Command Palette
Search for a command to run...
SkillOpt: استراتيجية تنفيذية لمهارات الوكيل ذاتي التطور
SkillOpt: استراتيجية تنفيذية لمهارات الوكيل ذاتي التطور
الملخص
المهارات الوكيلية اليوم تُصنع يدوياً، أو تُولَّد في خطوة واحدة (one-shot)، أو تتطور من خلال مراجعة ذاتية خاضعة لرقابة ضعيفة؛ ولا يعمل أي من هذه الأساليب كمُحسِّن للتعلم العميق للمهارة، ولا يحسّن بشكل موثوق من أدائه مقارنة بنقطة البداية تحت التغذية الراجعة. نجادل بأن المهارة ينبغي تدريبها بدلاً من ذلك كحالة خارجية لوكيل مُجمَّد (frozen agent)، بنفس الانضباط الذي يجعل تحسين فضاء الأوزان قابلاً للتكرار. يُعد SkillOpt، إلى علمنا، أول مُحسِّن منهجي وقابل للتحكم في فضاء النص لمهارات الوكلاء: حيث يحول نموذج مُحسِّن منفصل المسارات (rollouts) المُقيَّمة إلى تعديلات محدودة الإضافة والحذف والاستبدال على وثيقة مهارة واحدة، ولا يُقبل التعديل إلا عندما يحسّن بشكل صارم درجة التحقق من الصحة المعزولة. تجعل ميزانية معدل التعلم النصية، ومخزن التعديلات المرفوضة، والتحديث البطيء/المتعدد (meta update) على مستوىEpoch، تدريب المهارة مستقراً، مع إضافة صفر استدعاءات لنموذج وقت الاستدلال أثناء النشر. عبر ستة معايير تقييم (benchmarks)، وسبعة نماذج مستهدفة، وثلاثة أطر تنفيذ (direct chat، وCodex، وClaude Code)، كان SkillOpt الأفضل أو متعادلاً في جميع الخلايا الـ52 المُقيَّمة (نموذج، معيار تقييم، إطار تنفيذ)، وتفوق كل منافس في كل خلية بين مهارات الوكلاء البشرية، والذكاء الاصطناعي التوليدي الكبير (LLM) في خطوة واحدة، وTrace2Skill، وTextGrad، وGEPA، وEvoSkill. على GPT-5.5، رفع متوسط الدقة بدون مهارة بـ+23.5 نقطة في الدردشة المباشرة، وبـ+24.8 نقطة داخل حلقة الوكيل في Codex، وبـ+19.1 نقطة داخل Claude Code. تُظهر تجارب النقل أيضاً أن منتجات المهارة المُحسَّنة تحتفظ بقيمتها عند نقلها عبر مقاييس النماذج، وبين بيئات التنفيذ في Codex وClaude Code، وإلى معيار تقييم رياضي قريب دون الحاجة إلى مزيد من التحسين.
One-sentence Summary
SKILLOpt trains agent skills as the external state of frozen models by employing a dedicated optimizer to generate bounded, validation-guided edits, while a textual learning-rate budget and rejected-edit buffer ensure stable training with zero inference-time model calls, ultimately achieving best or tied performance across all 52 evaluated cells and demonstrating robust cross-model and cross-environment transfer without additional optimization.
Key Contributions
- Formulates agent-skill learning as optimization over an external natural-language state and introduces SKILLOPT, a harness-agnostic optimizer that employs a separate model to generate bounded add, delete, and replace edits guided by scored rollouts and held-out validation scores. Stability is maintained through textual learning-rate budgets, rejected-edit buffers, and epoch-wise slow updates.
- Evaluates the framework across six benchmarks, seven target models, and three execution harnesses, demonstrating best or tied-best performance across all 52 evaluated cells. SKILLOPT outperforms human-written, one-shot, and prior optimization baselines including TextGrad, GEPA, and EvoSkill, while lifting average no-skill accuracy by up to 24.8 points on GPT-5.5.
- Validates the optimization design through component ablations and transfer experiments spanning model scales, execution environments, and task domains. The results confirm that optimized skill artifacts remain compact and reusable when deployed without model-weight updates, establishing text-space optimization as a lightweight alternative to parameter adaptation.
