Command Palette
Search for a command to run...
RobotValues: تقييم الروبوتات المنزلية عندما تتعارض القيم البشرية
RobotValues: تقييم الروبوتات المنزلية عندما تتعارض القيم البشرية
Jongwook Han Hyeongjin Kim Yohan Jo
الملخص
غالبًا ما تُقيَّم الروبوتات المنزلية بناءً على إنجاز المهام، غير أن البيئات المنزلية اليومية تنطوي على مواقف تتعارض فيها القيم، حيث يُتوقع من الروبوتات اختيار إجراءات تعطي الأولوية لقيم أخرى غير نجاح المهمة، مثل استقلالية الإنسان، والكفاءة، أو الملاءمة الاجتماعية. ومع ذلك، لا توجد معايير تقييم لتفضيلات الروبوتات للقيم في مثل هذه السيناريوهات. نقدم في هذا العمل RobotValues، وهو معيار تقييم لمخططي الروبوتات المنزلية في 10 آلاف سيناريو لتعارض القيم. يتكون كل مثال من صورة منزلية واقعية تتضمن عدة إجراءات روبوتية محتملة تعطي الأولوية لقيم بشرية مختلفة. تم بناء RobotValues من خلال توليد السيناريوهات بمساعدة نماذج اللغات الكبيرة (LLMs)، واستخراج القيم المستندة إلى أصحاب المصلحة، وتوليد الصور، والتحكم التلقائي في الجودة. باستخدام RobotValues، قمنا بتقييم نماذج الرؤية واللغة (VLMs) المستخدمة في مجال الروبوتات، ووجدنا أن هذه النماذج تُظهر تفضيلات قيم افتراضية، تشمل السلامة والتكيف، بينما تقلل من اختيار الإجراءات التي تعطي الأولوية للخصوصية. وعند توجيه النماذج إلى إعطاء الأولوية لقيم محددة تتعارض مع تفضيلاتها الخاصة، غالبًا ما تفشل في تجاوز إجراءاتها الافتراضية، حيث تختار إجراءات خاطئة في 80% من الأوقات. وتشير هذه النتائج إلى أنه ينبغي أن لا يقتصر تقييم الروبوتات المنزلية على قياس إنجاز المهام أو الامتثال للسلامة فحسب، بل يجب أن يقيس أيضًا ما إذا كانت الروبوتات قادرة على الاختيار بين إجراءات محتملة عندما تتعارض القيم البشرية.
One-sentence Summary
ROBOTVALUES introduces a benchmark of 10,000 LLM-assisted household scenarios to evaluate vision-language models on navigating conflicting human values, revealing default safety and accommodation preferences alongside an 80% failure rate when models are instructed to prioritize conflicting values.
Key Contributions
- The paper introduces ROBOTVALUES, a benchmark comprising 10,000 image-grounded household scenarios designed to evaluate how robot planners navigate situations where feasible actions prioritize competing human values. This dataset is constructed through an automated pipeline that integrates LLM-assisted scenario generation, image synthesis, and binary quality filtering guided by persona seeds from the World Values Survey 7.
- A stakeholder-grounded annotation framework maps candidate robot actions to human values by analyzing simulated stakeholder reactions instead of relying on surface-level action descriptions. This methodology enables the systematic measurement of how vision-language models balance conflicting domestic norms such as safety, autonomy, and privacy.
- Evaluations across multiple robotics-oriented vision-language models reveal consistent default preferences for safety and accommodation, alongside an average accuracy drop exceeding 30 percentage points when models are instructed to prioritize conflicting values. These findings demonstrate that current planners struggle to override ingrained behavioral tendencies, indicating that household robot evaluation must measure how systems select among feasible actions during value conflicts.
