Command Palette
Search for a command to run...
التتبع العالمي: هندسة مُولَّدة مُطابقة للبكسل تتجاوز المرئي
التتبع العالمي: هندسة مُولَّدة مُطابقة للبكسل تتجاوز المرئي
Hao Zhang Mohamed El Banani Jen-Hao Cheng Paul Zhang Yi Hua Ben Mildenhall Christoph Lassner Narendra Ahuja Gengshan Yang
الملخص
تتبادل طرق تحويل الصور إلى مجسمات ثلاثية الأبعاد (Image-to-3D) عادةً بين الدقة والاكتمال: حيث ترتبط مُقدِّرات العمق (depth estimators) ببيكسلات الإدخال، لكنها تتوقف عند السطح المرئي فقط، بينما تُنشئ نماذج تحويل الصور إلى 3D أشكالاً مكتملة غالباً ما تكون غير محاذاة مع مدخلات الصورة. نطرح هنا «العالم التتبُّعي» (World Tracing)، وهو تمثيل هندسي مولَّد ومتوافق مع البيكسلات، يتنبأ بنقاط ثلاثية الأبعاد محاذية للبيكسلات الملاحظة، مع إكمال الهندسة بما وراء السطح المرئي. بالنسبة لكل بيكسل إدخال، يتنبأ World Tracing بمكدس مرتب من النقاط الثلاثية الأبعاد في فضاء الكاميرا، حيث تمثل الطبقة الأولى من المكدس السطح المرئي، بينما تمثل الطبقات اللاحقة تقاطعات من الأمام إلى الخلف مع الأسطح المُحجَبة. نُجسِّد هذا التمثيل باستخدام محوِّل انتشار يتبع مسار العالم (World-Tracing Diffusion Transformer)، المرمز له بـ (WT-DiT)، والذي يعامل طبقات الهندسة المتعددة كرموز تنقيص ضجيج (denoising tokens) منفصلة، مقترنة عبر آليات انتباه مُفكَّكة وعالمية. تم تدريب WT-DiT باستخدام مطابقة التدفق في فضاء البيكسل (pixel-space flow matching) وجدول ضجيج مختلط يوازن بين إعادة بناء السطح المرئي وتوليد الهندسة المُحجَبة. يحقق World Tracing أداءً قوياً في إعادة بناء الأسطح المرئية وتوليد الهندسة المكتملة عبر معايير تتعلق بالكائنات، والمشهد، والديناميكية، متفوقاً بذلك على كل من مُتوقِّعي العمق ومُولِّدي الصور إلى 3D. كما يحافظ على التطابق ثنائي الأبعاد إلى ثلاثي الأبعاد، مما يتيح تعديل مشاهد ثلاثية الأبعاد بقيادة النص، وتوليد فيديو بمنظور جديد مشروط بالهندسة، ودمجاً خالياً من التدريب مع مُولِّدي الشبكات الملمَّسة (textured-mesh generators).
One-sentence Summary
World Tracing, a generative pixel-aligned geometry representation instantiated with a world-tracing diffusion transformer (WT-DiT) trained with pixel-space flow matching and a mixed noise schedule, predicts ordered stacks of camera-space 3D points per input pixel representing visible and occluded surfaces, outperforming depth predictors and image-to-3D generators on object, scene, and dynamic benchmarks while enabling text-driven 3D scene editing, geometry-conditioned novel-view video synthesis, and training-free integration with textured-mesh generators.
Key Contributions
- This work introduces World Tracing, a generative pixel-aligned geometry representation designed to resolve the trade-off between faithfulness and completeness by predicting ordered stacks of camera-space 3D points. The method instantiates this representation with a diffusion transformer that couples multiple geometry layers through factorized and global attention and trains using pixel-space flow matching.
- Comprehensive evaluations across objects, scenes, and videos demonstrate that multilayer generation improves complete geometry while maintaining visible-surface accuracy. The approach outperforms both depth predictors and image-to-3D generators on these benchmarks.
- The system preserves 2D-to-3D correspondence to enable downstream tasks like text-driven 3D scene editing and geometry-conditioned novel-view video synthesis. Additional demonstrations show training-free integration with textured-mesh generators, validating the model's utility as a geometry prior.
Introduction
Single-image 3D estimation typically forces a choice between faithful visible surface reconstruction and complete geometry generation. Existing depth estimators align with input pixels but fail to model occluded surfaces, whereas image-to-3D models generate full shapes at the cost of pixel alignment. This limitation hinders downstream applications like 3D editing and novel-view synthesis that require consistent camera-space geometry. To address this, the authors introduce World Tracing, a generative pixel-aligned geometry representation predicting an ordered stack of 3D points per input pixel to capture both visible and hidden surfaces. They instantiate this with a diffusion transformer trained via flow matching to unify high-fidelity surface estimation with plausible occluded geometry completion.
