Command Palette
Search for a command to run...
ECHO: وكلاء الطرفية يتعلمون نماذج العالم مجانًا
ECHO: وكلاء الطرفية يتعلمون نماذج العالم مجانًا
Vaishnavi Shrivastava Piero Kauffmann Ahmed Awadallah Dimitris Papailiopoulos
الملخص
تمثل وكلاء سطر الأوامر (CLI agents) الأقرب إلى الإعداد الجسدي (embodied setting) لدى نماذج اللغة؛ حيث يُصدر النموذج أوامر، ويُنفذها الطرفية (terminal)، بينما يسجل تدفق الإرجاع—المتمثل في المعايير القياسية، والأخطاء، والملفات، والسجلات، والمسارات—عواقب تلك الأفعال. نجادل في أن هذا التدفق يشكل إشارة إشراف، إلا أن خوارزميات التعلم المعزز (RL) التقليدية للوكلاء تتجاهله: فتعمل تحديثات التدريب على غرار GRPO على تعديل رموز الأفعال باستخدام مكافآت متفرقة على مستوى النتيجة النهائية، مع إهمال استجابات البيئة الموجودة بالفعل في مسار التمرير الأمامي (rollout). وتساهم مسارات التمرير الفاشلة في حد أدنى من إشارات تدرج السياسة، رغم احتوائها على أدلة غنية حول كيفية استجابة البيئة.نقدم هنا هدفًا هجينًا جديدًا يُعرف بـ ECHO (الهدف الهجين للمقايضة التبادلية البيئية)، وهو يجمع بين خسارة تدرج السياسة القياسية المطبقة على رموز الأفعال، وخسارة إضافية تُدرّب السياسة على توقع رموز ملاحظات البيئة الناتجة عن أفعالها الخاصة. يعيد ECHO استخدام نفس عملية التمرير الأمامي المستخدمة في GRPO، ولا يتطلب إجراء مسارات تمرير إضافية (rollouts)، بل يحول ملاحظات الطرفية إلى إشراف كثيف لجميع مسارات التمرير.أدى تطبيق ECHO إلى مضاعفة أداء GRPO في مقياس Pass@1 على benchmark TerminalBench-2.0؛ حيث تحسّن أداء نموذج Qwen3-8B من 2.70% إلى 5.17%, وتحسّن أداء نموذج Qwen3-14B من 5.17% إلى 10.79%. كما ينتج ECHO سياسات تتوقع ديناميكيات الطرفية بدقة أكبر، حتى على المسارات التي لم يولدها النموذح نفسه؛ فخلال مسارات التمرير المحجوبة (held-out rollouts)، يُقلل ECHO بشكل حاد من دالة الخسارة التبادلية للبيئة (environment-token cross-entropy)، في حين أن استخدام GRPO وحده لا يُحدث تغييرًا ملحوظًا فيها.
One-sentence Summary
ECHO (Environment Cross-entropy Hybrid Objective) enables terminal agents to learn world models by combining standard policy-gradient loss with an auxiliary loss predicting environment observation tokens, turning terminal feedback into dense supervision without additional rollouts, doubling GRPO pass@1 on TerminalBench-2.0 as Qwen3-8B improves from 2.70% to 5.17% and Qwen3-14B from 5.17% to 10.79% while reducing environment-token cross-entropy on held-out rollouts.
Key Contributions
- This work introduces ECHO, a hybrid objective for CLI agents that combines standard policy-gradient loss with an auxiliary loss to predict resulting environment observation tokens. The method reuses the same forward pass as GRPO without requiring additional rollouts, effectively turning terminal feedback into dense supervision for all trajectories.
- Unlike approaches relying on judges or separate world-modeling stages, the proposed method injects observation prediction directly into on-policy GRPO using raw environment-observation tokens. This design eliminates the need for a separate corpus or dynamics model while leveraging existing transcript data as context.
