Command Palette
Search for a command to run...
تقرير تقني حول dots.tts
تقرير تقني حول dots.tts
الملخص
نقدّم نموذج dots.tts، وهو نموذج أساسي (Foundation Model) للنص إلى الكلام (TTS) ذاتي الارتباط المستمر، يحتوي على 2 مليار معلمة، ويعالج الكلام في فضاء ز latent مستمر. وتقًاً للنماذج الذاتية الارتباط المستمر الحالية، تتلخص ابتكاراتنا الرئيسية في ثلاثة محاور. أولاً، ندرّب نموذج Audio-VAE باستخدام أهداف متعددة لبناء فضاء كلامي مستمر هيكلياً من الناحية الدلالية وملائماً للتنبؤ. ثانياً، نستخدم تهيئة تعتمد على كل التاريخ (full-history conditioning) في رأس مطابقة التدفق (flow-matching head) للحفاظ على الاتساق بعيد المدى وتقليل الانحراف أثناء التوليد. ثالثاً، نطبق تدريباً لاحقاً ذاتياً تصحيحياً خالياً من المكافآت (reward-free self-corrective post-training) لرأس مطابقة التدفق لتحسين المتانة وجودة الصوت بشكل إضافي.وبعد التدريب على مجموعة بيانات ضخمة متعددة اللغات، يحقق dots.tts أفضل أداء متوسط في تقييم Seed-TTS-Eval، حيث سجّل نسب أخطاء كلمات (WERs) بلغت 0.94% / 1.30% / 6.60%، ودرجات تشابه (SIM) بلغت 81.0 / 77.1 / 79.5، على مجموعات الاختبار الصينية (zh) والإنجليزية (zh-hard) والصينية المعقدة (en) على التوالي. وفي معايير التقييم الأخرى، يظل dots.tts يعرض باستمرار أداءً رائداً ضمن المصادر المفتوحة، مظهراً استقراراً قوياً في التوليد، وقدرة على تقليد الأصوات، وتعابير عاطفية غنية.وللاستنتاج الفعال (Inference)، نطبق أيضاً ضغطاً (Distillation) مبنياً على MeanFlow واعياً للإرشاد التوجيهي المشروط (CFG-aware)، مما يمكّن من توليد كلام بزمن استجابة منخفض، مع زمن وصول الحزمة الأولى (first-packet latency) يبلغ 85 مللي ثانية و54 مللي ثانية في وضعي الإخراج البثّي المزدوج والبثّي المتدفق، على التوالي. ولتسهيل البحث القابل لإعادة التنفيذ والنشر العملي، ننشر كود التدريب والاستنتاج، مع الكويكبات المحفوظة مسبقاً (Pretrained checkpoints)، والكويكبات بعد التدريب اللاحق، والكويكبات بعد ضغط MeanFlow، بموجب رخصة Apache 2.0.
One-sentence Summary
dots.tts, a 2B-parameter continuous autoregressive text-to-speech foundation model, employs a multi-objective Audio-VAE for a semantically structured latent space, full-history flow-matching conditioning, and reward-free self-corrective post-training to achieve open-source state-of-the-art performance on Seed-TTS-Eval (WERs 0.94%/1.30%/6.60% and SIM 81.0/77.1/79.5 on zh/en/zh-hard) with strong voice cloning and emotional expressiveness, while CFG-aware MeanFlow distillation enables low-latency streaming with first-packet latencies of 85 ms and 54 ms in output streaming and dual-streaming modes, respectively.
Key Contributions
- An Audio-VAE trained with multiple objectives constructs a semantically structured, prediction-friendly continuous latent space for dots.tts.
- A flow-matching head conditioned on the full autoregressive history reduces generation drift and preserves long-range temporal consistency.
- Reward-free self-corrective post-training applied to the flow-matching head boosts robustness and acoustic quality, and dots.tts achieves state-of-the-art performance on Seed-TTS-Eval with WERs of 0.94%/1.30%/6.60% and SIM scores of 81.0/77.1/79.5 on the zh/en/zh-hard test sets.
Introduction
The authors address continuous autoregressive text-to-speech, where modeling speech in a latent space offers flexibility but prior approaches suffer from poorly structured latent representations, generation drift over long sequences, and limited acoustic robustness. They introduce dots.tts, a 2B-parameter multilingual model with three innovations: a multi-objective Audio-VAE that yields a semantically organized, prediction-friendly continuous space; full-history conditioning in the flow-matching head to maintain long-range consistency; and reward-free self-corrective post-training that refines quality without external feedback. Combined with efficient CFG-aware MeanFlow distillation, these improvements achieve state-of-the-art open-source performance in stability, voice cloning, and expressiveness.