Dataset
Dataset Composition and Sources
- The authors build three corpora for multilayer 3D-asset training containing approximately 300K objects, scene frames, and 16.8K dynamic clips.
- Object data sources include Objaverse-XL, Objaverse, 3D-FUTURE, Toys4k, GSO, and TrueBones, resulting in roughly 17M rendered views.
- Scene data combines the public 3D-FRONT corpus with a held-out internal scene set used as a generalization probe.
- Dynamic assets consist of Objaverse-XL animated subsets and rigged characters from TrueBones sampled as short clips.
- A supplementary 12-dataset RGBD-style corpus supports mix-training with real photographs from ScanNet v2, MegaDepth, and Waymo Open alongside synthetic sets like Hypersim and Taskonomy.
Key Details for Each Subset
- Renderings utilize randomized lighting, viewpoints, and intrinsics to ensure diversity.
- Ground-truth layers derive from depth peeling to record ordered front-to-back surface intersections.
- Forward-filling rules populate rays with fewer than L intersections to create dense L-layer XYZ targets.
- The RGBD-style corpus provides supervision for the visible surface layer L0 only, whereas the multilayer corpus shapes layers L1 through L5.
Model Usage and Training Mixture
- Mini-batches sample from the 3D-asset corpus with 60% probability and the RGBD-style corpus with 40% probability.
- RGBD datasets are weighted by the square root of row counts with a 1.5x boost for real-photograph sets.
- Training occurs at 504x504 resolution with a global batch size of 512 optimized via AdamW.
- Evaluation relies on held-out public benchmarks including 100 unique objects, the 3D-FRONT split, and dynamic benchmarks like Obj-Val and Truebone.
Processing and Augmentation Strategies
- Online augmentations apply random crops, flips, and affine perturbations to images and camera-space targets simultaneously.
- Photometric jitter adjusts brightness, contrast, and saturation while alpha masks undergo random dilation or erosion.
- Dynamic clips maintain geometric and mask-space augmentation consistency across frames to preserve temporal integrity.
- Depth values convert to camera-space XYZ using original intrinsics and normalize via a per-sample log-median map.
Method
The authors present an image-to-3D pipeline designed to produce L layer pointmaps from a single input image. The core of this approach is a pixel-aligned representation where geometry is expressed as a tensor X∈RL×H×W×3, with each layer corresponding to a front-to-back intersection along a pixel ray. To facilitate training, the authors employ a dense supervision strategy where empty intersections in deeper layers are filled from the nearest valid earlier layer, ensuring every valid input ray supervises all layers.
The overall framework is illustrated in the provided diagram. The process begins with two inputs: an RGBA image (H,W,4) and a noisy multilayer XYZ stack (L,H,W,5). The visual information is processed by a frozen MoGe ViT-L encoder, which generates pixel-aligned image tokens. Simultaneously, the noisy geometry is patchified into geometry tokens. These two streams of tokens are then fused together.
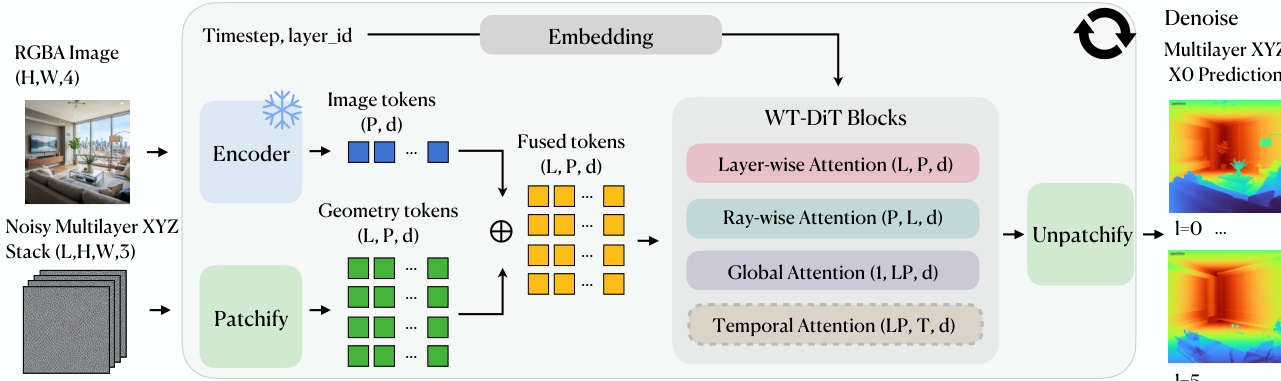
The fused tokens are fed into a stack of WT-DiT blocks, which serve as the core diffusion transformer. This module incorporates a specialized three-way attention factorization to handle the multilayer structure efficiently. First, layer-wise attention allows each layer to attend to itself as a 2D image. Second, ray-wise attention enables tokens at the same pixel to attend along the front-to-back layer axis, enforcing depth ordering and coherence. Third, global attention recovers object or scene-level context. For dynamic clips, a temporal attention block is also inserted to handle time-axis dependencies.
