Command Palette
Search for a command to run...
تقرير تقني لـ StepAudio 2.5
تقرير تقني لـ StepAudio 2.5
الملخص
العنوان: [غير محدد]الملخص: برز النمذجة الموحدة للصوت واللغة كاتجاه بارز في أنظمة الكلام الحديثة، حيث يعد بدمج قدرات الاستدلال الخاصة بنماذج اللغة الكبيرة في المهام السمعية. ومع ذلك، غالباً ما تواجه الأسس الموحدة الحالية صعوبة في مواكبة عمق الأنظمة المتخصصة عبر مجالات التعرف التلقائي على الكلام (ASR)، وتوليف الكلام من النص (TTS)، والتفاعل المنطقي في الزمن الحقيقي. ولا يزال سد هذه الفجوة يمثل تحدياً مفتوحاً. يقدم هذا التقرير نموذج StepAudio 2.5، وهو نموذج أساسي موحد للصوت واللغة يتفوق أو يساوي الأنظمة المتخصصة في جميع القدرات الثلاث. وبدلاً من معاملة هذه المهام على أنها متميزة هيكلياً، نعتمد على الافتراض القائل بأنه بمجرد مشاركة النص والصوت في فضاء تمثيلي متعدد الوسائط، تصبح التخصصات في المهام مسألة تتعلق بأنظمة التشغيل: وهي بناء البيانات، وأهداف التحسين، وقيود فك التشفير. واستناداً إلى هذا البصيرة، نطور نموذج ما بعد التدريب من التعلم الخاضع للإشراف القياسي إلى التعلم المعزز من التغذية الراجعة البشرية (RLHF) المصمم خصيصاً للمهام، مستخدمين إياه كآلية رئيسية لتحديد أهداف التحسين المعقدة. نستغل هذا المحاذاة المتمحورة حول RLHF، جنباً إلى جنب مع فك التشفير المتخصص، لتشكيل العمود الفقري المشترك إلى ثلاثة أوضاع تشغيلية متميزة. وتحديداً، يتقدم فرع التعرف التلقائي على الكلام (ASR) في كفاءة النسخ عبر فك تشفير متعدد الـ tokens قابل للتحقق؛ ويحقق فرع توليف الكلام من النص (TTS) توليفاً قابلاً للتحكم وغنياً بالتعبير من خلال RLHF القائم على التفضيلات والإشراف الغني بالسياق؛ بينما يحقق فرع التفاعل في الزمن الحقيقي حواراً منخفض الكمون ومتسقاً مع الشخصية من خلال نمذجة المكافآت التوليدية ضمن إطار RLHF. وعلى المقاييس القياسية، يحقق StepAudio 2.5 نتائج متقدمة (State-of-the-art) عبر مجالات ASR وTTS والتفاعل في الزمن الحقيقي، مما يثبت أن الأساس الموحد للصوت واللغة يمكنه بنجاح استيعاب أهداف النشر المتميزة لفهم الكلام، وتوليده، والتفاعل المباشر.
One-sentence Summary
StepAudio 2.5, developed by the StepFun-Audio Team, is a unified audio-language foundation model that matches specialized systems in automatic speech recognition, text-to-speech synthesis, and realtime interaction by replacing standard supervised post-training with task-tailored Reinforcement Learning from Human Feedback and specialized decoding to shape a shared backbone into distinct operational regimes, achieving state-of-the-art benchmark performance across all three domains.
Key Contributions
- StepAudio 2.5 is introduced as a unified audio-language foundation model that addresses the performance gap between unified architectures and specialized speech systems by treating task specialization as a function of operational regimes rather than architectural differences. By leveraging a shared multimodal representational space, the framework consolidates automatic speech recognition, text-to-speech synthesis, and realtime spoken interaction into a single backbone.
- The post-training paradigm advances from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF) as the primary mechanism for defining complex optimization targets. This RLHF-centric alignment, combined with specialized decoding constraints, enables the shared backbone to dynamically adapt to distinct deployment objectives across speech understanding, generation, and live interaction.