Dataset
-
Dataset composition and sources
The authors train the backbone on 1.5 million hours of audio drawn from three pools: an in‑house Chinese/English speech corpus, a curated collection of open‑source TTS and ASR datasets, and a small caption‑paired set that bootstraps style control and general‑audio generation. -
In‑house data (~1.2M hours)
- Bulk of the training audio, sourced from an internal Mandarin Chinese and English speech corpus.
- Unified preprocessing applies vocal enhancement, source separation, speaker‑aware diarization, and language‑routed ASR (Whisper‑Large‑v3 for English and most languages, Paraformer for Mandarin).
- Clips are filtered using cross‑ASR consistency, effective‑bandwidth estimation, UTMOS, and intra‑clip x‑vector variance.
- After filtering, the set consists of cleaned, transcribed, speaker‑organized speech used directly for backbone training.
-
Open‑source corpora (~300K hours)
- A curated mixture of TTS and ASR datasets: Emilia, LibriTTS‑R, HiFi‑TTS, HiFi‑TTS‑2, WenetSpeech4TTS, AISHELL‑3, Magicdata, MLS, MSR‑86K, IndicVoices‑R, EuroSpeech, WaxalNLP‑TTS, and FLEURS.
- Each corpus is re‑scored with the same processing and filtering pipeline applied to the in‑house data.
- Provides the bulk of non‑CJK language coverage.
-
Caption‑paired set (~7K hours)
- A small subset designed to inject natural‑language style control and general‑audio generation.
- Combines a sample of AutoACD paired with natural‑language captions and an in‑house selection of open‑source recordings augmented with Gemini‑generated descriptions of speaker traits, emotion, delivery, and acoustic environment.
-
How the data is used
- All three subsets are pooled for backbone training, with an approximate mixture ratio of 1.2M (in‑house) : 300K (open‑source) : 7K (caption‑paired) hours.
- The caption‑paired portion provides the small fraction of general audio mentioned by the authors and introduces caption‑conditioned style control.
-
Processing and metadata details
- The preprocessing stack produces speaker‑organized audio clips with ASR transcriptions.
- For the caption‑paired set, metadata is enriched with synthetic Gemini descriptions; no additional cropping beyond the diarization and scoring steps is described.
Method
The authors leverage a fully continuous, end-to-end autoregressive TTS system built from two decoupled networks: an audio variational autoencoder (AudioVAE) that defines the continuous representation, and an autoregressive backbone that predicts that representation one patch at a time. The AudioVAE encodes 48 kHz mono speech into a 128-dimensional latent stream at 25 Hz and decodes it back via a BigVGAN-style decoder. Once trained, it is frozen and serves as both the generation target and the input representation for the backbone.
The backbone comprises three main components: a semantic encoder, a large language model (LLM), and an autoregressive flow-matching head. The LLM handles the semantic side of generation while the flow-matching head handles the acoustic side.