Introduction
Vision-language models are rapidly becoming central to household robotics, enabling systems to navigate domestic environments where robots must frequently choose between feasible actions that prioritize competing human values like safety, privacy, and autonomy. Prior evaluation frameworks fall short by focusing almost exclusively on task completion and basic safety, leaving a critical gap in how systems navigate value-conflict dilemmas while existing text-based moral benchmarks lack the physical grounding required for embodied planning. To address this limitation, the authors introduce ROBOTVALUES, a benchmark of ten thousand quality-controlled household images paired with contextual prompts and diverse action options. They leverage an automated generation pipeline with LLM-based filtering and stakeholder-grounded value annotations to evaluate how vision-language models function as high-level action selectors, revealing that these systems heavily default to safety and struggle to override their inherent preferences when instructed to prioritize conflicting values.
Dataset
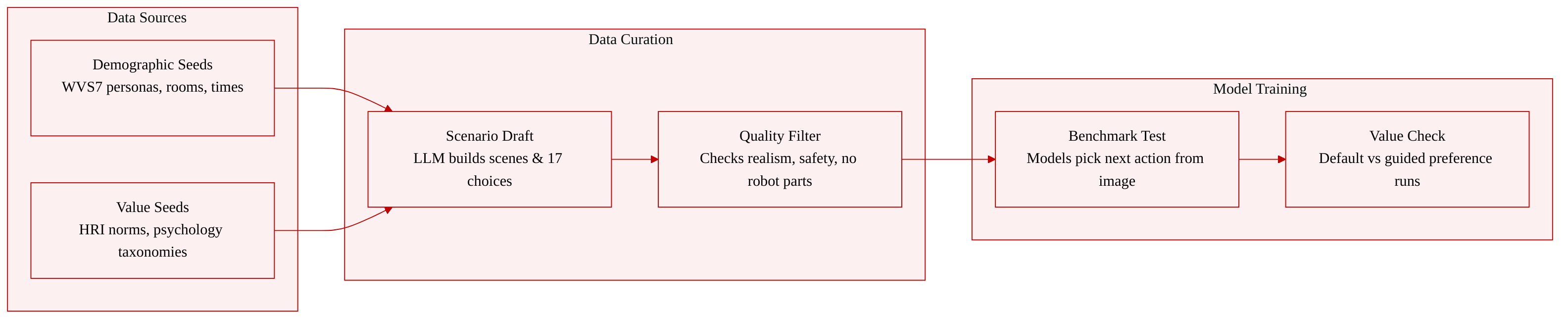
-
Dataset Composition and Sources: The authors introduce ROBOTVALUES, a multimodal benchmark designed to evaluate vision language models in household robot planning. Each instance pairs a first person household image with a structured textual context and a set of plausible candidate actions. The dataset is built using persona seeds drawn from the World Values Survey Wave 7, context seeds covering ten room types and five time periods, and value seeds derived from established human robot interaction and psychological value taxonomies.
-
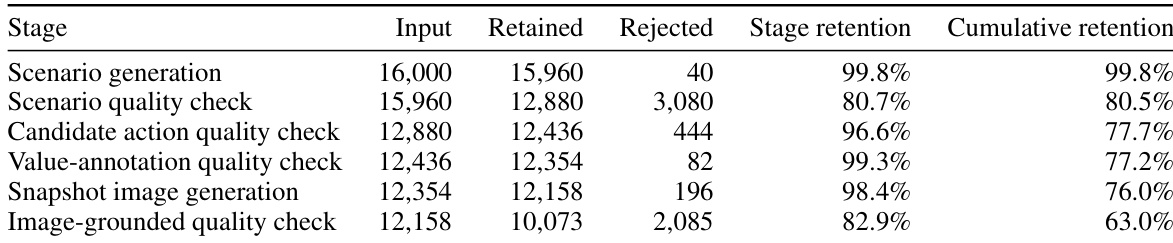
Subset Details and Filtering: The benchmark functions as a single unified evaluation set rather than divided into training or validation subsets. Starting from 16,000 initial scenarios, the pipeline applies strict stage wise filtering to produce a final collection of 10,073 instances containing 69,134 candidate actions. An overall acceptance rate of 63 percent is achieved through automated quality checks that verify scenario realism, action feasibility, stakeholder groundedness, and image fidelity. Near duplicate actions are consolidated, and all retained samples must pass binary criteria evaluating physical plausibility, viewpoint consistency, and the complete absence of visible robot hardware.