- Branch-specific implementations include verifiable multi-token decoding for transcription efficiency, preference-based RLHF with context-rich supervision for controllable synthesis, and generative reward modeling for low-latency dialogue. Comprehensive evaluations on standard benchmarks demonstrate state-of-the-art performance across all three capabilities, validating the model's capacity to internalize distinct speech deployment requirements.
Introduction
Unified audio-language modeling is emerging as a key direction for speech systems, as it aims to embed large language model reasoning directly into auditory tasks to streamline infrastructure for recognition, synthesis, and live interaction. Prior unified approaches, however, consistently fall short of specialized systems in performance and functional depth across automatic speech recognition, text-to-speech synthesis, and real-time dialogue. The authors bridge this gap with StepAudio 2.5, a unified foundation that treats these capabilities as distinct operational regimes within a shared multimodal space. They leverage task-tailored reinforcement learning from human feedback to align a single backbone, combining it with specialized decoding and optimization strategies to achieve state-of-the-art performance across all three domains.
Dataset
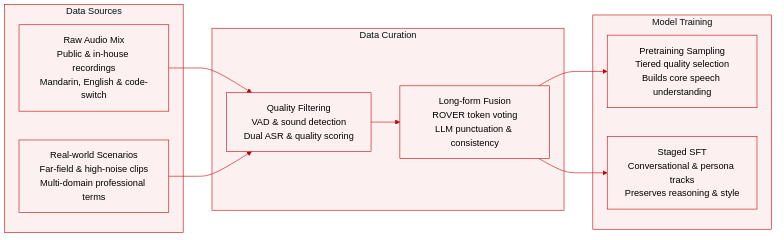
- Dataset Composition and Sources
- The authors construct a unified corpus through an automated production pipeline designed for speech understanding, text-to-speech, and dialogue tasks. The dataset integrates major public corpora, proprietary in-house recordings, and real-world scenario audio spanning Mandarin, English, and frequent code-switching.
- Key Details for Each Subset
- Short-form Supervised Data: Approximately 100K hours of audio capped at 30 seconds per sample. It covers diverse vertical domains, professional terminology, and challenging acoustic conditions like far-field and high-noise environments.
- Long-form Pseudo-labeled Data: A 50K-hour collection designed to train contextual consistency. It is built by concatenating VAD-segmented clips that pass a multi-system verification threshold.
- Realtime SFT Streams: Organized into three parallel tracks. The conversational backbone features multi-turn dialogues with natural disfluencies and mid-utterance revisions. The persona-conditioned stream pairs a million-scale algorithmically generated persona matrix with real-scenario dialogues. The paralinguistic stream attaches atmosphere descriptors and specific vocal cue labels to training samples.
- Data Usage and Training Strategy
- During pretraining, the authors sample from different data quality tiers based on constructed metadata to match specific training stages. The supervised fine-tuning phase adopts a staged objective that mirrors the three Realtime streams. The pipeline down-weights written-style responses to anchor the policy in a spoken register and interleaves a general-capability mixture inherited from mid-training to preserve reasoning abilities.
- Cropping, Metadata, and Processing Details
- Raw audio undergoes sound event and voice activity detection to remove low-quality non-speech segments. Adjacent valid segments are merged and re-segmented into base samples with complete semantics. Each clip receives audio-level annotations for quality scoring, synthetic voice detection, and speaker counting. Text annotations rely on dual ASR models cross-validated using word error rate, edit distance, and speech rate. The authors grade all samples by language, duration, and semantic or audio quality scores to build a comprehensive metadata index. For long-form data, three ASR outputs are normalized and fused via token-level voting. Clips with a disagreement rate exceeding 0.05 are discarded, and surviving segments are refined by an LLM for punctuation, inverse text normalization, and cross-session terminology consistency. A final unified validation pipeline verifies in-character consistency, cross-validates annotations, and removes near-duplicates introduced by the persona fission process.
Method
The architecture of StepAudio 2.5 follows a shared audio-language stack that consists of a frozen audio encoder, a lightweight adaptor, and a large language model (LLM) decoder, forming a unified framework for multimodal processing. This design establishes a clear division of labor: the audio encoder performs stable acoustic abstraction, while the decoder handles semantic understanding, context management, instruction following, and generation. The shared backbone enables the model to support multiple downstream tasks through specialization, including automatic speech recognition (ASR), text-to-speech (TTS), and real-time spoken interaction, all built upon a common foundation. The integration of audio and text tokens within a single sequence space allows the decoder to operate over both modalities seamlessly, treating speech as a sequence modality in addition to text.