Refer to the framework diagram:
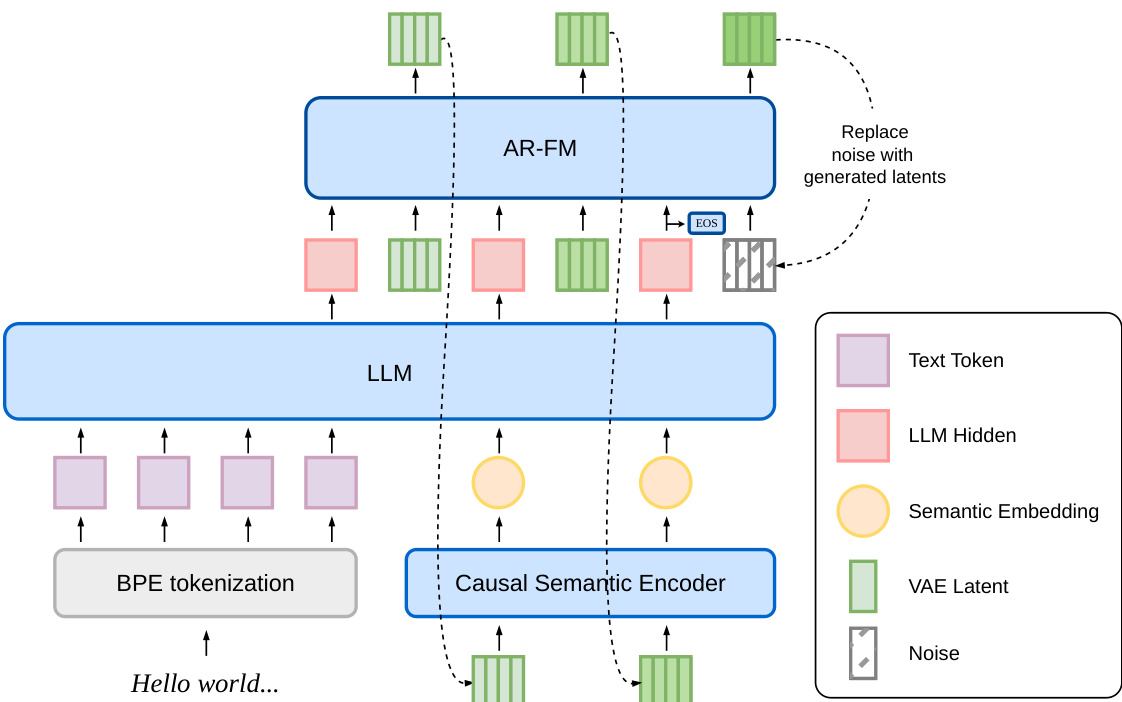
The LLM, initialized from a pretrained text LLM, consumes BPE text tokens together with a 6.25 Hz audio-semantic embedding stream and emits one hidden state per audio step. The text is placed as a prefix in plain TTS mode, or interleaved with audio in a 1T1A layout for low-latency streaming. The autoregressive flow-matching head (AR-FM) conditions on that hidden state and generates the next four-frame patch of the 25 Hz VAE latent. The semantic encoder projects each newly generated patch back into a single 6.25 Hz embedding that feeds the LLM at the next step. The LLM sees only this semantic summary, not the raw VAE latent, which is necessary to keep continuous autoregressive rollouts stable.
The AR-FM head uses a Diffusion Transformer (DiT) as the velocity-field predictor. Each per-step VAE patch is a block of 4 latent frames at 25 Hz. At every audio position, the head consumes a flow-matching context assembled from three streams projected into a common hidden space: the LLM hidden state at that position, the clean patches of all earlier audio positions, and the noisy patch under generation. A speaker x-vector is added as a global condition, and classifier-free guidance is enabled by dropping the LLM hidden stream and speaker stream independently during training.
To train the AR-FM head efficiently, the authors employ a block-causal attention mask over a concatenated cause and generation sequence.
As shown in the figure below:
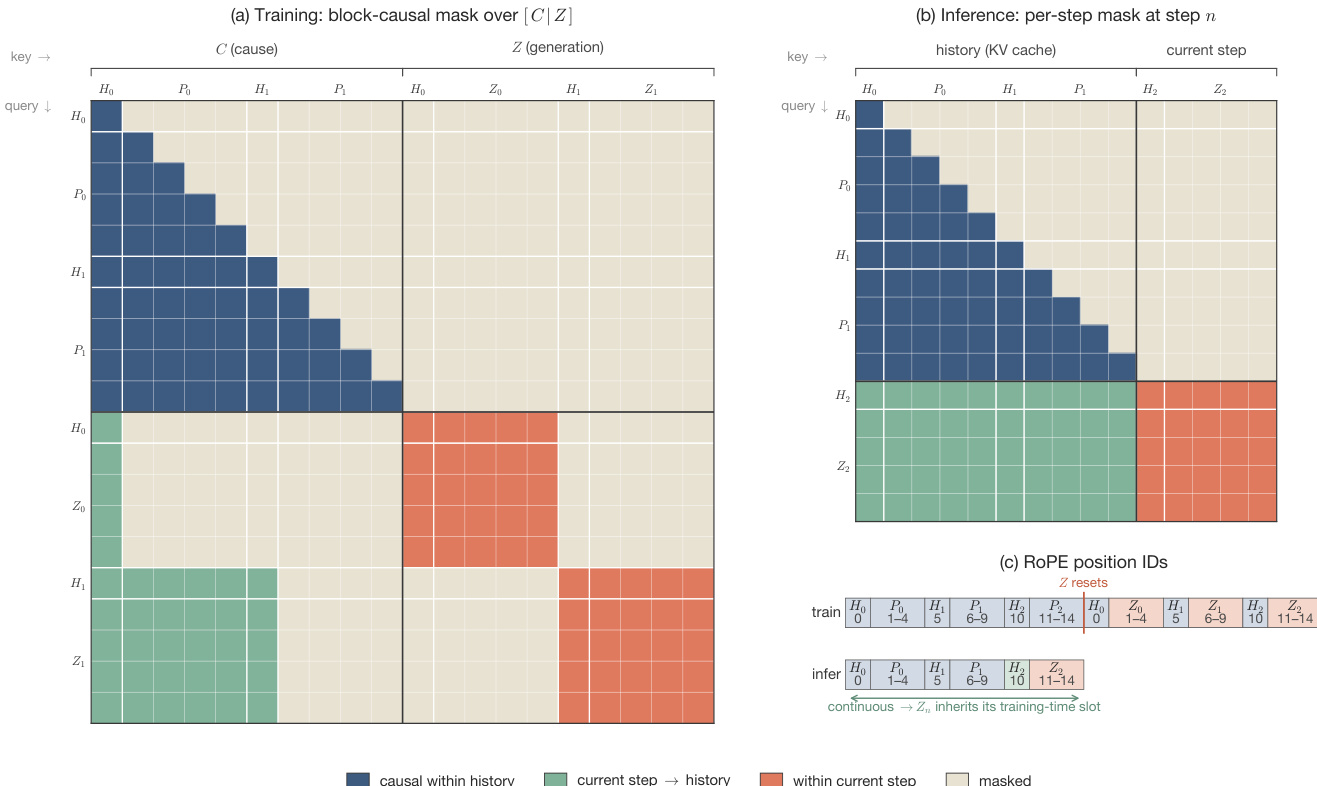
The training sequence is built from two halves of equal length. The cause part holds the clean LLM-conditioned history, and the generation part holds the noisy patches under denoising. Position indices are reset between the two halves so that the RoPE phases match those of a per-step inference forward. The block-causal mask partitions the attention matrix into four sub-blocks. The cause-to-cause block is standard causal. The cause-to-generation block is fully masked so the cause stream hidden states are independent of the noisy targets. The generation-to-cause block is prefix-causal, letting each generation block attend to exactly the autoregressive context the patch sees at inference. The generation-to-generation block is block-diagonal so different patches denoise independently. This layout makes the parallel training forward numerically identical to a per-step inference rollout.