- Evaluation on TerminalBench-2.0 shows ECHO doubles GRPO pass@1 scores, improving Qwen3-14B from 5.17% to 10.79%. Trained policies also better predict terminal dynamics, sharply reducing environment-token cross-entropy on held-out rollouts compared to GRPO alone.
Introduction
In the context of terminal agents powered by large language models, learning effective policies is often hindered by sparse reward signals during environment interaction. Previous methods attempt to densify learning through auxiliary predictions or world models, yet they typically depend on separate training stages, external judges, or complex dynamics models to generate necessary supervision. The authors leverage terminal observations already present in agent transcripts to inject an auxiliary cross-entropy loss directly into on-policy GRPO. This strategy eliminates the need for separate corpora or feedback generators while providing dense supervision derived directly from the environment's literal response.
Dataset
-
Dataset Composition and Sources
- The authors construct the training corpus from 2700 curated terminal tasks sourced from Endless Terminals and OpenThoughts-Agent-v1-RL.
- They expand this pool by generating 6170 additional tasks via a modified Endless Terminals pipeline.
- The final collection comprises 8870 tasks focused on data processing, system operations, and development tooling.
-
Filtering and Selection Criteria
- Initial filtering excludes domains involving analysis, computation, specialized applications, infrastructure, networking, and complex bash.
- Tasks are retained only if GPT-5 solves them within at least one of 16 attempts.
-
Data Splits and Usage
- The training split includes 8770 tasks used for model optimization.
- A separate set of 100 tasks is held out for in-distribution validation under the name val100.
- Evaluation benchmarks include TerminalBench-2.0 and OpenThoughts-TBLite alongside the internal sets.
-
Environment and Processing Details
- Episodes run in Docker containers orchestrated by the Harbor framework.
- Limits are set to 16 turns per episode with a 16k context window.
- Verification uses unit tests with 10-minute agent and 2-minute verifier timeouts.
- The pipeline handles task specification, Dockerfile generation, and Harbor-format export.
Method
The ECHO method introduces a hybrid objective designed to utilize environment feedback as a dense supervision signal during reinforcement learning for terminal agents. Standard training pipelines typically apply loss functions only to assistant action tokens, ignoring the rich information contained in the terminal responses. ECHO augments this process by adding an auxiliary cross-entropy loss on the environment observation tokens.