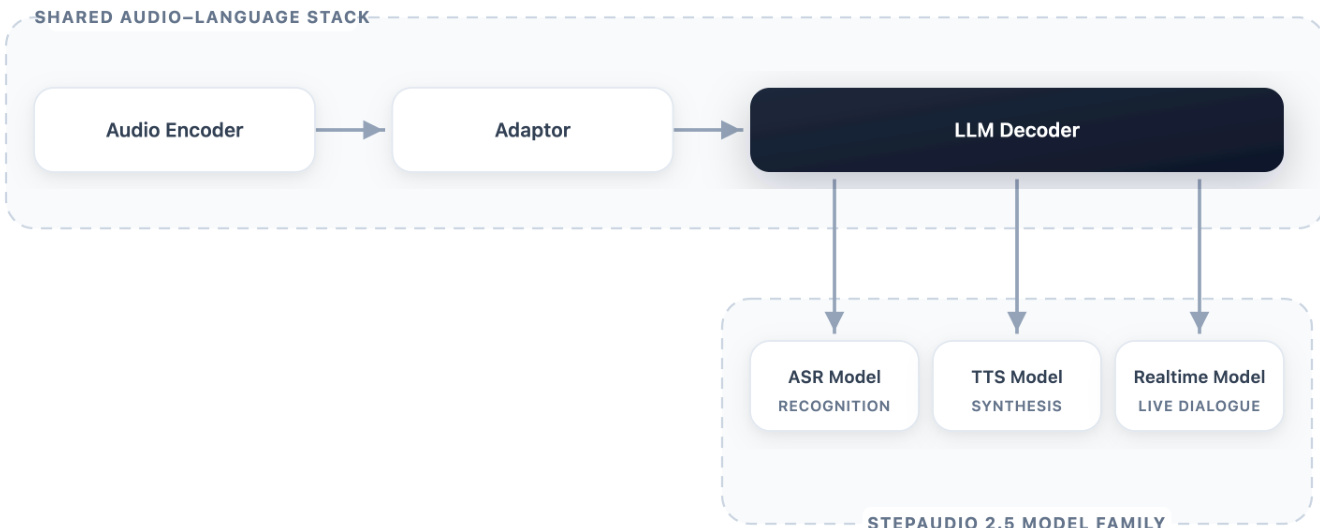
The model is initialized from a textual mixture-of-experts (MoE) LLM and undergoes a staged pretraining curriculum. The first stage aligns the speech and text feature spaces using 3 billion tokens of automatic speech recognition (ASR) data, during which only the adaptor is trained while the encoder and decoder remain frozen. This establishes the initial interface for acoustic features to be consumed by the text-native decoder. Following alignment, the model vocabulary is expanded to include speech tokens, and unified multimodal training begins with a sequence length of 16K, using 800 billion tokens of text and 800 billion tokens of speech data. The speech data encompasses diverse configurations, including ASR, TTS, speech-to-text translation, utterance-level text-speech interleaved continuation, and speech-to-speech conversation, ensuring the model learns an operational interface between audio and text rather than a mere association. This multimodal phase is divided into two stages: a 128-billion-token warmup that stabilizes the speech vocabulary and adapts the MoE experts, and a main training stage where learning rates are normalized and auxiliary losses are annealed to maintain expert utilization and routing balance. Finally, a cooldown phase on 600 billion high-quality tokens, with sequence length increased to 32K, refines long-context capabilities and introduces additional data types such as audio captions and instructive TTS, emphasizing higher-quality multimodal supervision.