The full training pipeline proceeds in three stages: AudioVAE training, backbone pretraining, and post-training.
The AudioVAE is trained in two stages. The first stage targets reconstruction quality using a combination of multi-period plus multi-scale sub-band CQT adversarial loss, multi-scale mel-spectral reconstruction loss, and feature-matching loss, together with KL and flow regularization. The second stage targets learnability by adding a frame-level alignment loss against a frozen WavLM teacher and a multitask downstream block trained on ASR, emotion, and speaker classification objectives. The downstream encoder is retained as the semantic frontend.
Backbone pretraining proceeds in three sub-stages: modality alignment, general training, and annealing. During pretraining, the model is optimized using a flow-matching loss and a stop loss. The flow-matching loss is a per-patch mean-squared error between the predicted velocity and the analytic conditional vector field on the VAE latent:
Lfm=En,t∼U(0,1),ϵ∼N(0,I),Pnvθ(Znt,t,H≤n,P<n,s)−(Pn−ϵ)2The stop loss uses a dedicated EOS prediction head trained with balanced binary cross-entropy:
Leos=−21logpN−1−2(N−1)1n=0∑N−2log(1−pn)After pretraining, the authors apply post-training to the DiT acoustic generator inside the AR-FM head. The first post-training stage uses a reward-free self-correction objective. It exposes the model to its own inference-time errors by performing a detached Euler rollout and re-noising the off-trajectory state to teach the model to steer those states back toward the clean latent endpoint. The second stage is CFG-aware MeanFlow distillation. The self-corrected DiT is frozen as a teacher, and a student DiT is trained to predict the mean velocity over a time interval. Because classifier-free guidance is fused into the teacher target, the student directly matches the teacher guided mean-velocity prediction with a single conditional forward pass at inference.
