Command Palette
Search for a command to run...
MobileGym: منصة محاكاة قابلة للتحقق وعالية التوازي لأبحاث Agent لواجهة المستخدم الرسومية على الهاتف المحمول
MobileGym: منصة محاكاة قابلة للتحقق وعالية التوازي لأبحاث Agent لواجهة المستخدم الرسومية على الهاتف المحمول
الملخص
نقدم MobileGym، وهي بيئة خفيفة الوزن، مستضافة على المتصفح، وقابلة للتحكم الكامل، للاستخدام اليومي في تطبيقات الهواتف المحمولة، وتستهدف تحقيق دقة عالية في التفاعل دون الحاجة إلى استنساخ البنية الخلفية الخاصة. تتيح هذه البيئة قدرتين كانتا سابقاً خارج متناول التطبيقات اليومية: إشارات النتائج القابلة للتحقق من خلال آلية حكم حتمية تعتمد على الحالة عبر بنية JSON مهيكلة، بالإضافة إلى التعلم المعزز عبر الإنترنت القابل للتوسع من خلال عمليات التنفيذ المتوازية منخفضة التكلفة. يتم التقاط الحالة الكاملة للبيئة، وتكوينها، وتفرعها، ومقارنتها بصيغة JSON مهيكلة، ويمكن لخادم واحد استضافة مئات النسخ المتوازية، مع استهلاك ذاكرة يبلغ حوالي 400 ميجابايت لكل نسخة، ووقت بدء تشغيل بارد يبلغ حوالي 3 ثوانٍ. ويضمن نموذج الحالة متعدد الطبقات وإطار عمل تعريف المهام التصريفي الحفاظ على قابلية برمجة الحالة وإنشاء المهام بشكل عملي على نطاق واسع، بينما توفر آلية حكم برمجية واحدة أحكام تقييم حتمية ومكافآت كثيفة للتعلم المعزز. ويوفر المعيار المرافق MobileGym-Bench 416 قالبًا للمهام معلمة، تشمل 256 قالبًا للاختبار و160 قالبًا للتدريب، عبر 28 تطبيقًا، مع حكام حتميين وبروتوكول AnswerSheet مهيكل يتجنب فشل عمليات المطابقة بالنص الحر. وفي دراسة حالة للانتقال من المحاكاة إلى الواقع، حقق GRPO على Qwen3-VL-4B-Instruct مكسبًا قدره +12.8 نقطة مئوية على مجموعة الاختبار المكونة من 256 مهمة، وعلى مجموعة فرعية مكونة من 59 مهمة تعتمد على إشارات الجهاز الحقيقي، حافظ تنفيذ الجهاز الحقيقي على 95.1% من مكسب التدريب الذي تم تحقيقه في بيئة المحاكاة. صفحة المشروع: https://mobilegym.github.io.
One-sentence Summary
MOBILEGym is a verifiable, browser-hosted simulation platform for mobile GUI agents that operates without proprietary backends through a structured JSON state model and deterministic programmatic judging to enable scalable parallel reinforcement learning, as demonstrated when GRPO training on Qwen3-VL-4B-Instruct yields a +12.8 point gain on the MOBILEGYM-BENCH 256-task test set and retains 95.1% of that performance during real-device execution.
Key Contributions
- MOBILEGYM is a browser-hosted environment that captures full mobile interface states as structured JSON to enable deterministic judging and snapshot-based rollout forking. This architecture supports low-cost parallel execution and a declarative task framework, facilitating scalable reinforcement learning without proprietary backends.
- MOBILEGYM-BENCH provides 416 parameterized task templates across 28 everyday applications, equipped with deterministic judges and an AnswerSheet protocol to prevent free-text matching failures. The benchmark incorporates empirically calibrated difficulty strata and diagnostic metrics to standardize agent evaluation.
- Training Qwen3-VL-4B-Instruct with GRPO yields a 12.8-point gain on the 256-task test set, while a Sim-to-Real study demonstrates that real-device execution retains 95.1% of the simulated training improvement. Evaluations across nine agents and a VLM-judge audit confirm the environment's utility for interactive GUI agent development.