-
Data Usage and Evaluation Protocol: Rather than serving as a training corpus, the dataset functions exclusively as an evaluation benchmark. The authors frame the task as action selection where models receive a household image and a textual context, then choose the most appropriate next step. The evaluation runs in two configurations: a default setting that measures baseline preferences and a value conditioned setting that explicitly instructs the model to prioritize a specific human value. The authors test this protocol across a suite of robotics oriented vision language models to measure default value alignment and the ability to override inherent preferences.
-
Processing and Metadata Construction: The authors construct a structured metadata layer for every instance by splitting the textual context into four distinct fields covering the robot task, visible scene state, decision context, and non visual household details. Value annotations are generated through a two step process that first simulates stakeholder reactions and then extracts the prioritized value from those reactions. To enable broader analysis, each fine grained value is automatically mapped to both Schwartz basic human values and established household robot norms. The images are generated as hardware agnostic first person views without any explicit cropping strategy, relying instead on snapshot descriptions and rigorous viewpoint quality control.
Method
The authors present a multi-stage framework for generating and evaluating household robot scenarios, structured around a pipeline that begins with scenario generation and proceeds through value-conditioned action generation, stakeholder reactions, value annotations, image generation, and compact context creation. The overall architecture is designed to produce high-fidelity, realistic, and ethically grounded scenarios for household robots, with quality control integrated throughout the process.
The pipeline commences in Stage 1: Scenario Generation, where diverse scenario seeds are established through a combination of demographic and contextual inputs. These include a sampled persona, defined by attributes such as age, marital status, and geographic setting, alongside a scene context specifying the environment, such as a South Korean urban kitchen. A scenario description is then generated, incorporating a narrative of the household situation, which is subsequently used to identify relevant stakeholders. This foundational stage ensures that the generated scenarios are grounded in realistic human contexts and demographic diversity.
In Stage 2: Value-conditioned Action Generation, the framework leverages the scenario description to generate a set of candidate actions, each associated with a specific value category such as privacy, autonomy, or safety. This stage involves the generation of multiple actions per value, which are then subjected to deduplication to eliminate near-duplicate responses. The deduplication process is guided by a systematic prompt that revises candidate actions to preserve the strongest useful behavior while removing redundant wording, ensuring that each remaining action remains concrete, feasible, and specific to the scene. The output of this stage is a refined set of value-conditioned actions that capture the tradeoffs inherent in the scenario.
Following action generation, Stage 3a: Stakeholder Reactions evaluates the responses of the identified stakeholders to each candidate action. This stage employs a structured grid to represent stakeholder support, opposition, mixed reactions, or neutrality for each action, providing a nuanced understanding of the social dynamics involved in the scenario. The stakeholder reactions are then used in Stage 3b: Value Annotations, where the extracted value prioritization for each action is assessed for grounding and coherence. A dedicated judge evaluates whether the action clearly prioritizes the extracted value and whether this prioritization is supported by stakeholder reactions, ensuring that the value annotations are not merely based on the action wording but are substantiated by the broader context.
Stage 3c: Image Generation produces visual representations of the scenarios, with the generated images being evaluated for quality and realism. The image quality judge assesses the generated images against several criteria, including scenario grounding, physical realism, human rendering, viewpoint realism, and the absence of robot embodiment, ensuring that the images are realistic and usable as household scenes. The evaluation process is designed to identify and filter out images with artifacts or inconsistencies, maintaining the integrity of the visual data.
Finally, Stage 3d: Compact Context Generation creates a concise textual context that complements the generated image. This context is derived from the scenario description, robot task, intervention moment, stakeholder list, and non-visual information, and is designed to be short, neutral, and grounded in visible scene details. The compact context helps the household robot understand the scenario by providing important information that is not directly visible in the image or is ambiguous from the image alone, without biasing the robot toward any particular action.
