assigns independent noise levels to each modality, allowing the model to support various generation permutations by fixing specific noise levels during inference.
Refer to the framework diagram for a visual overview of the training and inference pipeline:
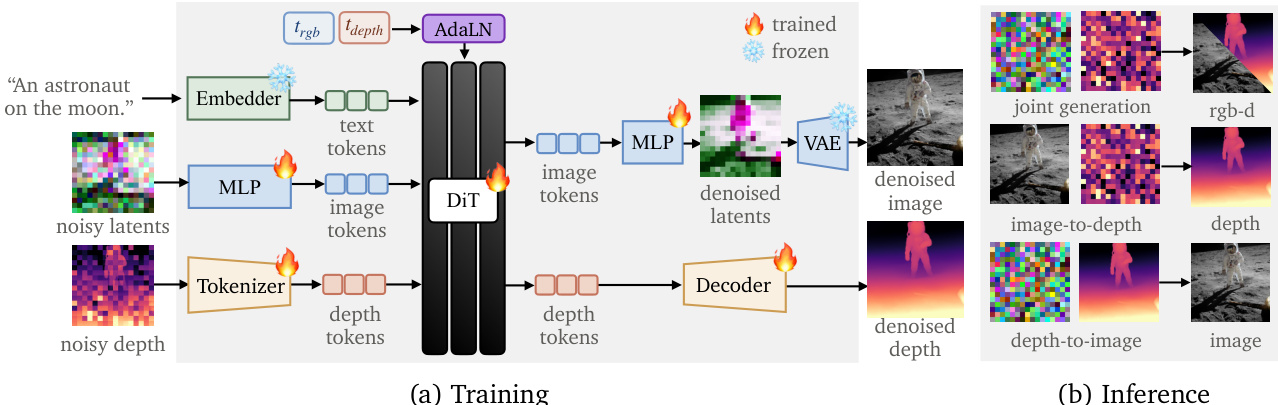
The architecture processes three distinct input streams. Text prompts are encoded into text tokens via a frozen text embedder. For the visual modalities, the model accepts noisy latents for the RGB stream and noisy depth maps for the depth stream. A key design choice is the tokenization strategy. The RGB stream utilizes a pretrained VAE latent space, where noisy latents are projected into image tokens via an MLP. In contrast, the depth stream operates directly in pixel space to accommodate sparse real-world annotations. Noisy depth maps are tokenized by a dedicated depth tokenizer, and missing pixels are filled with isotropic Gaussian noise to signal unavailability.
These token streams are concatenated and fed into the DiT backbone. To handle the independent noise levels, the model employs Adaptive Layer Normalization (AdaLN) with per-modality timestep conditioning. Separate timestep embedders are used for the RGB and depth streams. The RGB stream reuses the pretrained timestep embedder, while the depth stream uses a freshly initialized one. Furthermore, a lightweight cross-stream mixing module allows each stream to observe the other modality's timestep, enabling the model to learn the coupling between RGB and depth noise schedules.
The output heads are also modality-specific. The RGB branch uses an MLP to predict denoised latents, which are then decoded into the final image by the frozen VAE decoder. The depth branch utilizes a depth detokenizer consisting of self-attention layers and a final linear projection to map depth tokens back to pixel space.
Training is conducted by sampling per-modality noise levels trgb and tdepth from [0,1]. For joint generation, both are sampled freely. For image-to-depth, trgb is fixed at 0 while tdepth is sampled. Conversely, for depth-to-image, tdepth is fixed at 0. To prevent catastrophic forgetting of the rich priors learned during the initial text-to-image pretraining, the authors employ a self-distillation loss. This loss penalizes the student model for drifting from the original frozen T2I model's predicted velocity, with the penalty strength weighted based on the depth noise level to account for the informational value of the depth condition.
Experiment
This work evaluates Modality Forcing by training T2I models from scratch and applying the technique to FLUX.2-klein-9B to benchmark performance against specialist depth models. Controlled scaling experiments validate that depth generation quality improves reliably with increased T2I model capacity and pre-training data, highlighting the transfer of spatial priors from image generation. Qualitative comparisons demonstrate that the method produces robust depth maps and consistent point clouds that outperform existing joint generators while remaining competitive with top-tier depth estimation models.