Conditioning is applied through embeddings for the timestep and layer identifier. These embeddings are modulated into the network via FiLM layers, which break the layer permutation symmetry without requiring learnable additive position tokens. The network is trained using a flow-matching objective directly on the normalized coordinate signal, predicting the clean endpoint x^0. Finally, the output tokens are unpatchified to produce the final denoised multilayer XYZ prediction, preserving the camera-space coordinates and pixel-to-3D correspondences.
Experiment
The experiments verify that a pixel-aligned multilayer paradigm yields more faithful 3D geometry across objects, scenes, and dynamic clips while benefiting downstream pipelines dependent on pose or disoccluded structure. Qualitative comparisons indicate the model generates complete geometry without sacrificing visible-surface accuracy, outperforming regression-based and canonical-frame baselines by better modeling occluded surfaces and preserving planar structures on out-of-distribution inputs. Downstream demonstrations confirm that this camera-space representation enables robust object insertion, textured mesh generation, and view synthesis, establishing the multilayer approach as a superior prior for real-world geometric tasks.
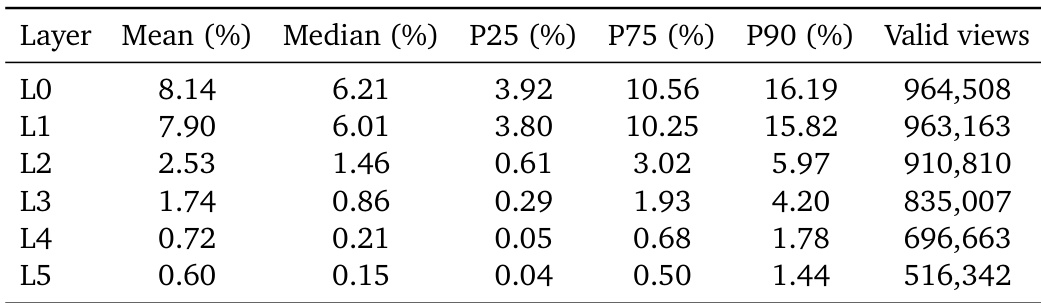
The the the table displays per-layer statistics regarding valid pixel coverage and view counts for a multilayer geometry model. Results indicate a consistent downward trend in both mean coverage and valid views as the layer depth increases from the surface to deeper occluded regions. Mean valid coverage is highest for the initial layer and diminishes substantially in subsequent layers. The number of valid views decreases steadily as the layer index moves from top to bottom. There is a marked disparity in data density between the visible surface layers and the deeper geometric layers.
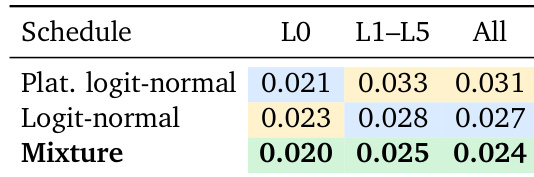
The authors evaluate different diffusion timestep schedules to determine their impact on multilayer geometry generation quality. While specific schedules favor either the visible surface or deeper occluded layers, combining them into a mixture yields the most consistent results across the entire geometry stack. The plateaued logit-normal schedule outperforms the standard schedule on the visible Layer 0. The standard logit-normal schedule is more effective for deeper layers compared to the plateaued variant. A mixture of both distributions achieves the best overall performance across all layers.