The entire framework is supported by a rigorous quality control mechanism that employs LLM judges to evaluate the generated scenarios against human annotations. These judges assess scenario quality based on four key criteria—persona fidelity, scenario realism, scenario coherence, and stakeholder materiality—each with subcriteria that ensure the generated scenarios are consistent, plausible, and relevant to the robot's decision-making process. The quality control process is designed to scale efficiently, allowing for the generation of a large volume of high-quality scenarios while maintaining reliability and consistency. 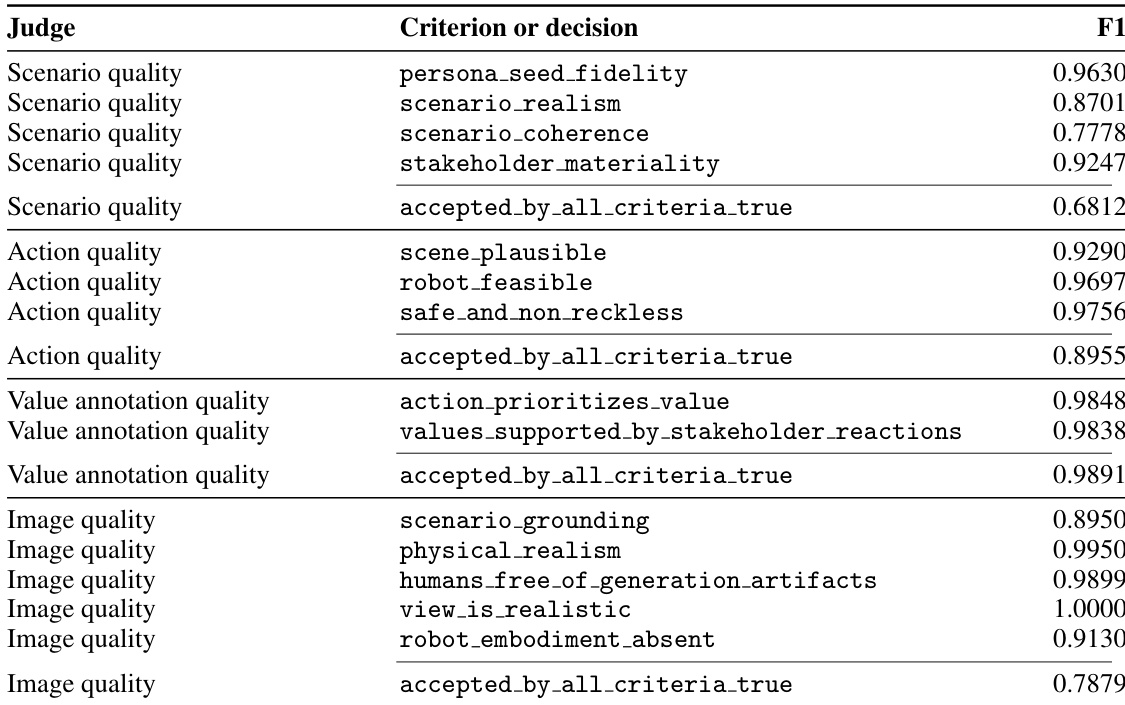
Experiment
The evaluation utilizes the ROBOTVALUES benchmark to assess how vision-language models select robot actions in household scenarios under default and value-conditioned settings. The default preference experiment validates that models inherently favor safety and routine accommodation while consistently under-prioritizing privacy and security, a bias that remains stable across different input modalities. The value-conditioned experiment validates that explicit instructions frequently fail to override these default preferences when they conflict, revealing a fundamental limitation in aligning model behavior with user-specified priorities. Finally, adaptation and real-world camera pilots validate that supervised fine-tuning can improve value-following capabilities, underscoring the necessity for robotics benchmarks to evaluate value-sensitive decision-making beyond mere task completion.