Experiment
The evaluation spans foundational zero-shot quality on Seed-TTS-Eval, multilingual coverage on the 24-language MiniMax-Speech set, cross-lingual voice cloning on CV3-Eval, and expressiveness on EmergentTTS-Eval, all using a short unseen reference prompt. dots.tts attains leading speaker similarity across all benchmarks and top or competitive word error rates, with particularly large gains in cross-lingual timbre preservation and syntactic complexity, while the self-corrective alignment and MeanFlow distillation stages correct multi-step inference drift and enable efficient few-step generation at a negligible similarity cost. The continuous AudioVAE introduces almost no reconstruction overhead, and the overall system demonstrates real-time streaming viability, though low-resource language word error rates and expressiveness-consistency trade-offs remain open challenges.
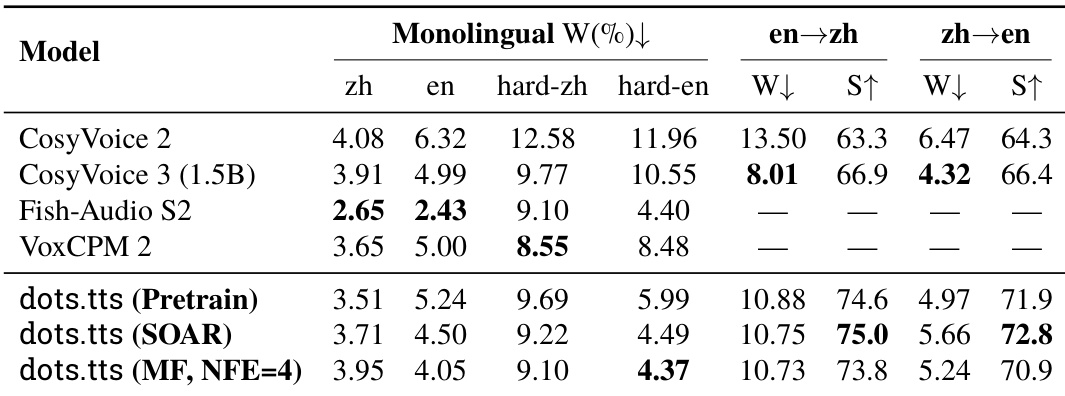
The authors evaluate the proposed model on a benchmark assessing monolingual word error rates and cross-lingual voice cloning performance. Results indicate that the distilled version achieves the lowest error rate on the hard English monolingual subset, while the self-corrective aligned version leads in speaker similarity for cross-lingual tasks. However, cross-lingual word error rates remain higher than some baselines despite the strong similarity scores. The distilled model variant achieves the best word error rate on the hard English monolingual subset. The self-corrective aligned model leads speaker similarity in both cross-lingual directions, outperforming other baselines. Cross-lingual word error rates for the proposed model trail behind the leading baseline despite strong speaker similarity.
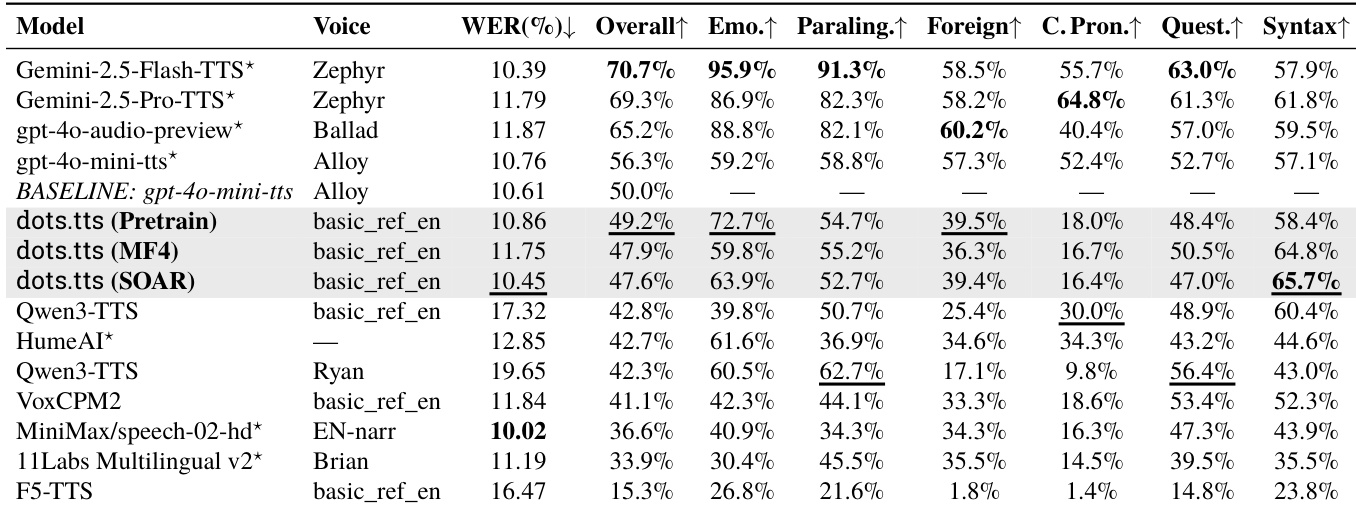
The authors evaluate expressiveness-oriented scenarios using a head-to-head audio judge against a reference system. The proposed model variants achieve the highest overall win-rate among open-source systems, with the self-corrective aligned version demonstrating the lowest word error rate. While the model excels in syntactic complexity and emotional expression compared to other open-source baselines, it struggles with complex pronunciation and foreign words due to lexical coverage limits. The self-corrective aligned variant achieves the top syntactic complexity score across all evaluated systems, surpassing both open and closed-source baselines. The pretrained variant leads the open-source field in emotional expression, though closed-source systems using carefully tuned voices score higher. Performance drops on complex pronunciation and foreign words, indicating challenges with rare or out-of-distribution lexical items.