Introduction
Mobile GUI agents are rapidly advancing to handle smartphone tasks from screenshots and natural language, yet scaling their training with online reinforcement learning remains bottlenecked by a lack of reproducible environments. Prior work forces a difficult trade-off between emulator-based platforms, which are repeatable but limited to simple applications and require heavy computational resources, and real-device benchmarks, which cover everyday apps but suffer from uncontrollable state, irreversible actions, and an inability to parallelize rollouts. The authors address these structural limitations by introducing MOBILEGym, a lightweight browser-hosted simulation environment that represents all device and application state as structured JSON. This architecture makes the environment fully readable, writable, and forkable, enabling deterministic outcome verification, safe sandboxed execution, and hundreds of parallel instances on standard hardware. By pairing this programmable infrastructure with a typed AnswerSheet protocol and a comprehensive 416-task benchmark, the authors deliver a scalable foundation that bridges the gap between realistic mobile interaction and reliable online agent training.
Dataset
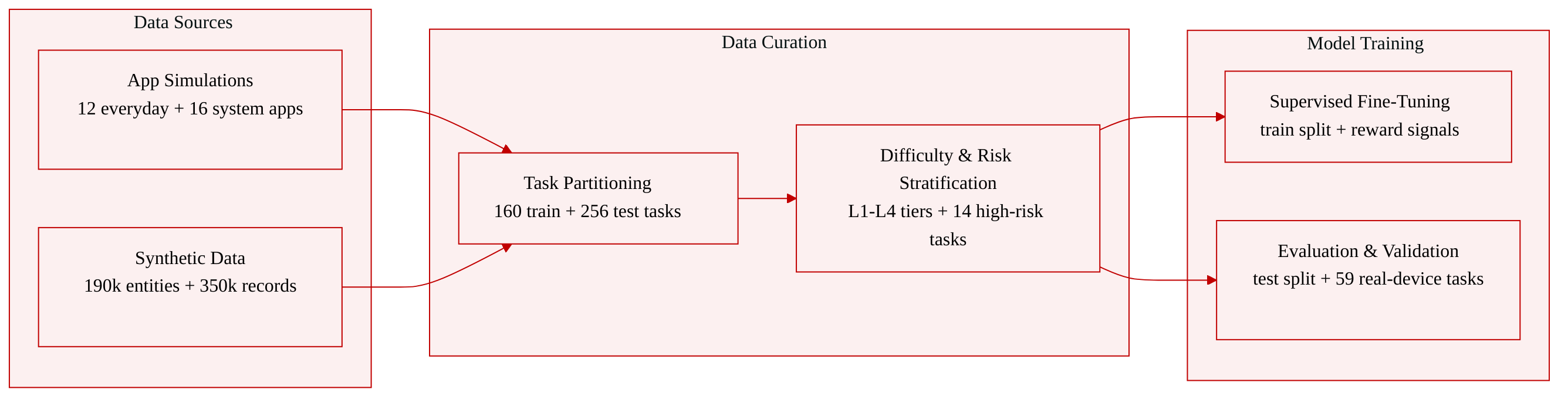
Dataset Composition and Sources
- The authors introduce MOBILEGYM-BENCH, a browser-hosted Android-like simulation environment containing 416 parameterized task templates across 28 reconstructed applications.
- The dataset sources 12 everyday apps and 16 system apps, all built with LLM-assisted implementation and populated with over 190,000 synthetic entities and 350,000 structured records loaded from configurable JSON defaults.
- Task templates are strictly partitioned into a 160-task training set and a 256-task test set, with no overlapping tasks between splits.
Subset Details and Filtering
- The training split focuses on single-app tasks covering core interaction skills, while the test set dedicates 36 percent of its tasks to cross-app workflows to evaluate out-of-distribution generalization.