Introduction
As frontier models deploy as agents, adapting their behavior requires procedural improvements beyond weight updates or prompts, making agent skills essential for efficient domain adaptation in closed or resource-constrained settings. Prior work relies on hand-crafted or loosely evolved skills that lack reproducible optimization, often failing to improve reliably under feedback or generalize across execution harnesses. The authors introduce SKILLOpt, a text-space optimizer that treats the skill document as an external state. They leverage a separate model to propose bounded edits guided by a validation gate, textual learning rate, and rejected-edit buffer to produce compact, transferable skill artifacts without inference overhead.
Dataset
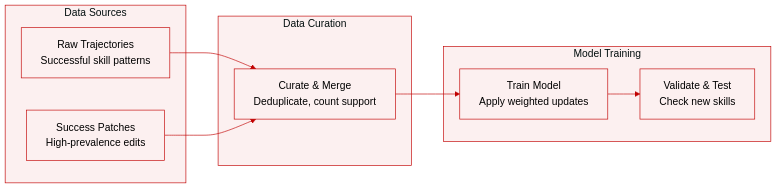
- Dataset composition and sources: The authors construct a curated collection of skill edits extracted from successful trajectories, focusing on patterns that reinforce existing model behaviors.
- Key details and filtering rules: The dataset applies strict curation criteria to ensure quality and generalizability. Similar patterns are deduplicated to retain only the most robust versions. Edits are only included if they target patterns absent from the current skill, and content within predefined markers is explicitly excluded. The authors prioritize prevalent patterns observed across multiple successful trajectories and assign a support count to each merged edit to reflect the number of contributing source patches.
- Data processing and metadata: Each entry is structured as a valid JSON object containing a reasoning summary and an edit list. Every edit record specifies the operation type, an optional target location, the markdown content, the support count, and a source type tagged as success.
- Usage in training: The authors use this processed edit set to merge and reinforce successful behavioral patterns during model training. The support counts and prevalence metrics guide the selection and weighting of updates, enabling the model to acquire new skills through systematic application.
Method
The SKILLOPT framework operates as a structured optimization loop that adapts a frozen target model through iterative refinement of a text-based skill document, treating the skill as a reusable procedural artifact. The overall process begins with a fixed target model M and an initial skill s0, with the optimization focused solely on modifying the skill document while keeping the model weights unchanged. At each optimization step, a rollout batch from the training split is executed using the current skill, generating a trajectory and a scalar score that reflects task performance. This evidence is then processed by an optimizer model, which conducts a hierarchical reflection process to propose skill edits.
As shown in the figure below, the framework first separates failures and successes from the rollout evidence and partitions them into minibatches. The optimizer model analyzes failure minibatches to identify recurring procedural errors and proposes corrective edits, while success minibatches are used to reinforce behaviors that are already effective. These proposals are then merged hierarchically, with failure-driven edits prioritized to address systematic issues. The merged edits are ranked by expected utility and clipped to a bounded edit budget Lt, which acts as a textual learning rate to control the magnitude of updates and prevent overfitting. The selected edits are applied to produce a candidate skill, which is then evaluated on the validation split through a held-out selection gate. This gate ensures that only improvements are accepted, preventing unvalidated self-editing that could degrade performance.

The optimization loop also incorporates an epoch-wise slow/meta update mechanism to capture long-term learning. At the end of each epoch, the system compares the same training tasks under the previous and current epoch-end skills, identifying improvements, regressions, persistent failures, and stable successes. The optimizer model then generates a concise longitudinal guidance block, which is written to a protected slow-update field and passed through the same validation gate. This meta guidance is used to inform future edit generation and selection, enabling the optimizer to learn from the broader optimization trajectory. The slow update is strictly managed and separated from the main skill, ensuring that the deployed skill remains compact and portable.