The authors evaluate multilingual zero-shot text-to-speech performance across 24 languages using the MiniMax-Speech test set. Results indicate that the proposed model achieves the highest average speaker similarity, leading on the vast majority of individual languages compared to baselines. While content fidelity remains competitive across most languages, word error rates are elevated for a few low-resource languages due to insufficient token coverage. The proposed model leads the average speaker similarity metric and achieves the top score on most individual languages. The MeanFlow distilled variant matches the performance of the self-corrective aligned version at the average level with only a minor trade-off in similarity. Content fidelity is strong for well-represented languages but degrades on low-resource outliers where the model struggles with token coverage.
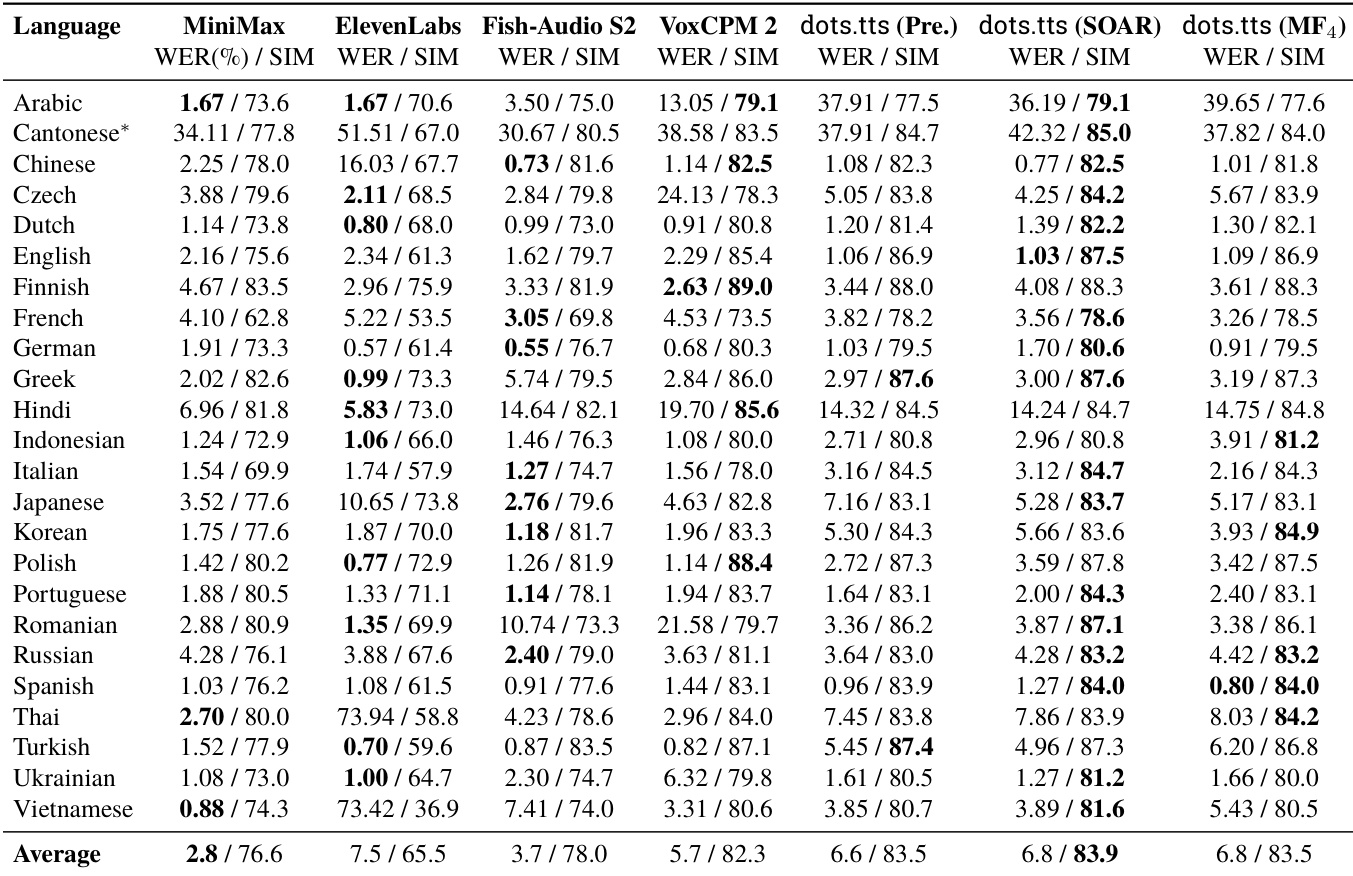
The authors evaluate the reconstruction performance of their AudioVAE on a standard speech dataset, comparing it against discrete neural codecs and continuous representations. The proposed model operates at a high sample rate with a low frame rate, achieving top-tier performance across most quality and similarity metrics. This high fidelity ensures that the latent representation adds minimal error to the end-to-end pipeline, preventing