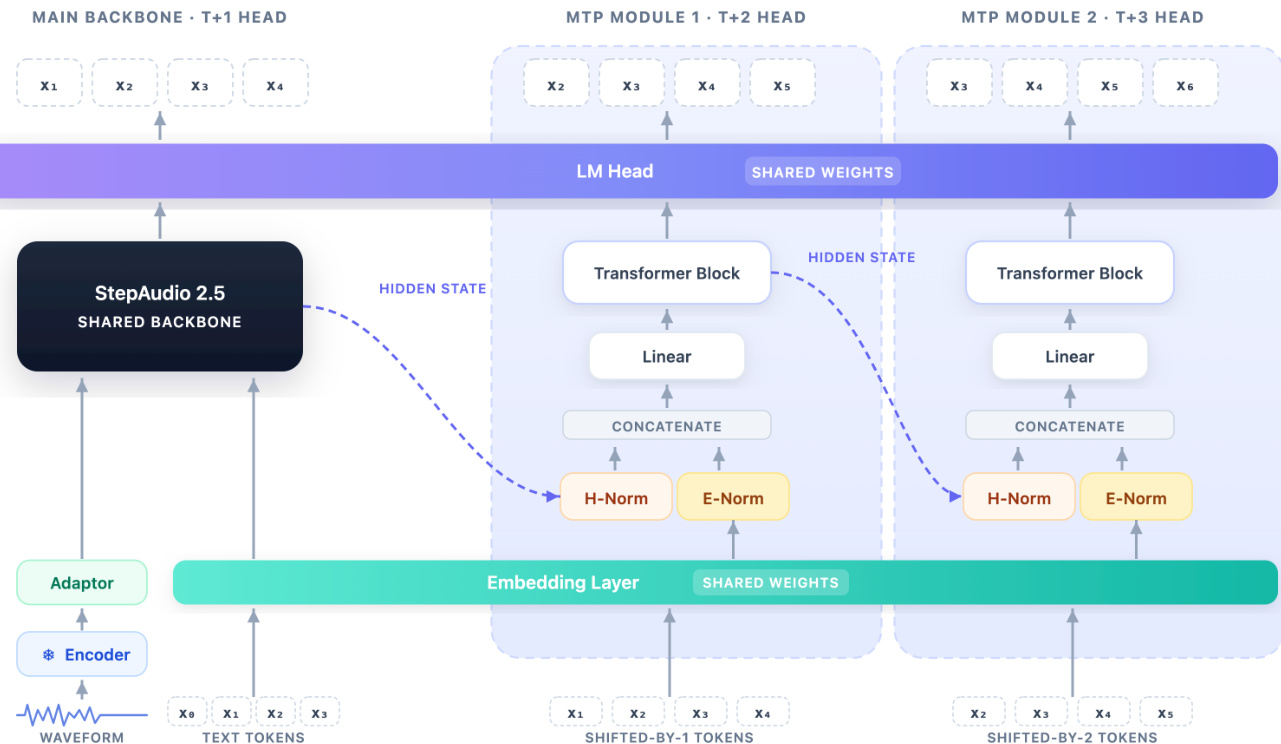
For ASR specialization, the model retains the shared backbone but augments it with a multi-token prediction (MTP) head, as shown in the figure below. This head consists of five parallel future-token branches that propose verifiable future transcript tokens during decoding. At position t, the main branch predicts the next token xt+1, while the h-th MTP branch predicts xt+1+h for h∈{1,…,5}, producing a six-token proposal. The verification mechanism ensures that only a consistent prefix is accepted, preserving autoregressive decoding. Each MTP block receives the hidden state from the previous branch and a shifted token embedding, which are normalized, concatenated, projected back to the decoder hidden size, and processed by a Transformer block. All branches share the same embedding layer and output head as the main decoder. The training pipeline for ASR involves supervised fine-tuning (SFT) to establish a reliable recognizer, followed by staged MTP training. The initial SFT stage freezes the encoder and optimizes the adapter and decoder using a 32K-token sequence budget, SpecAugment-style masking, and a cosine decay learning rate schedule. MTP training begins after convergence, first aligning the frozen branches and then jointly calibrating them with the backbone using a lower learning rate. The training objective combines the standard next-token loss with weighted MTP losses, where branch weights are exponentially decayed to reflect serial dependency.

Experiment
For instance, ASR-based metrics tend to become unreliable in the presence of rich paralinguistic phenomena, while embedding-based speaker verification models typically discard high-frequency acoustic details and fail to accurately capture similarities in prosody, speaking style, and expressive characteristics.