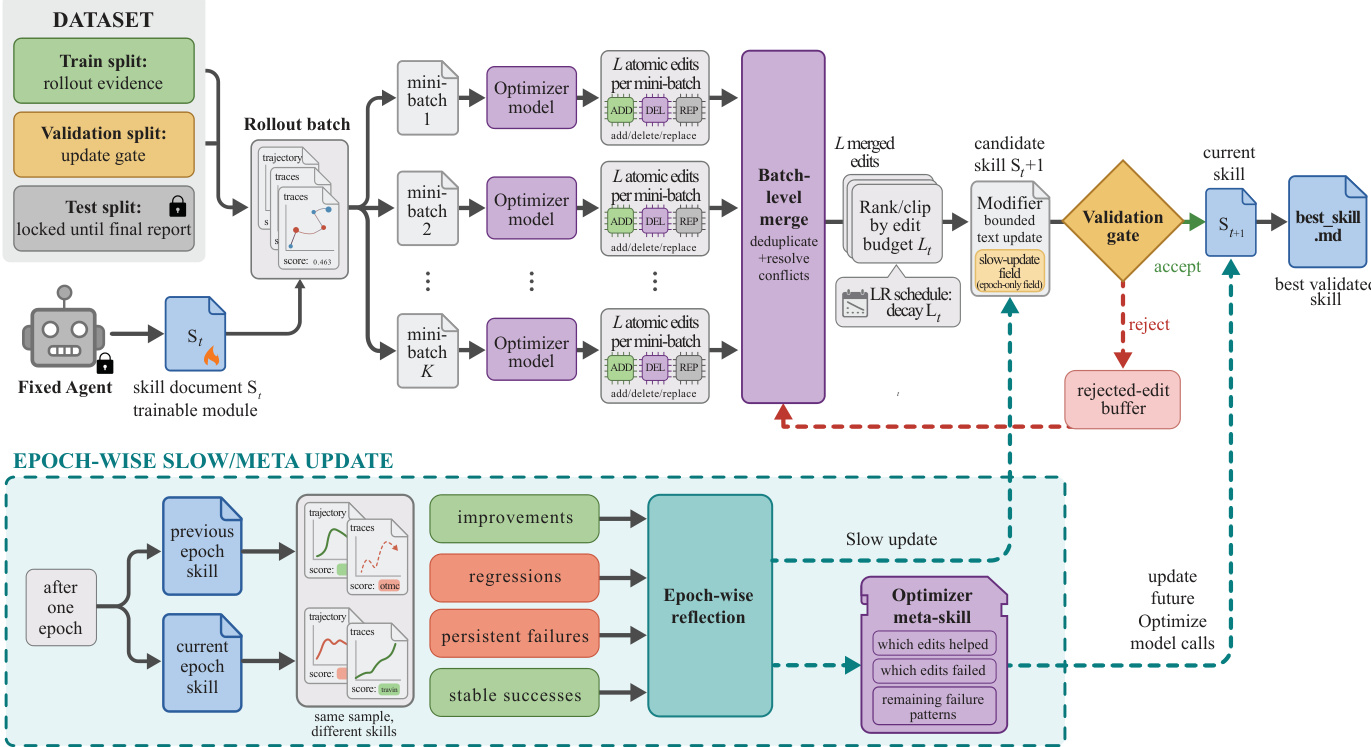
Rejected updates are not discarded but instead stored in a step-local buffer, which is used in subsequent reflection calls to avoid repeating harmful changes. The entire process is designed to be harness-agnostic, with a lightweight adapter interface that allows the same optimization procedure to be applied across different task environments and model architectures. The final output is a best validated skill document, which can be exported and deployed without modifying the underlying model, enabling cross-model and cross-harness generalization.
Experiment
The experiments evaluate SKILLOPT, a text-space optimizer that iteratively refines a compact skill document to adapt frozen language models across diverse benchmarks, model scales, and execution harnesses. Ablation studies validate that bounded edit budgets, strict validation gating, and epoch-wise meta-updates are essential for preventing overfitting and ensuring stable procedural learning. Transfer experiments further demonstrate that the optimized skills function as reusable, interpretable artifacts that generalize effectively across different models, tool environments, and related tasks. Ultimately, the results confirm that treating skill documents as trainable objects provides a highly effective, weight-free adaptation strategy that reliably encodes transferable procedural knowledge.
{"summary": "The authors evaluate a text-space optimization method that improves skills for frozen language models by iteratively refining skill artifacts based on rollout evidence. The results show consistent improvements across multiple benchmarks and models, with gains driven by a controlled editing process that prioritizes validated changes over unverified edits.", "highlights": ["The optimization method consistently improves performance across diverse benchmarks and model scales, with the best or tied-best results in all evaluated cases.", "The gains are achieved through a bounded editing process that accepts only a small number of validated changes, resulting in compact and interpretable skill artifacts.", "The method is effective under different execution environments and transfers well across models, harnesses, and benchmarks, indicating the learned skills encode reusable procedural knowledge."]