The training framework operates on a multi-turn rollout sequence that interleaves system prompts, user tasks, assistant actions, and environment observations. The policy generates actions conditioned on the prior transcript, and the environment responds with outputs such as stdout, stderr, or file contents. As illustrated in the framework diagram below:
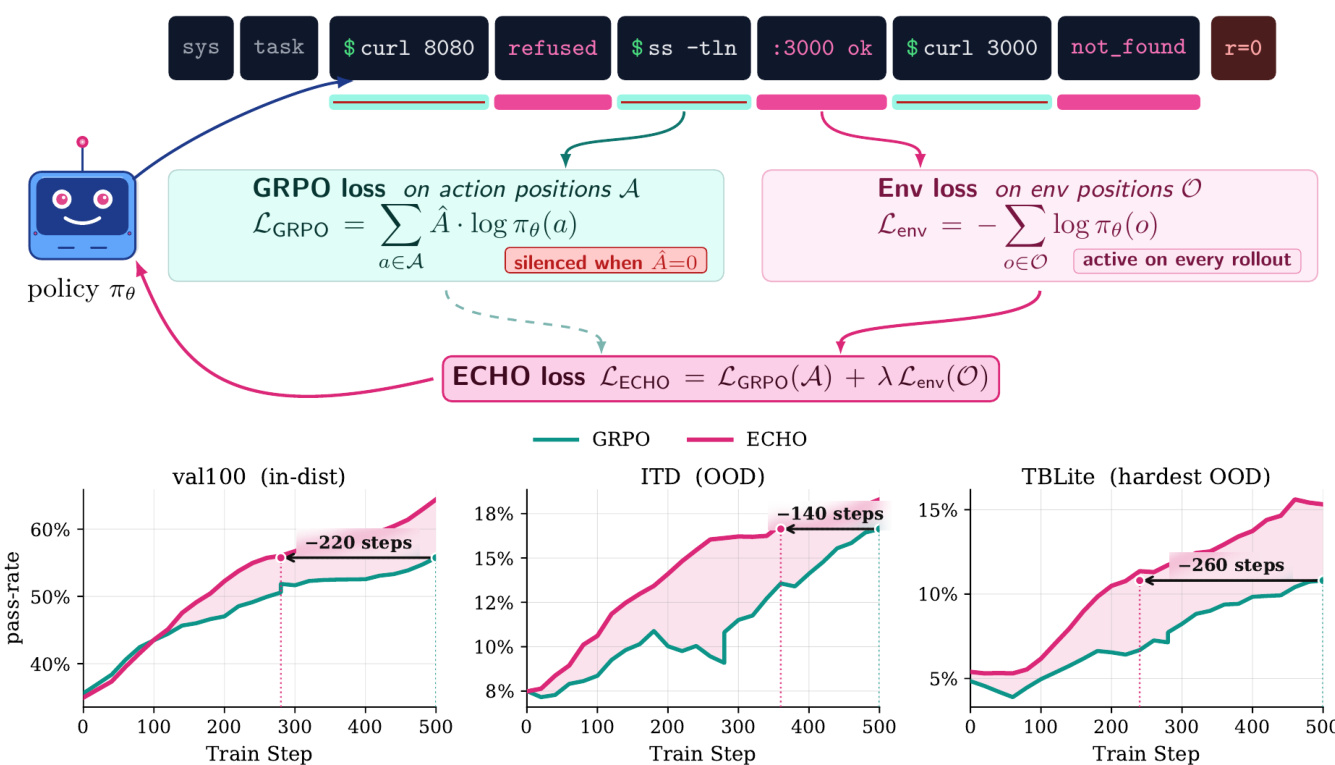
The total loss function combines the standard policy gradient term with the environment prediction term. The GRPO component targets action positions A and relies on group-normalized advantages derived from sparse outcome rewards. This term is silenced when the advantage is zero. Concurrently, the environment loss targets observation positions O and trains the policy to predict the terminal output resulting from its actions. This component remains active on every rollout. The combined objective is defined as:
LECHO=LGRPO(A)+λLenv(O)where λ is a mixing coefficient. This formulation ensures that failed rollouts still contribute to learning by teaching the model how the terminal responds to specific commands.
From an implementation perspective, the method maintains computational efficiency by reusing the same forward pass. The model computes logits for the entire sequence once. The training loop then applies distinct masks to these logits to calculate the respective loss terms. This approach avoids the need for additional rollouts or a separate teacher model. Regarding target selection, the method specifically excludes low-entropy warning tokens from the harness, focusing the environment loss on actual command outputs that provide task-specific feedback.
Experiment
The experiments evaluate ECHO against GRPO baselines and expert SFT initialization across multiple benchmarks to validate improvements in terminal interaction and learning efficiency. Results demonstrate that ECHO consistently enhances task success and terminal prediction accuracy by learning transferable dynamics, which reduces reliance on expert demonstrations while achieving faster training convergence. Additionally, verifier-free adaptation tests confirm that environment prediction alone can drive policy improvement on tasks with informative feedback, supporting the conclusion that agents can learn effectively from terminal consequences without explicit reward signals.
