Command Palette
Search for a command to run...
ماكرون-إيه2يوآي: نموذج لواجهة المستخدم التوليدية في الوكلاء الشخصيين
ماكرون-إيه2يوآي: نموذج لواجهة المستخدم التوليدية في الوكلاء الشخصيين
الملخص
مع تطور الوكلاء الشخصيين للتعامل مع مهام معقدة تركز على المستخدم، أصبحت محادثات النصوص الثابتة البسيطة تتحول بسرعة إلى عنق زجاجة. تبرز واجهة المستخدم التوليدية كطبقة واجهة جديدة ضرورية، حيث تقوم بتركيب عناصر التحكم والخيارات والحالة المناسبة ديناميكياً من سياق التفاعل في الوقت الفعلي. نقدم نموذج Macaron-A2UI لواجهة المستخدم التوليدية في الوكلاء الشخصيين. هدفنا هو تجاوز التفاعل القائم على النص فقط من خلال تمكين الوكلاء من توليد اللغة الطبيعية مع إجراءات واجهة المستخدم الخفيفة والقابلة للتنفيذ لجمع المعلومات، وتحسين التفضيلات، والتأكيد، وتنظيم الأهداف المتعددة. نبني مجموعة بيانات ضخمة لواجهة المستخدم التوليدية من مصادر حوارية متنوعة، ونقدم A2UI-Bench للتقييم الخاضع للرقابة، ونقوم بتدريب نماذج بأحجام 30 مليار و235 مليار و754 مليار معلمة باستخدام ضبط دقيق خاضع للإشراف فعال من حيث المعلمات يعتمد على LoRA، يتبعه تعلم تعزيزي مدفوع بالمكافآت. يحقق أفضل نموذج لـ Macaron-A2UI نتيجة إجمالية قدرها 75.6 على A2UI-Bench دون استخدام تلميحات مخططات صريحة، متفوقاً بذلك على أقوى أساس للمقارنة من النماذج الحدودية التي تستخدم مخططات كاملة. نطلق النماذج، والمعايير، وبروتوكول التقييم لدعم الأعمال المستقبلية حول واجهة المستخدم التوليدية للوكلاء الشخصيين.
One-sentence Summary
The authors propose Macaron-A2UI, a generative UI model for personal agents that pairs natural language with executable interface actions, is trained via parameter-efficient LoRA-based supervised fine-tuning followed by reward-driven reinforcement learning on a large-scale heterogeneous dialogue corpus, and achieves a 75.6 overall score on A2UI-Bench without explicit schema hints, surpassing the strongest full-schema frontier baseline.
Key Contributions
- The paper introduces Macaron-A2UI, a model that generates natural language alongside executable UI actions under a fixed declarative protocol to support dynamic interfaces for personal agents. The model is trained using a two-stage pipeline that combines parameter-efficient LoRA-based supervised fine-tuning with reward-driven reinforcement learning.
- This work constructs a large-scale Generative UI corpus from heterogeneous dialogue sources and releases A2UI-Bench, a controlled evaluation framework for assessing the protocol compliance and interaction quality of dynamically generated interfaces.
- Experiments demonstrate that this training approach improves protocol correctness and interaction quality, with the best 235B model achieving a 75.6 overall score on A2UI-Bench without explicit schema hints. These results indicate that generative interface capabilities can be internalized during training rather than relying on heavy schema prompting at inference time.
Introduction
As personal AI agents tackle increasingly complex, user-centric tasks, static plain-text interfaces are becoming a bottleneck. Generative UI addresses this by dynamically synthesizing lightweight, executable controls that streamline information collection, preference refinement, and multi-goal organization directly within the interaction loop. Prior research has largely focused on text-only dialogue, code generation, or navigating pre-existing interfaces, leaving a critical gap in large-scale UI-grounded training data, rigorous evaluation benchmarks, and proven methods for models to internalize interface generation without verbose schema prompts. The authors leverage a unified framework to produce natural language alongside executable A2UI action sequences. They construct a large-scale generative UI corpus, introduce the A2UI-Bench evaluation suite, and train models using a parameter-efficient two-stage pipeline of supervised fine-tuning and reward-driven reinforcement learning. Their approach demonstrates that agents can internalize structured interface generation, achieving top-tier performance in a minimal-prompt setting without explicit schema hints.