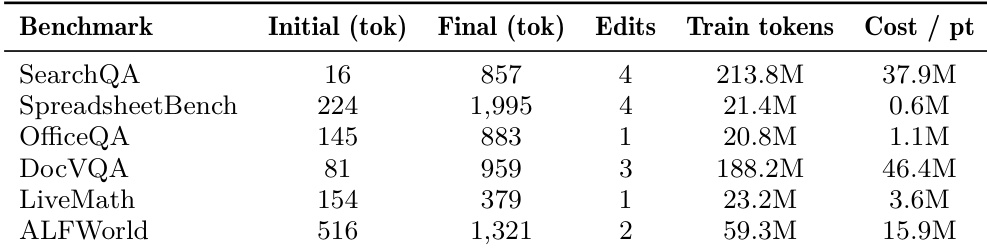
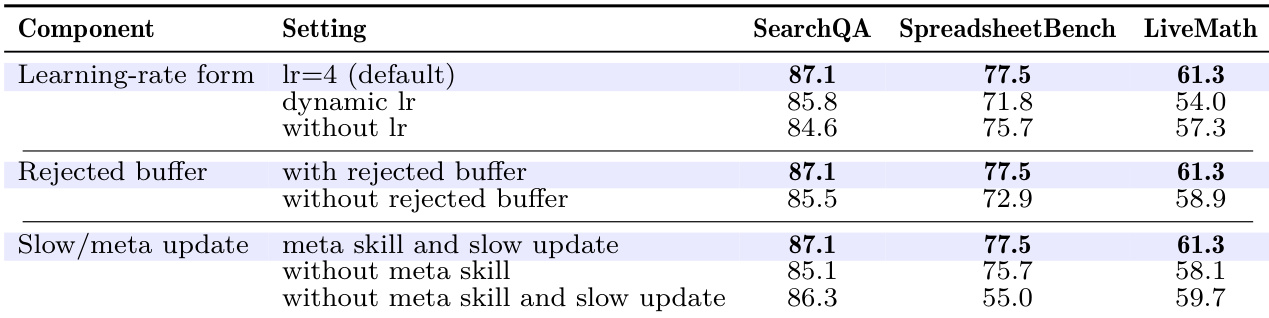
The authors analyze the properties of the learned skill artifacts produced by the optimization process, focusing on their compactness, edit economy, and training cost. Results show that the final skills are small in size, require few accepted edits, and are trained at a measurable cost per point of performance gain, with the training cost being incurred only once before deployment. The learned skills contain procedural rules that are generalizable and consistent with what a human practitioner would write. The optimized skills are compact, with final sizes under 2,000 tokens and requiring only 1 to 4 accepted edits during training. The training cost varies by benchmark, with procedural tasks being significantly cheaper per point of gain than tasks involving longer trajectories or multimodal context. The learned skills consist of procedural rules that are generalizable and reflect discipline in areas such as answer formatting and evidence binding, which frontier models do not apply zero-shot.
The authors evaluate SKILLOPT as a text-space optimizer for frozen language models, testing its performance across multiple benchmarks, models, and execution harnesses. Results show that SKILLOPT consistently outperforms or matches all baseline methods, with significant gains observed across both large and small target models, particularly on procedural tasks. The optimized skills are compact, require few accepted edits, and transfer effectively across different models, harnesses, and benchmarks. SKILLOPT achieves the best or tied-best results across all evaluated benchmarks and target models, outperforming a range of baselines including human-written and one-shot LLM skills. The method produces compact skill artifacts with minimal accepted edits, indicating that gains come from targeted, validated improvements rather than extensive rewriting. Optimized skills transfer effectively across different models, execution harnesses, and related benchmarks, demonstrating their reusability and generalizability.