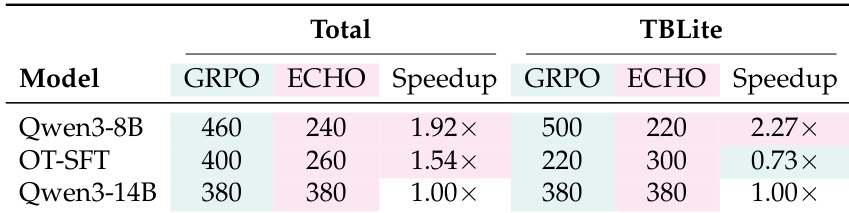
The the the table evaluates training efficiency by comparing the number of steps required for ECHO and GRPO to reach their best internal scores across different model configurations. ECHO demonstrates significant speed advantages for the Qwen3-8B model, converging much faster than the GRPO baseline on both aggregate and difficult out-of-distribution tasks. In contrast, the larger Qwen3-14B model shows no step-based speedup, with both methods reaching peak performance at the same training step. ECHO substantially accelerates training for the Qwen3-8B model, reaching peak performance in significantly fewer steps than GRPO. While the OT-SFT initialization benefits from ECHO on aggregate metrics, it converges slower than GRPO on the specific TBLite benchmark. For the Qwen3-14B model, ECHO and GRPO reach their best internal scores at the same step count, indicating a plateau in convergence speed for larger models.
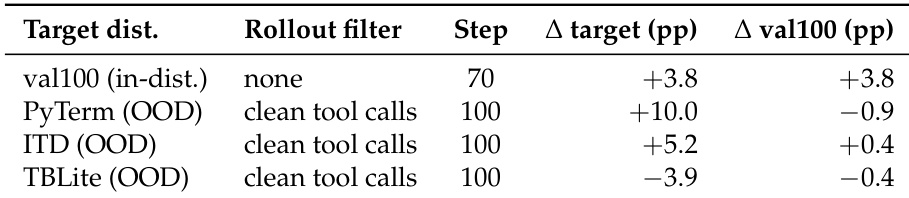
The authors evaluate verifier free adaptation where the model learns solely from predicting terminal output tokens without reward signals. Results indicate that this approach successfully improves performance on in distribution tasks and specific out of distribution benchmarks like PyTerm and ITD when filtering for clean tool calls. However, the method fails to improve performance on the TBLite benchmark, suggesting that the effectiveness depends on the density and action linkage of the environment feedback. Verifier free adaptation improves in distribution performance using only environment prediction. Filtering for clean tool calls enables substantial gains on out of distribution tasks like PyTerm and ITD without degrading base performance. The approach degrades performance on TBLite, likely due to less direct action feedback linkage compared to other benchmarks.
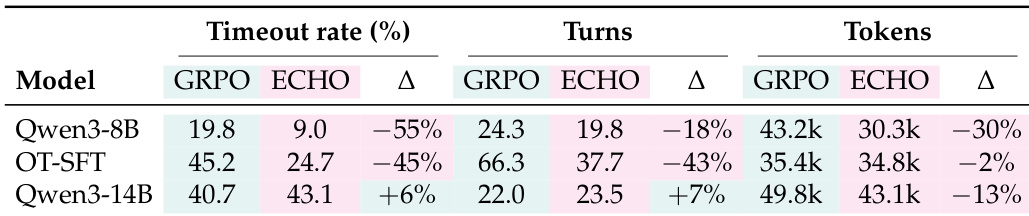
The the the table compares the performance of Qwen3-8B models trained with standard GRPO, the proposed ECHO method, and an expert SFT initialization. Results demonstrate that ECHO consistently outperforms the standard GRPO baseline across all internal and external benchmarks. Additionally, ECHO significantly reduces the performance gap relative to the expert SFT model, recovering the majority of the advantage on internal evaluations and roughly half on external benchmarks. ECHO consistently outperforms the standard GRPO baseline across all internal and external benchmarks. The approach recovers nearly all of the performance advantage provided by expert SFT initialization on internal evaluations. ECHO closes roughly half of the expert SFT performance gap on TerminalBench-2.0 metrics.