Dataset

-
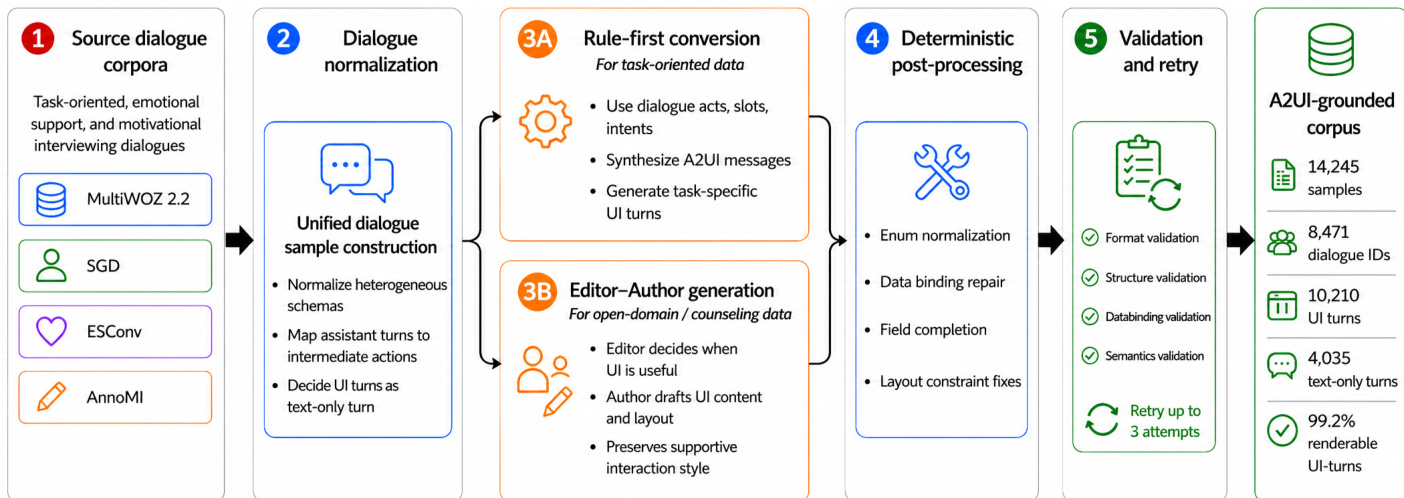
Dataset Composition and Sources: The authors construct an A2UI-grounded dialogue corpus by integrating four heterogeneous source datasets: MultiWOZ 2.2 and Schema-Guided Dialogue (SGD) for task-oriented assistance, ESCONv for emotional support, and AnnoMI for motivational interviewing.
-
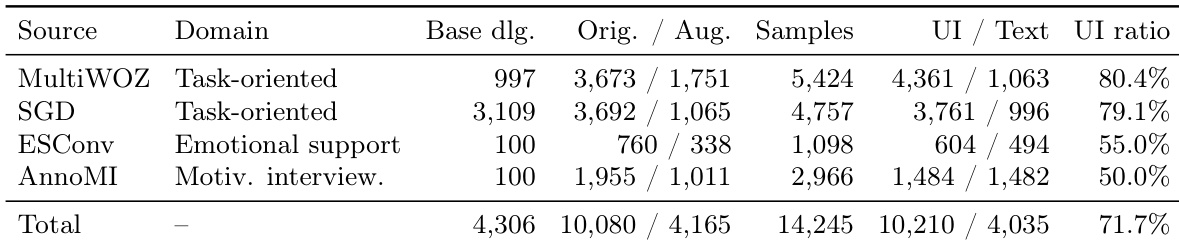
Subset Details and Sampling Strategy: The final training corpus contains 14,245 assistant-turn samples drawn from 4,306 base dialogues, split into 10,210 UI-turns and 4,035 text-only turns. AnnoMI is filtered to retain only a high-quality subset and expanded via component-targeted augmentation. SGD applies a single-turn sampling strategy, extracting just one highly informative assistant turn per dialogue to prioritize service coverage over dialogue depth.