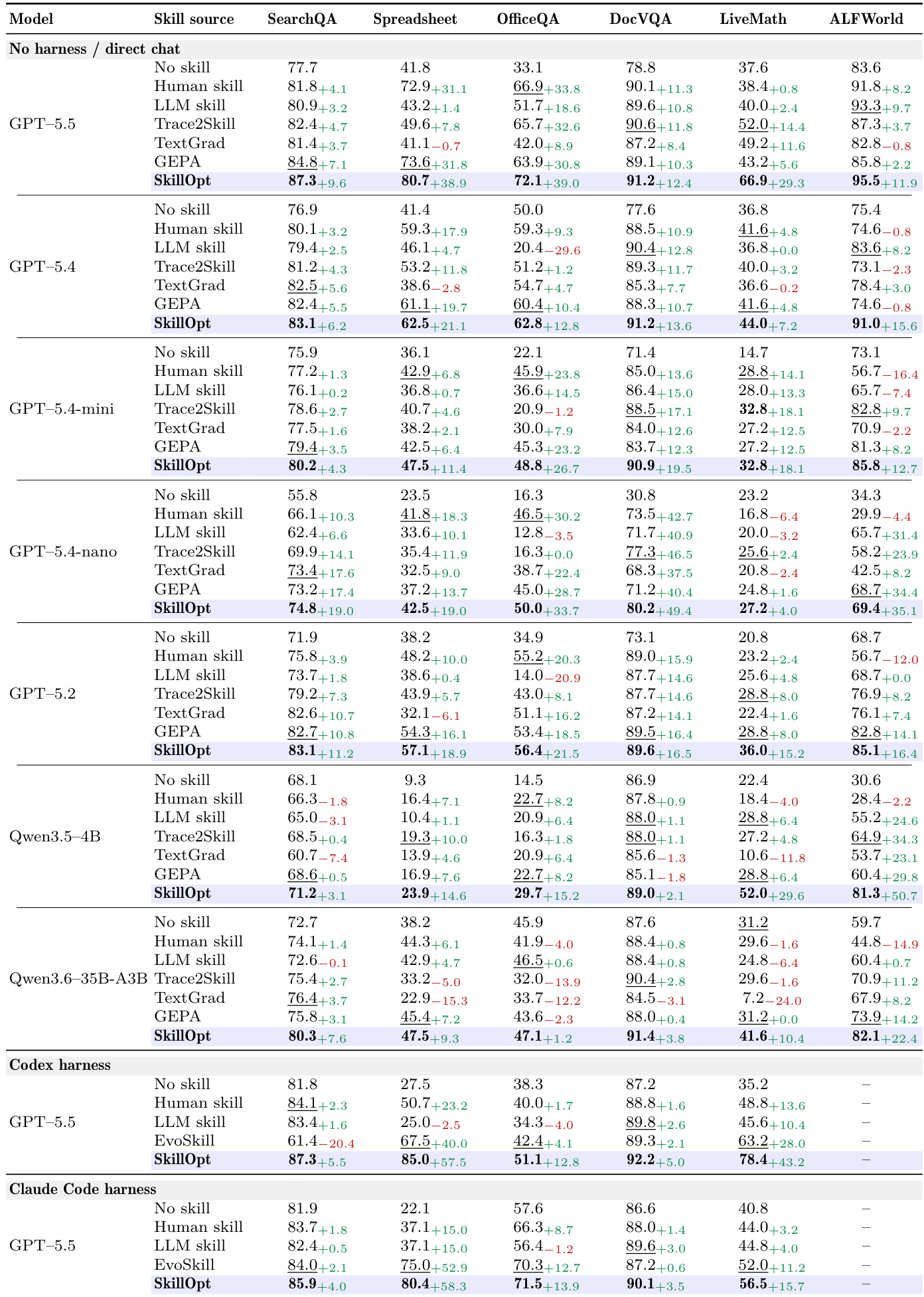
The experiments demonstrate that optimized skills consistently improve performance across different models, execution harnesses, and benchmarks, with gains observed in both direct chat and tool-backed settings. The results show that skills learned in one context can transfer effectively to new models, execution environments, and related tasks, indicating that the learned knowledge is reusable and not tied to specific conditions. Optimized skills transfer successfully across models, harnesses, and benchmarks, with positive gains in all transfer scenarios. Skills learned in one environment show strong performance when deployed in different execution contexts, suggesting transferable procedural knowledge. The learned skills are compact and effective, with improvements achieved through a small number of accepted edits and minimal training cost.