Similarly, LLM-as-a-judge approaches still struggle to reliably assess prosodic quality and complex emotional expression. Subjective MOS evaluation also presents significant limitations, as it requires highly trained annotators and often suffers from inconsistencies in scoring criteria across evaluators
Considering these limitations, the paper adopt an arena-style pairwise evaluation framework, in which models are compared via pairwise preference judgments, and their overall performance is measured by aggregated win rates. To ensure evaluation reliability, the paper invest substantial effort in standardizing the evaluation protocol and improving inter-rater consistency among human evaluators.
Specifically, the paper proceed as follows: (1) the paper first conduct a listening sensitivity screening using a small set of audio samples to select qualified evaluators. Once the evaluation task begins, the set of evaluators remains fixed, and all evaluations must be completed continuously within the same evaluation period. (2) During the evaluation process, the paper ensure randomness in both the selection of model audio pairs and the ordering of evaluation positions, and the paper additionally require evaluators to provide reasons for their preference judgments. (3) the paper perform periodic spot checks during the evaluation process and intervene promptly when significant deviations are observed to maintain inter-rater consistency. After the full evaluation is completed, the paper further review cases with large discrepancies across evaluators and conduct additional verification to ensure the reliability of the final results.
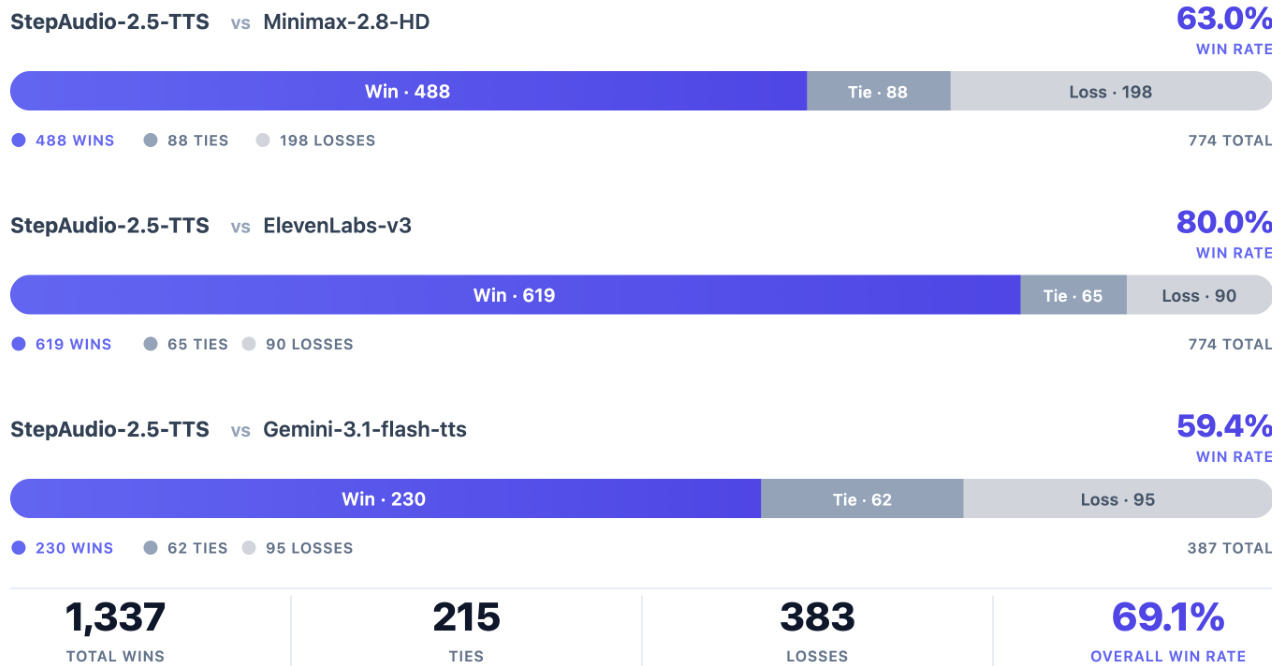
the figure: Arena Win Rates of StepAudio-2.5-TTS.