-
Processing and Validation Pipeline: Consecutive utterances from the same speaker are merged to enforce strict user-assistant alternation and remove segmentation artifacts. The authors then normalize heterogeneous annotations into a unified intermediate representation, mapping dialogue acts and counseling behaviors to specific A2UI component families like selection widgets, sliders, checkboxes, and date pickers. A four-level linting pipeline validates JSON formatting, structural typing, data binding, and semantic consistency. Failed samples undergo up to three error-feedback retries, achieving a 99.2% final renderability rate.
-
Training Usage and Dataset Characteristics: The authors use the corpus for large-scale model supervision, intentionally preserving the natural UI-to-text ratios of the source domains. Task-oriented sources maintain a high UI ratio around 80%, while supportive dialogue sources remain balanced to avoid distorting empathetic interactions. The dataset provides approximately 189,000 component-level instances, teaching the model when to trigger UI, what components to select, and how to generate protocol-compliant outputs through a blend of original samples and targeted augmentation.
Method
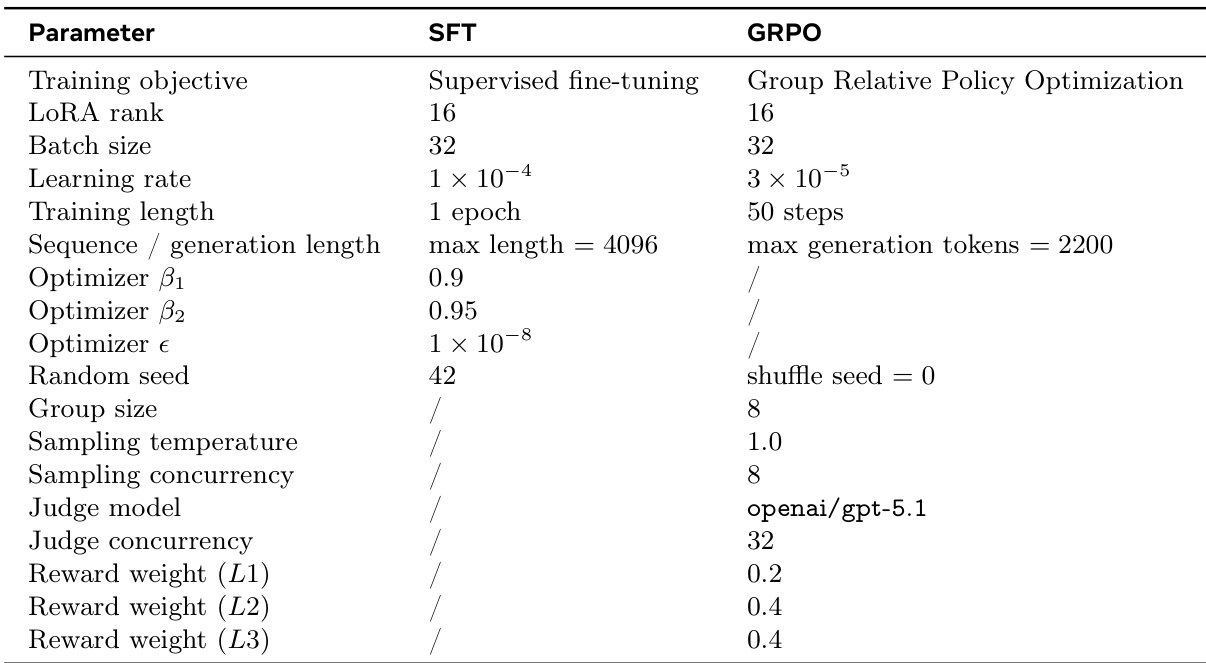
The authors leverage a parameter-efficient two-stage training pipeline for developing an A2UI-capable assistant, which consists of supervised fine-tuning (SFT) followed by group-relative policy optimization (GRPO). Both stages employ LoRA adaptation to update a small set of low-rank parameters, avoiding full fine-tuning of the backbone model. The pipeline is instantiated on Qwen3-30B-A3B-Instruct-2507 and Qwen3-235B-A22B-Instruct-2507, with GLM-5.1 included as an additional backbone, while maintaining a fixed output protocol across all training stages. The training objective is to produce a unified assistant response that integrates natural language text and structured A2UI actions.