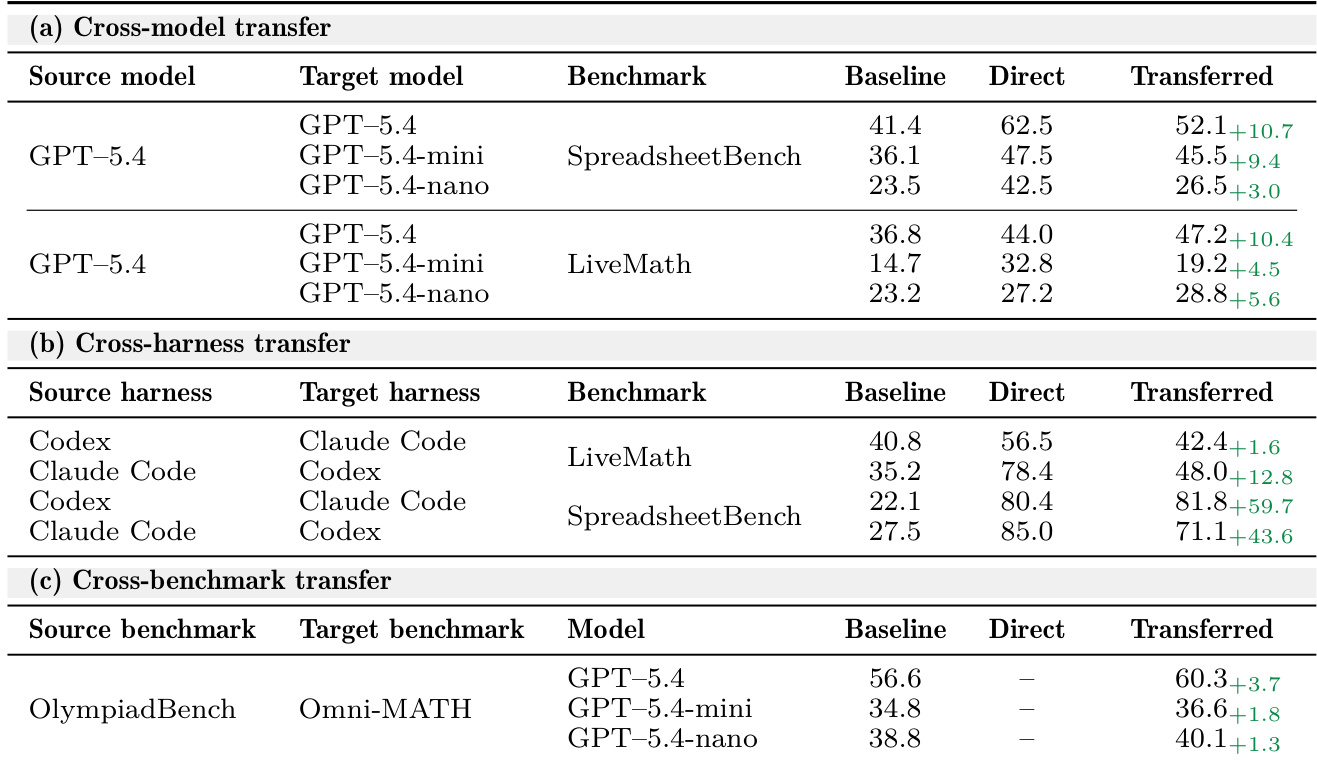
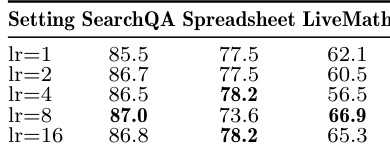
The the the table presents ablation results for key components of the optimization process, showing that the default settings consistently achieve the highest performance across benchmarks. The inclusion of a rejected-edit buffer and slow/meta update mechanisms leads to notable improvements, while the learning-rate form has a more modest impact on results. The default learning-rate form achieves the best or second-best results across all benchmarks. Removing the rejected-edit buffer leads to a significant drop in performance, especially on SpreadsheetBench and LiveMath. The slow/meta update mechanism contributes to improved results, with its absence causing the largest degradation on SpreadsheetBench.
The evaluation tests SKILLOPT across diverse benchmarks, model scales, and execution harnesses to validate its performance gains and cross-context transferability, while ablation studies isolate the contributions of key optimization components like the rejected-edit buffer and meta-updates. Results demonstrate that the method consistently enhances frozen language model capabilities by generating compact, interpretable skill artifacts through highly selective and validated edits. Qualitative analysis reveals that these optimized skills encode generalizable procedural knowledge, such as disciplined answer formatting and evidence binding, which reliably surpass baseline approaches. Ultimately, the experiments confirm that the learned expertise transfers robustly across different models and environments, highlighting the approach's efficiency and practical utility for deploying reusable procedural capabilities.