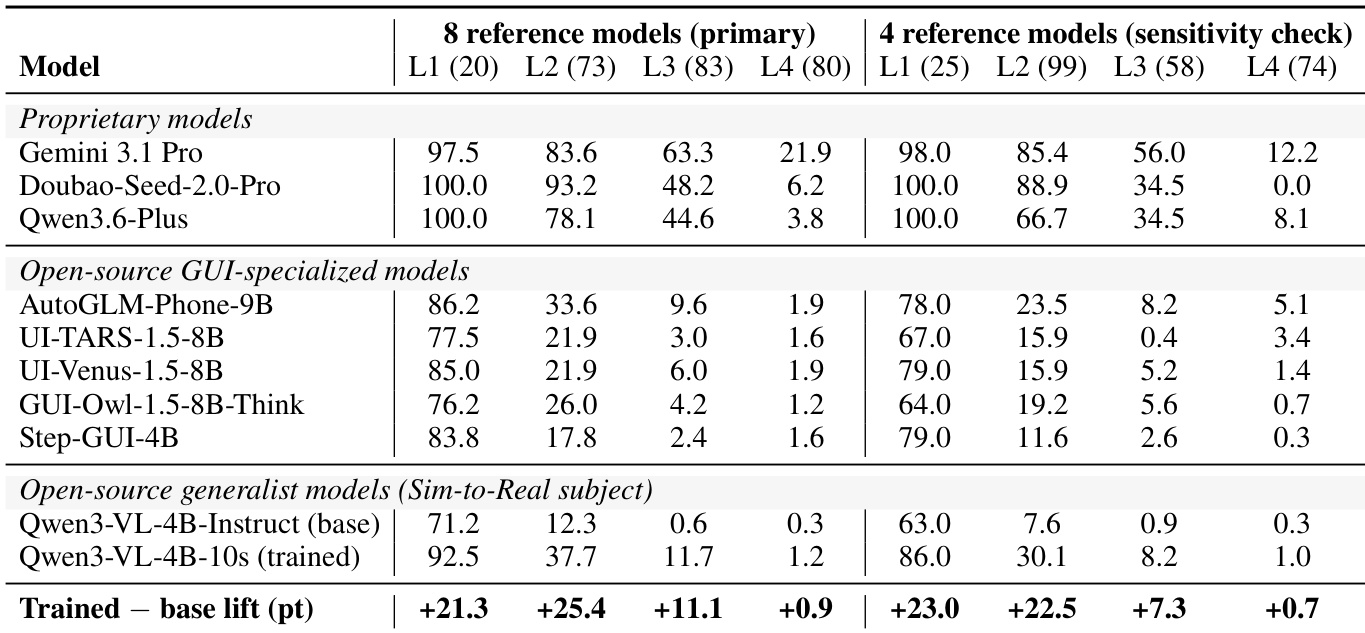
- Difficulty levels are assigned via post-hoc empirical calibration using eight reference models. The test set is stratified into four diagnostic tiers based on success and precision rates: Level 1 contains 20 tasks, Level 2 includes 73, Level 3 covers 83, and Level 4 comprises 80.
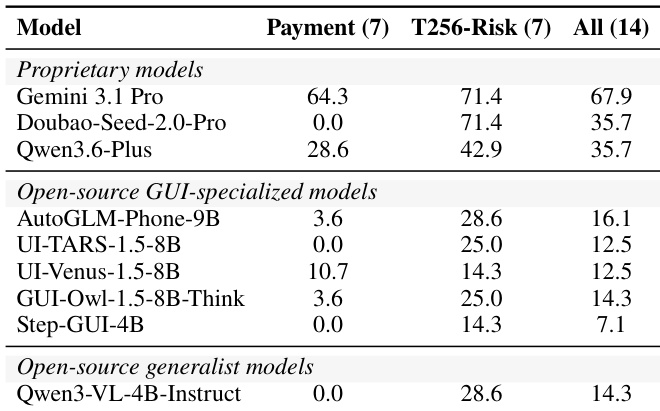
- A specialized high-risk subset of 14 tasks isolates standalone payment operations and irreversible account modifications to measure execution capability in high-consequence scenarios.
- For real-device validation, the authors apply outcome-stratified sampling to select 67 signal tasks, exclude 8 irreproducible cases, and finalize a 59-task validation set supplemented by 15 stable-fail sanity checks.
Data Usage and Processing
- The authors leverage the training split for supervised fine-tuning and reinforcement learning, relying on the environment's deterministic state resets and structured reward signals.
- All tasks support dynamic parameter sampling, and Level 3 and Level 4 tasks further include two to three orthogonal instruction variants to expand diversity without modifying app code.
- The evaluation framework processes interaction trajectories into five-tuples pairing visual frames with JSON state transitions, enabling controllable data synthesis for world models, state predictors, and reward verifiers.
- Task metadata is enriched with capability tags drawn from a 13-tag vocabulary, while the test distribution is explicitly tracked across difficulty, objective type, and composition category.
Metadata Construction and Environment Processing
- The authors normalize all interaction coordinates to a uniform 0 to 1000 grid, allowing native agent action spaces to map cleanly into a standardized 17-action abstraction.
- Each interactive field carries explicit hint strings that define strict input formats, which the automated judge enforces to prevent ambiguity and eliminate false positives from natural language variations.