reconstruction from becoming a downstream bottleneck. Discrete tokenizers consistently underperform compared to continuous representations across perceptual quality and speaker similarity metrics. The proposed VAE achieves the highest speaker similarity and lowest word error rate among all evaluated models, closely approaching ground truth levels. Despite utilizing a low frame rate, the model maintains top-band performance in intelligibility and perceptual metrics compared to other continuous representations.
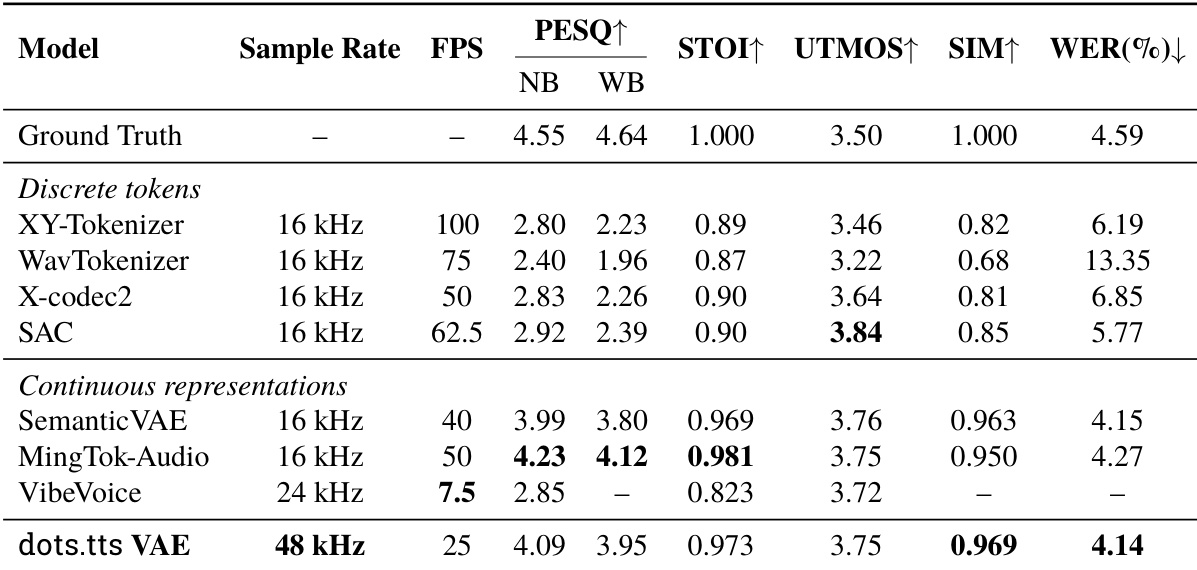
The authors evaluate dots.tts on a zero-shot voice cloning benchmark, comparing it against various open-source and commercial systems. The proposed model variants achieve the best average performance across both content fidelity and speaker similarity metrics, outperforming all reported baselines. The post-training stage improves speaker similarity, while the distillation method maintains low error rates with fewer inference steps. The dots.tts variants secure the top average scores for both word error rate and speaker similarity across all evaluated baselines. The post-training stage achieves the highest speaker similarity, outperforming the closest competing models. MeanFlow distillation maintains word error rates comparable to the full model while requiring significantly fewer inference steps.