Finally, the paper select three leading models with controllable generation capabilities—MiniMax-2.8-HD, Elevenlabs-v3, and Gemini-3.1-Flash-TTS. For each model, the paper adopt its officially recommended optimal voice preset and conduct arena-based evaluation using 774 prompts.
The results in the figure show that StepAudio-2.5-TTS achieves 67.6% overall win rate in pairwise evaluations against three strong TTS baselines, with consistent gains across all comparisons.
- 6.3 Evaluation
Because realtime interaction quality depends on properties that transcript-level metrics do not capture, the paper evaluate StepAudio 2.5 Realtime in a fully interactive setting that combines subjective human evaluation conducted through mobile-app sessions with objective API-based evaluation across general dialogue, in-car dialogue, dialogue understanding, and audio-question answering The five suites are:
-
Step-Dialogue-Human-Eval: Subjective mobile-app evaluation for general dialogue scenarios.
-
step_Dialogue_general: Objective API evaluation for general dialogue.
-
step-Dialogue-car: Objective API evaluation for in-car dialogue scenarios.
-
Step-Dialogue-Understanding: 87 diverse audio samples testing the model's ability to infer speaker acoustic features (e.g., age, gender, speech rate) directly from the audio signal.
-
Step-SPQA: An 11-category audio-question/audio-answer benchmark introduced in Step-Audio 2.
the figure: Realtime interaction evaluation. Higher is better. Best results are in bold
Results Analysis: As shown in the figure, StepAudio 2.5 Realtime consistently outperforms competitive baselines across all five suites. Notably, it achieves a +10.0 margin on the subjective human evaluation compared to the next-best system, validating the efficacy of the persona and naturalness conditioning. Furthermore, the +16.6 margin on Step-SPQA and strong performance on Step-Dialogue-Understanding indicate that the paralinguistic conditioning enhances acoustic comprehension without degrading general reasoning. The concurrent improvements in both subjective conversational quality and objective audio understanding demonstrate that the rehearsal schedule effectively balances specialized interaction training with foundational capabilities.
The authors evaluate StepAudio-2.5-TTS using an arena-style pairwise comparison framework against three leading TTS models. The results show that StepAudio-2.5-TTS achieves a high overall win rate, demonstrating strong performance in subjective quality and consistent advantages across individual comparisons. The model's superior performance is attributed to effective persona and naturalness conditioning. StepAudio-2.5-TTS achieves a high overall win rate in pairwise evaluations against strong TTS baselines. The model shows consistent performance gains across all individual comparisons with different baselines. StepAudio-2.5-TTS outperforms competitors in subjective quality and maintains strong performance in objective evaluations.
The authors evaluate the inference efficiency of StepAudio 2.5 ASR against several baselines, measuring real-time factor (RTF) under a standardized serving setup. Results show that StepAudio 2.5 ASR achieves a significantly lower RTF compared to all other models, indicating superior decoding speed and efficiency. StepAudio 2.5 ASR demonstrates the lowest real-time factor among all compared models, indicating faster inference. The model achieves substantially better decoding efficiency than VibeVoice-ASR, FunASR-Nano, Doubao-ASR-2603, and Qwen3-ASR-1.7B. Despite using a larger decoder, StepAudio 2.5 ASR maintains an exceptionally low RTF, highlighting the effectiveness of its training and decoding strategy.

The authors analyze the performance of different MTP configurations on a speech recognition task, focusing on acceptance rates at various positions and the average length of accepted transcripts. Results show that increasing the number of branches improves average accepted length, but with diminishing returns beyond a certain point. The model achieves high acceptance rates for early positions regardless of the configuration, while later positions show a consistent decay in acceptance. The optimal configuration balances efficiency and complexity by maximizing accepted length without excessive computational overhead. Increasing the number of branches improves average accepted transcript length but with diminishing returns beyond MTP-5. Acceptance rates for early positions remain stable across configurations, indicating consistent prediction quality. Later positions show a consistent decay in acceptance, driven by higher failure rates that disrupt the decoding stream.