The SFT stage teaches the model the fundamental response format by training on chat-style prompt-response pairs. Each sample includes a system instruction and dialogue history, with the target response structured as a JSON object containing a natural language text_response and a list of A2UI actions. The training objective is the standard autoregressive negative log-likelihood, computed only on the final assistant turn of the conversation. This approach directly instructs the model to jointly generate fluent text and executable UI actions, treating interface generation as an intrinsic part of the response rather than a post-processing step.
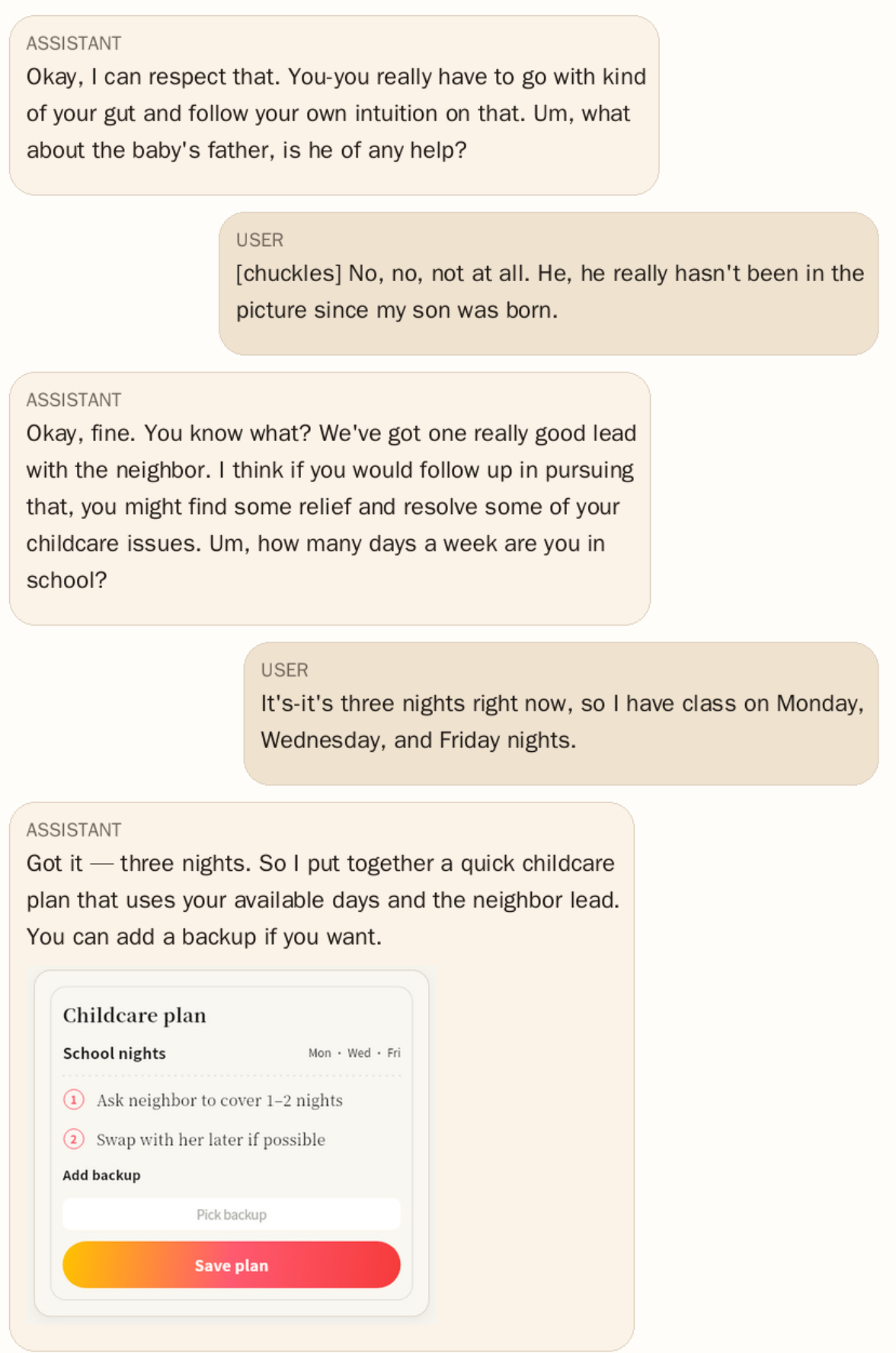
Following SFT, the GRPO stage refines the model's behavior under an interaction-oriented reward. Starting from the SFT model, the policy is optimized using group-relative advantages. For each prompt, a group of candidate responses is sampled, and each is scored by a reward function that evaluates structural quality, task-construction quality, and user-level utility. The advantage is computed as the difference between a candidate's reward and the group mean, which is then used to compute the optimization objective. This stage is particularly effective for properties difficult to supervise with a single gold target, such as UI triggering, action completeness, and interaction quality across structurally different valid responses.