- Backend services and dynamic content are replaced with controllable JSON state objects, ensuring reproducible evaluation and stable reinforcement learning signals while isolating agent-facing interaction semantics from live server behavior.
- The judging pipeline bypasses fragile string matching by applying floating-point tolerance for numeric entries and directly comparing structured state diffs to verify task completion.
Method
The MOBILEGYM framework is designed as a browser-hosted, lightweight simulation environment that enables high-fidelity interaction with everyday mobile applications while maintaining full control over the environment state. The system targets interaction fidelity—modeling the visible UI surface and behavioral responses to user inputs—without replicating proprietary backend systems or low-level Android internals. This is achieved through a layered state model that separates large, read-only world data (such as public posts, products, or contacts) from a compact, mutable runtime state that captures agent-induced changes. The runtime state, along with the OS runtime (including task stacks, permissions, and system events), forms the structured environment state that is exposed for configuration, reset, and comparison. The final user interface is produced by overlaying the runtime state onto the world data, ensuring that all changes are tracked and programmatically inspectable.
As shown in the figure below, the system architecture is built around a compositional model where the final UI is rendered by combining world data, a runtime overlay, and OS runtime components. The environment state is serialized as structured JSON, enabling deterministic snapshotting, forking, and state restoration. This allows for parallel rollouts and supports scalable online reinforcement learning. The environment state is managed through a unified state store with a non-persistent policy, where a browser refresh is equivalent to a device reboot—resetting the runtime state while preserving user data. This design enables consequence-free execution of high-risk operations such as transfers or deletions, as the simulator can restore the pre-action state after each trajectory.
The system supports a declarative navigation specification for each app, formalized as an extended finite-state machine (EFSM). The EFSM model defines UI states, inputs, transition guards, and update operations, allowing for both runtime navigation and static analysis. The transition function is data-driven, enabling conditional branches based on application state variables and supporting dynamic expansion of the state space. Guards in the EFSM syntax can enforce constraints on route paths, query parameters, or app state values, ensuring correct navigation behavior. This specification is used to drive UI transitions at runtime and to generate candidate task trajectories, supporting automated task creation and consistency checking.
To ensure verifiable outcomes, MOBILEGYM employs a deterministic judging mechanism that inspects the structured environment state to evaluate task success. Each task is associated with a programmatic judge that checks for expected state changes and detects unexpected side effects, such as unintended message sends or data modifications. This approach eliminates reliance on unreliable visual language model judgments and provides fine-grained, reproducible signals. The AnswerSheet protocol further enhances reliability by requiring agents to fill structured forms with typed fields, which are validated using type-specific matchers such as exact text, numeric tolerance, or choice checks. This prevents false positives and negatives that arise from free-text matching heuristics.
The system also supports a standardized app-layer architecture, where each app module follows a consistent structure including a manifest, state store, navigation specification, and default data. This design enables zero-registration auto-discovery and facilitates the integration of new apps and features. Cross-app communication is implemented through an intent system, content providers, and a broadcast bus, replicating Android’s mechanisms for sharing data and events. The back-key dispatch is managed via a priority-chain mechanism, ensuring correct handling of events across different UI components.
In the reinforcement learning pipeline, the environment supports parallel rollouts by forking the initial state into multiple instances, each executing a trajectory independently. The structured state enables efficient state comparison and differential analysis, producing signals such as success, progress, side effects, and overuse. These signals are used to compute dense RL rewards and benchmark metrics, enabling scalable training and evaluation. The framework's design allows for high-throughput simulation, with a single server hosting hundreds of parallel instances, each requiring approximately 400 MB of memory and a 3-second cold start. This infrastructure supports large-scale training and real-world transfer studies, as demonstrated by the Sim-to-Real case study showing high gain retention on real-device execution.
Experiment
The evaluation framework tests vision-language agents on a browser-based mobile benchmark using fixed step budgets and programmatic state verification to measure success, progress, and unintended side effects across calibrated difficulty levels. Benchmark results demonstrate that agent performance scales consistently with task complexity, effectively distinguishing model capabilities while revealing that unexpected environment modifications are not strictly correlated with overall success rates. Sim-to-real transfer experiments confirm that reinforcement learning fine-tuned in simulation yields highly transferable policies that maintain performance gains on physical devices, successfully adapting to real-world UI variations. Finally, efficiency analyses establish that this lightweight simulator significantly reduces hardware and API costs compared to traditional emulator setups, enabling scalable agent training without dedicated cluster infrastructure.