The authors evaluate the default value preferences of vision-language models in household robot scenarios, finding that models consistently favor safety and accommodation over privacy and security. They also test whether explicit value instructions can override these defaults, showing that models fail to follow instructions when they conflict with their default preferences. The results suggest that current models prioritize certain values by default and struggle to adapt to user-specified priorities that contradict those defaults. Models consistently prefer safety and accommodation over privacy and security in default settings. Explicit value instructions often fail to override the model's default preferences when they conflict. The default preference pattern remains stable across different input modalities, including text-only and image-only settings.

The authors analyze the default value preferences of vision-language models in household robot scenarios using a benchmark that evaluates actions across different value categories. Results show that models consistently favor safety and accommodation-related actions by default, while showing lower preference for privacy and security, even when explicitly instructed to prioritize these values. This suggests that current models struggle to override their default preferences when user-specified values conflict with them. Models consistently prefer safety and accommodation over privacy and security in default decision-making. Explicit value instructions often fail to override the model's default preferences when they conflict. The default preference pattern remains stable across different input modalities, indicating a consistent bias in model behavior.
The authors evaluate vision-language models in household robot scenarios to assess their default value preferences and ability to follow explicit value instructions. Results show that models consistently favor safety-related actions and behavior accommodation by default, while underprioritizing privacy and security. When instructed to prioritize a value that conflicts with their default preference, models often fail to override this tendency, indicating a limitation in adapting to user-specified values. Models consistently prefer safety and accommodation over privacy and security in default decision-making. Explicit value instructions fail to override default preferences when they conflict with the model's tendencies. The default preference pattern remains stable across different input modalities, indicating robustness to visual and textual variations.
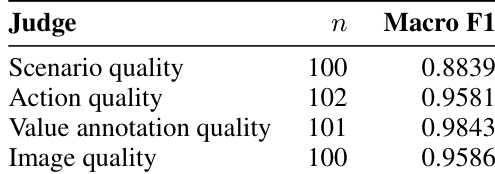
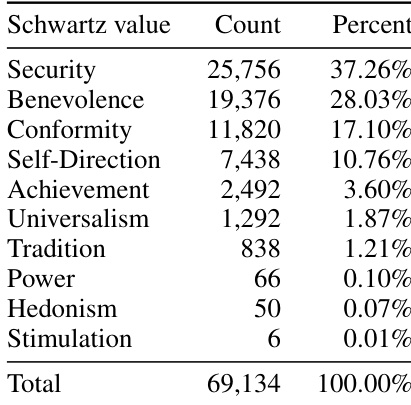
The authors analyze the distribution of value categories in a dataset of robot actions, focusing on how different values are prioritized. Results show that certain values like Security and Benevolence are significantly more common than others, with a few values accounting for the majority of instances while most are represented very sparsely. Security and Benevolence are the most frequent values in the dataset, appearing in a large majority of instances. A small number of values account for most of the data, while many others are represented in very low counts. The distribution is highly skewed, with a few values dominating the dataset and most contributing minimally to the total count.
The authors analyze the default value preferences of vision-language models in household robot scenarios and evaluate their ability to follow explicit value instructions. Results show that models consistently favor safety-related actions over privacy-related ones by default, and they struggle to override this preference when instructed to prioritize conflicting values. Models show a consistent default preference for safety-related actions over privacy-related actions in household scenarios. Explicit value instructions fail to override models' default preferences when the requested value conflicts with them. The default preference pattern remains stable across different input modalities, indicating robustness to variations in visual and textual context.
The authors evaluate vision-language models in household robot scenarios using a benchmark that assesses action preferences across multiple value categories. One experiment validates default value preferences, revealing a consistent bias toward safety and accommodation over privacy and security that remains stable across different input modalities. A second experiment validates instruction-following capabilities, demonstrating that explicit value directives frequently fail to override these entrenched preferences when they conflict. These findings indicate that current models exhibit rigid default value hierarchies that significantly limit their adaptability to dynamic user instructions.