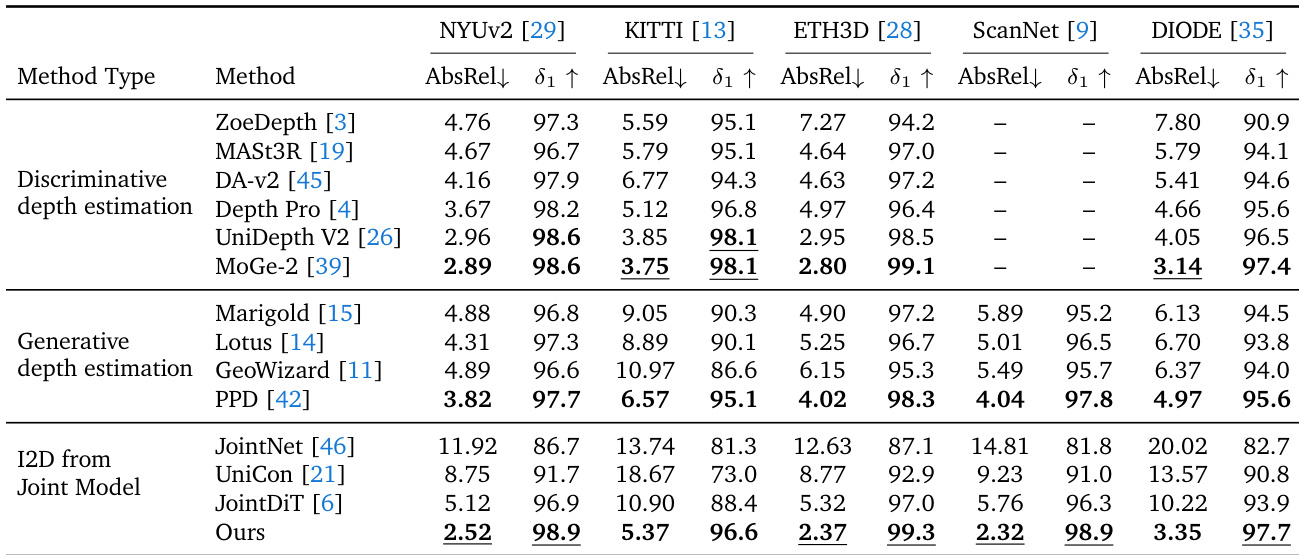
The authors evaluate their Modality Forcing method against discriminative, generative, and joint depth estimation models across five benchmarks. The results demonstrate that their approach achieves state-of-the-art performance on multiple datasets, outperforming existing joint and generative baselines while remaining competitive with specialized discriminative models. The proposed method achieves the best results on NYUv2, ETH3D, and ScanNet benchmarks. It significantly outperforms other joint image-depth generation models and generative depth estimators. Performance is competitive with top discriminative models like MoGe-2, though slightly lower on KITTI and DIODE.
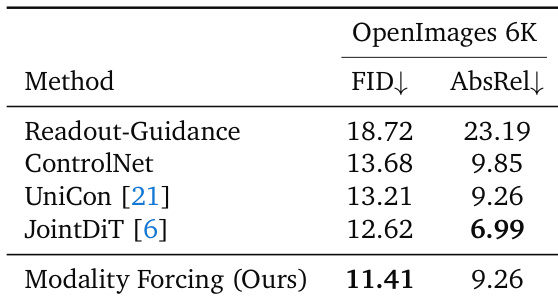
The the the table evaluates depth-to-image generation capabilities on the OpenImages 6K dataset, comparing the proposed method against existing baselines. The results indicate that the proposed approach achieves the highest image quality with the lowest FID score among all methods. While it outperforms others in image fidelity, it shows slightly lower depth consistency compared to the strongest baseline, JointDiT. The proposed method achieves the best image quality scores, outperforming all baselines in FID. JointDiT demonstrates superior depth consistency, achieving the lowest error rate in absolute relative depth estimation. The proposed method matches the depth accuracy of UniCon while providing significantly better image generation quality.
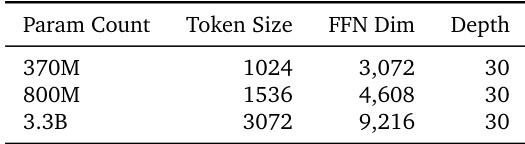
The authors perform a scaling experiment using a suite of T2I models to investigate whether depth generation quality improves with model size. The the the table shows that network depth is kept constant while token sizes and feed-forward dimensions increase alongside the parameter count. Results demonstrate that depth performance scales reliably with these increases in model capability and training data. The study compares models across a range of parameter counts to analyze scaling trends. Architectural depth remains fixed while internal dimensions like token size and FFN dimensions expand. Larger models in the suite correspond to increased token sizes and feed-forward dimensions.
The authors evaluate their Modality Forcing method across five benchmarks, demonstrating state-of-the-art depth estimation performance that outperforms joint and generative baselines while remaining competitive with specialized discriminative models. Additional experiments on depth-to-image generation on the OpenImages dataset reveal superior image fidelity, and scaling studies confirm that depth generation quality reliably improves with increased model parameters and training data. Although depth consistency is slightly lower than the strongest baseline, the method effectively balances high-quality image synthesis with accurate depth estimation.