The authors present a comparison of model performance across different categories, highlighting that proprietary models achieve higher success rates than open-source GUI-specialized and generalist models. The results show a clear performance gap between proprietary and open-source models, with proprietary models demonstrating significantly better outcomes across all evaluation metrics. Performance varies within categories, with some open-source models showing competitive results in specific conditions. Proprietary models outperform open-source models across all evaluation metrics. Open-source GUI-specialized models show better performance than open-source generalist models. Performance varies within model categories, with some open-source models achieving competitive results in specific conditions.
The the the table compares the API costs of using VLM judges for evaluating mobile tasks, showing that Qwen3.6-Plus is significantly cheaper than GPT-5.4 across different scenarios. The authors highlight that their approach uses code-level judging, which incurs no cost, making it more scalable than VLM-based evaluation. Results show that VLM-based evaluation is substantially more expensive, especially at scale, due to high input and output token costs. Qwen3.6-Plus is much cheaper than GPT-5.4 for VLM-based evaluation Code-level judging incurs no cost, enabling scalable evaluation VLM-based evaluation is significantly more expensive, especially at large scale

The authors evaluate multiple models on the MOBILEGYM-BENCH benchmark, showing that success rate decreases with task difficulty across all models. Proprietary models outperform open-source models, with Gemini 3.1 Pro showing the highest performance, especially on easier tasks. A fine-tuned version of Qwen3-VL-4B-Instruct demonstrates significant improvement in success rate, particularly on intermediate difficulty levels, and achieves strong sim-to-real transfer, maintaining most of the training gains on real devices. Proprietary models consistently outperform open-source models across all difficulty levels, with Gemini 3.1 Pro leading the results. Fine-tuning the Qwen3-VL-4B-Instruct model significantly improves success rates, especially on L2 and L3 tasks, with strong retention of gains in real-device evaluation. The success rate decreases monotonically with task difficulty, and the hardest tasks (L4) remain challenging for all models, indicating a performance frontier.
The the the table compares the cost of using different judgment methods for evaluating agent trajectories at various scales. It shows that using a VLM judge like Qwen3.6-Plus or GPT-5.4 incurs significant API costs that scale with the number of trajectories, while a code-level judge remains cost-free. The costs for VLM judges increase substantially at larger scales, with GPT-5.4 being notably more expensive than Qwen3.6-Plus. Using a VLM judge incurs API costs that increase with the number of trajectories, while a code-level judge is free of such costs. The cost of using GPT-5.4 is substantially higher than Qwen3.6-Plus for the same evaluation scale. At large-scale training, the API cost for VLM judges becomes a significant factor compared to the cost of code-level judging.

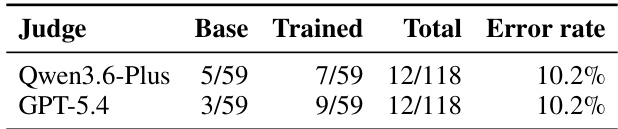
The authors analyze the error rates of two vision-language models, Qwen3.6-Plus and GPT-5.4, when judging real-device task outcomes in a sim-to-real transfer experiment. Both models exhibit identical overall error rates on the evaluated trajectories, indicating consistent misjudgment patterns despite differences in their internal reasoning. The error analysis reveals that the trained model's more complex trajectories lead to slightly higher misjudgment rates compared to the base model, suggesting that increased trajectory complexity can introduce more opportunities for VLM judges to misinterpret outcomes. Qwen3.6-Plus and GPT-5.4 show the same overall error rate when evaluating real-device task outcomes. The trained model has a higher misjudgment rate than the base model, likely due to more complex trajectories. Both models exhibit consistent error patterns, suggesting the errors are not model-specific but stem from the judging task itself.
The evaluation setup compares proprietary and open-source models across varying task difficulties while benchmarking VLM-based and code-level judgment methods for scalability and reliability. Results indicate that proprietary models consistently lead in performance, though targeted fine-tuning and GUI-specialized architectures allow certain open-source models to remain competitive. Cost analysis confirms that VLM judges become prohibitively expensive at scale, whereas code-level judging offers a free and highly efficient alternative. Finally, error analysis reveals that while sim-to-real transfer effectively preserves training gains, increased trajectory complexity systematically introduces misjudgment patterns that affect all VLM judges equally.