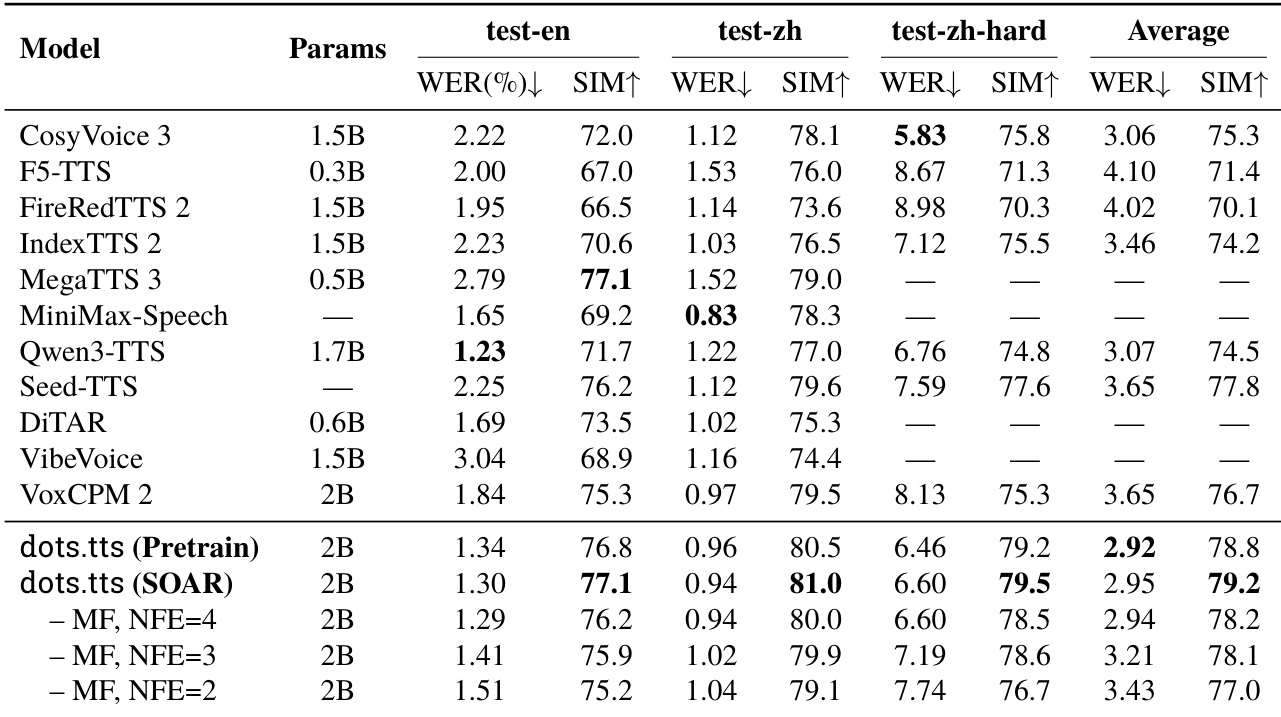
The evaluation covers monolingual word error, cross-lingual voice cloning, expressiveness, multilingual zero-shot TTS, audio latent reconstruction quality, and zero-shot voice cloning benchmarks. The distilled model variant delivers the lowest word error rate on hard English data, while the self-corrective aligned version achieves the best cross-lingual speaker similarity and top syntactic complexity scores, though cross-lingual word accuracy and handling of rare or out-of-distribution lexical items remain challenging. In the 24-language zero-shot setting, the model leads average speaker similarity and remains competitive on content fidelity, but elevated word error rates appear for low-resource languages due to limited token coverage. The AudioVAE provides high-fidelity continuous representations that closely approach ground-truth intelligibility and similarity, and the final dots.tts system attains the best average content fidelity and speaker similarity across baselines, with post-training boosting similarity and MeanFlow distillation maintaining low error rates with fewer inference steps.