The GRPO reward function is designed around executable A2UI quality, incorporating hard structural gates for malformed JSON, missing A2UI output, protocol-level validation failure, and render-critical errors, all of which result in zero reward. For valid responses, the reward is a weighted combination of low-level correctness (SL1), task-construction quality (SL2), and user-level utility (SL3). This design ensures that reinforcement learning aligns with the core goal of producing responses that are simultaneously executable, appropriate, and genuinely helpful in interaction.
Experiment
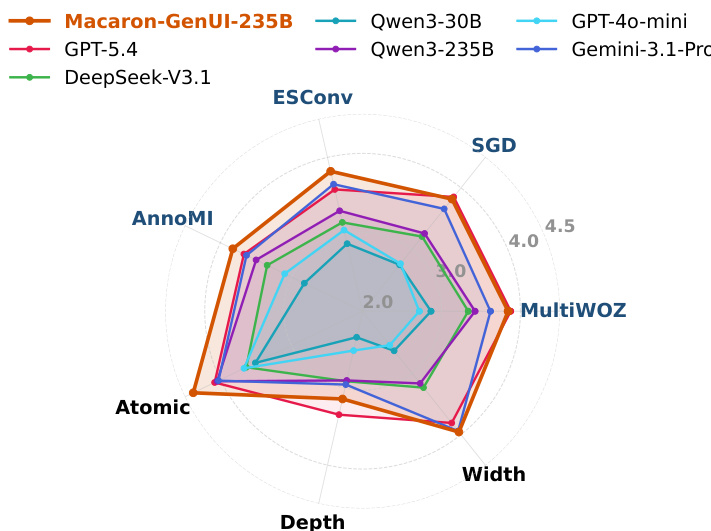
The evaluation assesses A2UI generation through complementary language-side protocol checks and visual-side rendering assessments, testing models under lightweight prompt-only conditions to validate internalized competence and schema-heavy prompts to establish performance upper bounds. These experiments validate a supervised fine-tuning and reinforcement learning pipeline, demonstrating that trained models significantly outperform untuned frontier models when operating without explicit schema instructions. Qualitative analysis indicates that reinforcement learning first stabilizes foundational protocol and structural skills before gradually refining higher-level interaction design and cross-domain adaptability. Ultimately, the approach enables models to reliably translate dialogue intent into concise, visually coherent, and interaction-ready user interfaces.