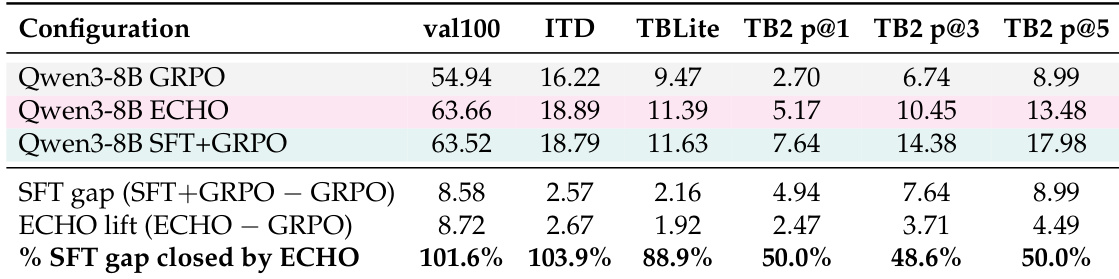
The authors present results showing that the ECHO method consistently improves task success over base policies and GRPO baselines across multiple model sizes. ECHO achieves substantial gains on TerminalBench-2.0 and internal evaluations, matching the performance of expert SFT initialization on internal metrics without requiring expert demonstrations. ECHO consistently outperforms GRPO and base models across all internal evaluations and TerminalBench-2.0 benchmarks. The method nearly doubles the TerminalBench-2.0 pass@1 rate compared to the standard GRPO baseline. ECHO recovers almost all of the performance gain provided by expert SFT initialization on internal evaluations.
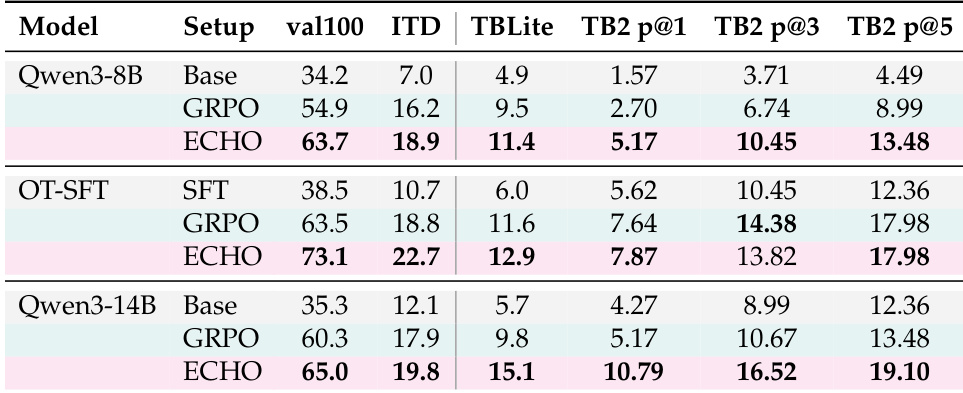
The authors compare inference efficiency metrics, including timeout rates, turns, and tokens, between the GRPO baseline and the ECHO method across different model configurations. The results demonstrate that ECHO generally improves efficiency by reducing timeouts and token usage, particularly for the smaller and SFT-initialized models. ECHO significantly lowers timeout rates and average turns for the Qwen3-8B and OT-SFT models compared to the GRPO baseline. Token consumption is reduced across all model variants, with the most notable decrease seen in the Qwen3-8B configuration. While the Qwen3-14B model experiences a slight increase in timeouts and turns, it still achieves a reduction in total token usage.
The experiments evaluate the ECHO method against GRPO baselines and expert SFT initialization to assess training efficiency, task performance, and inference metrics. ECHO consistently outperforms standard GRPO across internal and external benchmarks while recovering most of the performance advantage provided by expert SFT on internal evaluations without requiring expert demonstrations. While training convergence accelerates for smaller models and inference efficiency improves through reduced token usage, verifier-free adaptation demonstrates effectiveness on specific out-of-distribution tasks but struggles where action feedback linkage is weak.