The authors evaluate StepAudio 2.5 ASR against several baselines on multiple language and long-form transcription benchmarks. Results show that the model achieves the best performance across Chinese, English, and long-form tasks, with significant improvements over competitive models, particularly on Chinese and long-form benchmarks. The model also demonstrates strong decoding efficiency, achieving a very low real-time factor while using a larger decoder, attributed to its MTP training approach. StepAudio 2.5 ASR achieves the best performance on Chinese and English benchmarks, with notable improvements on key datasets like AISHELL-1 and LibriSpeech. The model shows superior long-form transcription accuracy, outperforming other models by a significant margin on average error rates. StepAudio 2.5 ASR achieves exceptional decoding efficiency, with a very low real-time factor despite using a larger decoder, indicating effective MTP training.
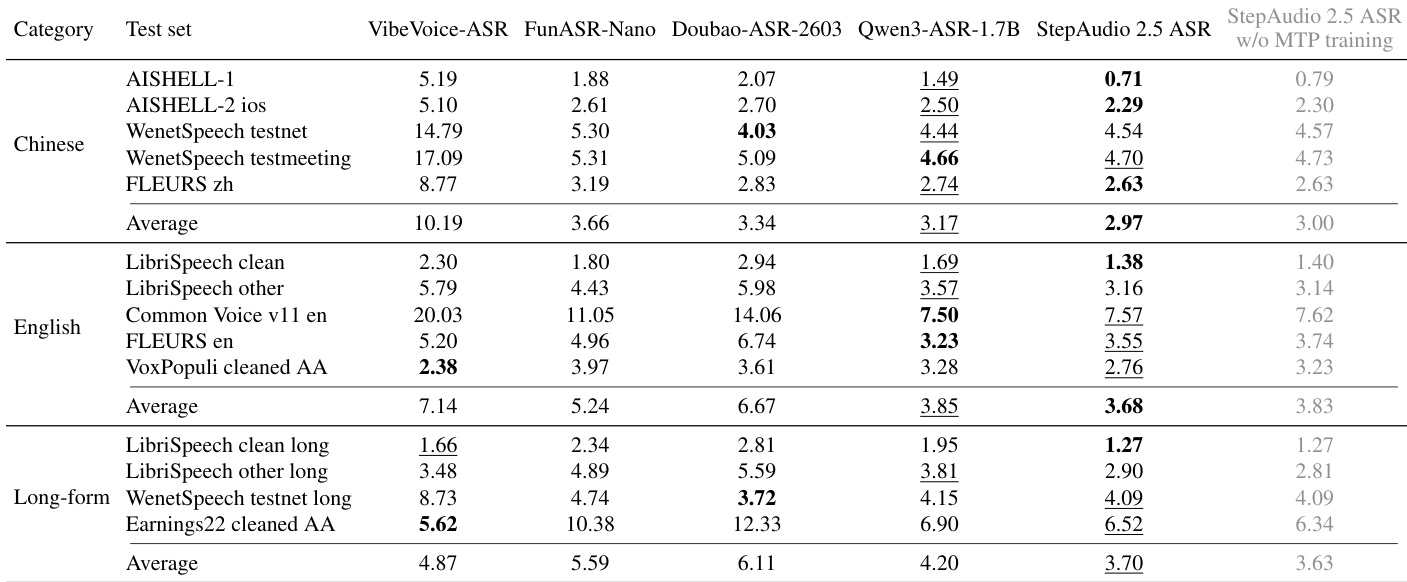
The evaluation framework employs pairwise subjective comparisons to validate the TTS model's quality, alongside real-time factor measurements and cross-lingual benchmark testing to assess the ASR variant's efficiency and accuracy. Results indicate that the TTS system delivers consistently superior subjective quality and reliable performance gains, largely driven by effective persona and naturalness conditioning. For the ASR component, experiments demonstrate exceptional decoding speed and robust transcription accuracy across multiple languages and long-form tasks, while configuration analysis reveals that optimizing multi-token prediction branches requires balancing increased transcript coverage against computational overhead and position-dependent acceptance decay. Ultimately, both models establish a strong balance between high-fidelity generation and rapid inference through targeted architectural and training strategies.