The the the table presents a breakdown of the evaluation dataset by source, domain, and data type, showing the number of dialogue samples and their distribution between text and UI components. The data indicates a balanced distribution across different domains and source datasets, with a consistent UI-to-text ratio across all categories. The dataset spans multiple domains including task-oriented, emotional support, and motivational interview, with a consistent UI-to-text ratio across all sources. The evaluation set is balanced across the four source datasets and three task formats, ensuring results are not skewed by any single source. The total number of samples is distributed between original and augmented data, with a higher proportion of augmented data in most categories.
The authors evaluate A2UI generation using language-side and visual-side metrics, comparing models under schema-light and schema-heavy settings. Results show that supervised fine-tuning and reinforcement learning significantly improve performance across model scales, with trained models achieving strong results even without full schema prompts, while frontier models require schema hints to reach competitive levels. Supervised fine-tuning and reinforcement learning lead to substantial improvements in both language and visual evaluation metrics across model sizes. Trained models achieve strong performance without schema prompts, outperforming untuned frontier models that require schema hints to reach competitive levels. The largest trained model achieves the highest overall score and demonstrates strong cross-domain robustness, with significant gains in task construction and interaction quality.
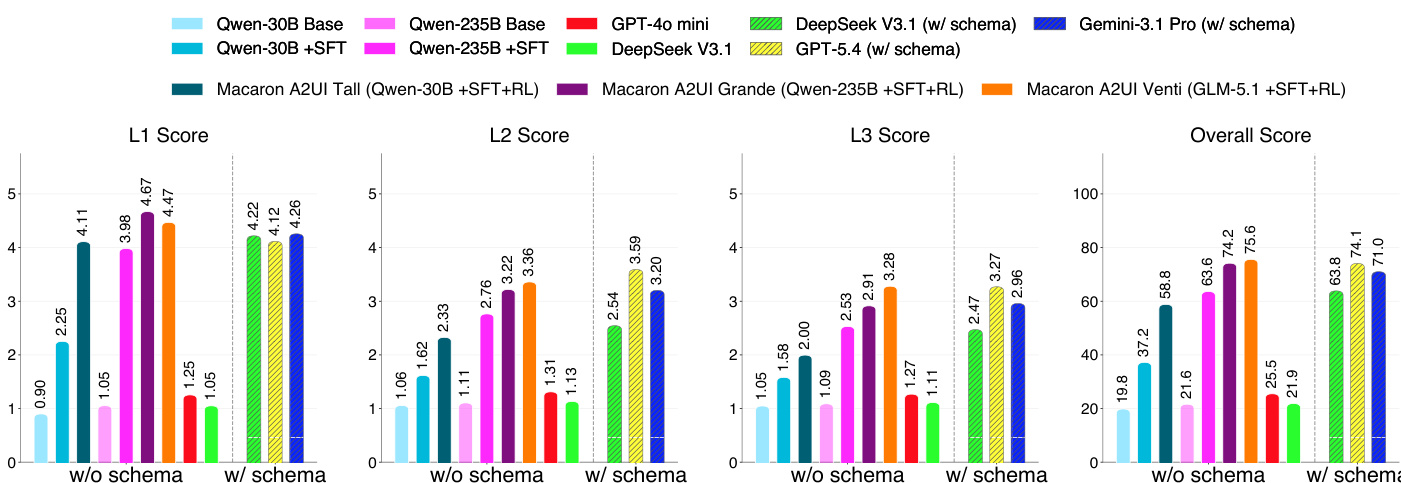
The authors evaluate model performance on A2UI generation using language-side and visual-side metrics, comparing models under schema-inclusive and schema-light prompts. Results show that fine-tuned models achieve higher scores than untuned ones, with performance varying across different evaluation dimensions such as protocol correctness and interaction quality. Fine-tuned models achieve higher overall scores than untuned models under schema-light prompts. Performance varies across evaluation dimensions, with some models excelling in protocol correctness while others perform better in interaction quality. Models trained with reinforcement learning show improved performance across multiple metrics compared to supervised fine-tuning alone.