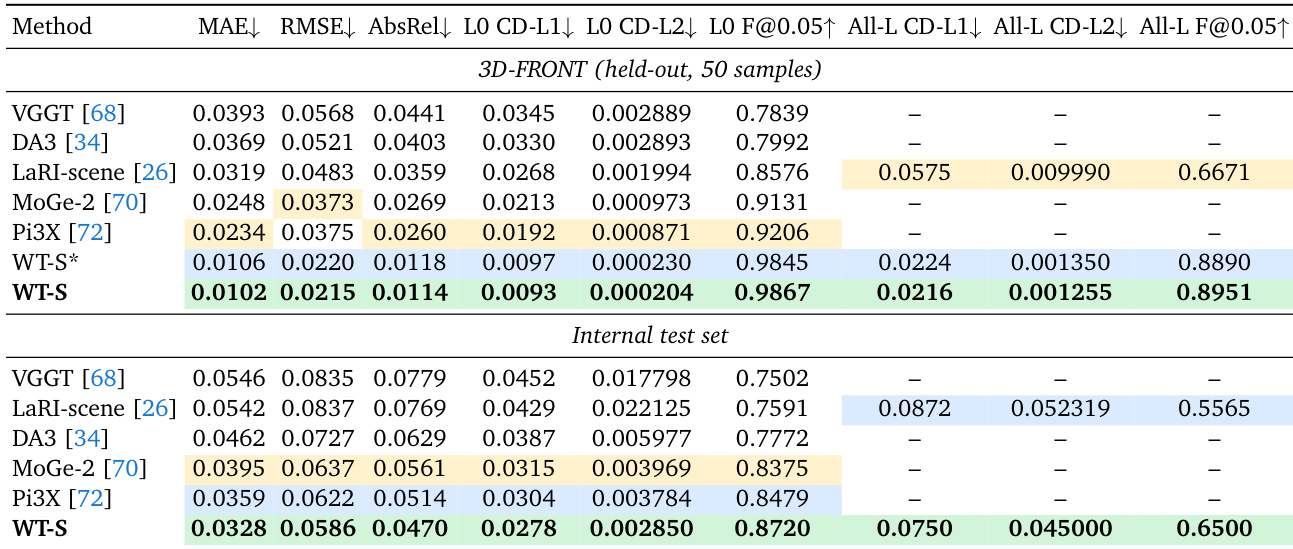
The authors evaluate scene geometry generation on the 3D-FRONT benchmark and an internal test set. The proposed WT-S method achieves superior performance in both visible-surface depth accuracy and complete multilayer geometry reconstruction compared to existing baselines like LaRI-scene and MoGe-2. WT-S achieves the best visible-surface depth and L0 point-cloud geometry among all compared methods. The method substantially improves all-layer geometry metrics over single-layer baselines that do not produce occluded layers. The full model trained on a broader corpus outperforms the version trained solely on 3D-FRONT on the held-out benchmark.
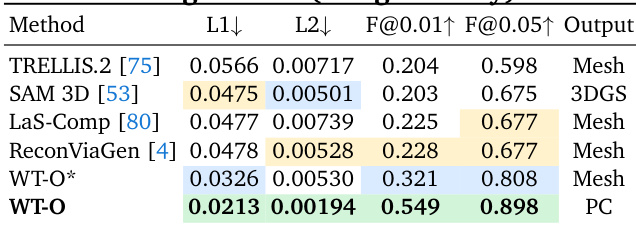
The the the table compares the proposed WT-O method against several baselines for object geometry generation. Results indicate that WT-O achieves the highest accuracy and completeness, outperforming methods that generate meshes or 3D Gaussians. The data supports the claim that the pixel-aligned multilayer paradigm yields more faithful 3D geometry across objects. WT-O achieves the best performance metrics across all measured categories compared to other methods. The proposed approach generates a point cloud output that surpasses mesh-based and 3D Gaussian baselines in geometry faithfulness. Baselines such as TRELLIS.2 and ReconViaGen show higher error rates and lower fidelity scores in this evaluation.
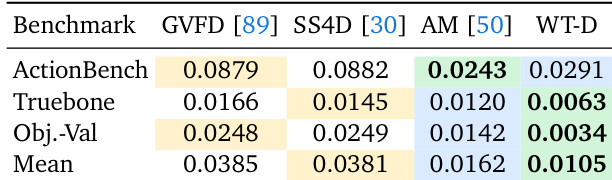
The authors evaluate dynamic geometry generation using a proposed model against several baselines across object, rigged, and action-driven splits. The proposed method achieves the best overall mean performance and leads on object validation and rigged asset benchmarks. ActionMesh demonstrates superior performance specifically on the action-driven benchmark where ground truth matches its native output format. The proposed model achieves the best mean performance across all dynamic geometry benchmarks. Results show superior accuracy on object validation and rigged asset evaluations compared to diffusion and regression baselines. ActionMesh remains the top performer on action-driven motion tasks due to native format alignment with ground truth.
Experiments evaluate a multilayer geometry model across scene, object, and dynamic generation tasks, revealing significant data density disparities between visible surfaces and deeper occluded regions. Evaluation of diffusion schedules shows that combining distributions yields consistent results across layers, while the proposed methods outperform existing baselines in reconstruction accuracy and completeness. The results validate that the pixel-aligned multilayer paradigm yields more faithful 3D geometry than traditional mesh or Gaussian approaches across the evaluated scenarios.