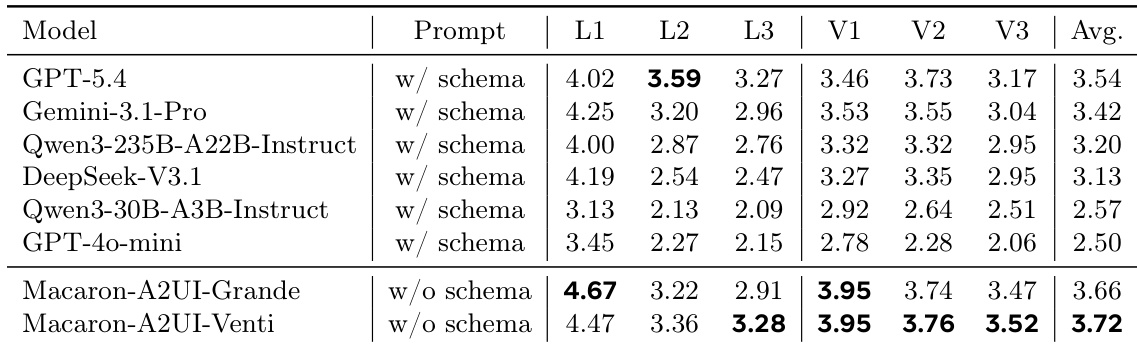
The authors evaluate A2UI generation using language-side and visual-side metrics, focusing on protocol correctness, task construction, and interaction quality. Results show that supervised fine-tuning and reinforcement learning significantly improve performance across model scales, with trained models outperforming untuned frontier models even without schema hints, and the strongest model achieving high scores across multiple datasets and task types. The trained models demonstrate robustness and consistent improvements in structural and interaction quality, particularly in atomic and width tasks, while showing varied performance in depth tasks. Supervised fine-tuning and reinforcement learning significantly improve A2UI generation performance across model scales. Trained models outperform untuned frontier models without schema hints, demonstrating effective internalization of A2UI competence. The strongest model achieves high and consistent scores across datasets and task types, with notable improvements in atomic and width tasks.
The authors use a two-stage training pipeline consisting of supervised fine-tuning and Group Relative Policy Optimization, with the the the table detailing key hyperparameters for both stages. The training objectives and optimization settings differ between the two stages, with SFT focusing on structural correctness and GRPO emphasizing interaction quality through weighted rewards. SFT uses a learning rate of 1e-4 and trains for one epoch, while GRPO uses a smaller learning rate of 3e-5 and runs for 50 steps. GRPO incorporates judge-based rewards with distinct weights for L1, L2, and L3 components, indicating a focus on improving interaction quality. Both stages use LoRA rank 16 and batch size 32, suggesting consistent adaptation and data processing strategies across training phases.
The evaluation assesses A2UI generation across a balanced multi-domain dataset using language and visual metrics under varying prompt conditions. These experiments validate the impact of supervised fine-tuning and reinforcement learning by comparing trained models against untuned frontier baselines. Qualitatively, the combined training approach significantly enhances structural accuracy and interaction quality, enabling models to perform competitively without explicit schema prompts while demonstrating robust cross-domain generalization.