Command Palette
Search for a command to run...
إعادة التفكير في توجيه المعلومات عبر الطبقات في محولات الانتشار
إعادة التفكير في توجيه المعلومات عبر الطبقات في محولات الانتشار
الملخص
لم تعد محولات الانتشار (DiTs) مجرد خيار، بل أصبحت العمود الفقري المعتمد فعلياً في التوليد البصري الحديث، وقد خضعت كل محور رئيسي في تصميمها – الترميز، الانتباه، التهيئة، الأهداف، والمشفرات التلقائية الكامنة – لإعادة نظر مكثفة. ومع ذلك، فقد تم توريث المسار المتبقي (residual stream) الذي يحكم كيفية تراكم المعلومات عبر الطبقات مباشرة من المحول الأصلي. في هذه الورقة، نقدم تحليلاً تجريبياً منهجياً لتدفق المعلومات عبر الطبقات في محولات الانتشار، وذلك بشكل مشترك على عمق الشبكة وزمن إزالة الضوضاء، ونحدد ثلاثة أعراض ملموسة للجمع المتبقي التقليدي، وهي التضخم الأحادي الاتجاه في المقدار الأمامي، والتدهور الحاد في تدرج التراجع الخلفي، والازدواجية الواضحة على مستوى الكتلة. وتحفيزاً من هذا التشخيص، نقترح التوجيه التكيفي للانتشار (DAR)، وهو بديل مباشر للجمع المتبقي يقوم بتجميع قابل للتعلم، ومتكيف مع زمن إزالة الضوضاء، وغير تراكمي، لمخرجات الطبقات الفرعية التاريخية. علاوة على ذلك، فإن الـ DAR المقترح متوافق مع العديد من طرق تحسين المحولات الحديثة، مثل REPA. وعلى مجموعة بيانات ImageNet بدقة 256×256، يحسن الـ DAR نموذج SiT-XL/2 بمقدار 2.11 في مؤشر FID (7.56 مقابل 9.67)، ويحقق جودة مساوية للجودة المتقاربة للنموذج الأساسي مع عدد أقل من تكرارات التدريب بمقدار 8.75 مرة. وعند تكديسه فوق REPA، يحقق تسريعاً في التدريب بمقدار 2 مرة في المرحلة المبكرة، مما يشير إلى أن توجيه المعلومات عبر الطبقات يمثل محور تصميم غير مستكشف بشكل كافٍ في نمذجة الانتشار، وهو يعمل بشكل متعامد مع أهداف محاذاة التمثيل الحالية. وبالإضافة إلى مرحلة التدريب المسبق، يمكن أيضاً تطبيق الـ DAR خلال مرحلة الضبط الدقيق لنماذج التوليد من النص إلى الصورة (T2I) واسعة النطاق، ويحافظ على التفاصيل عالية التردد أثناء التقريب المطابق للتوزيع (Distribution Matching Distillation).
One-sentence Summary
To address sharp backward gradient decay and pronounced block-wise redundancy in Diffusion Transformers, the authors propose Diffusion-Adaptive Routing (DAR), a drop-in residual replacement that performs learnable, timestep-adaptive, and non-incremental aggregation across sublayer outputs, improving SiT-XL/2 by 2.11 FID (7.56 vs. 9.67) on ImageNet 256×256 while matching baseline quality with 8.75× fewer training iterations.
Key Contributions
- This study presents a systematic empirical analysis of cross-layer information flow in Diffusion Transformers across depth and denoising timesteps, diagnosing three failure modes of standard residual addition including monotonic forward magnitude inflation, sharp backward gradient decay, and pronounced block-wise redundancy.
- The work introduces Diffusion-Adaptive Routing (DAR), a drop-in residual replacement that executes learnable, timestep-adaptive, and non-incremental aggregation over historical sublayer outputs while remaining compatible with modern Transformer enhancements such as REPA.
- Evaluations on the ImageNet 256x256 dataset demonstrate that DAR improves the SiT-XL/2 baseline by 2.11 FID points and achieves equivalent convergence quality using 8.75 times fewer training iterations.
Introduction
Diffusion Transformers have rapidly become the standard for visual generation by replacing convolutional U-Nets with token-based denoisers, but effectively capturing the time-varying dynamics of the denoising process remains a critical challenge. Most existing architectures inherit a fixed, time-agnostic residual stream from language models, which causes hidden states to inflate, backward gradients to decay, and adjacent layers to grow redundant as depth increases. This static routing mechanism also fails to adapt to the denoising timeline, where optimal feature extraction must shift from coarse structures in high-noise regimes to fine details in low-noise regimes. The authors tackle these limitations by conducting the first systematic analysis of cross-layer information flow across both network depth and denoising timesteps. They introduce DAR, a drop-in residual replacement that replaces uniform aggregation with learnable, timestep-adaptive routing. This approach significantly accelerates training convergence, improves generation quality, and integrates seamlessly with modern representation-alignment objectives.
Method
The authors propose Diffusion-Adaptive Routing (DAR), a novel residual replacement mechanism designed to address the limitations of standard residual accumulation in Diffusion Transformers (DiTs). The core idea is to replace the fixed, incremental sum of sublayer outputs with a learnable, timestep-adaptive aggregation that dynamically weights contributions from previous sublayer outputs. This approach treats cross-layer information routing as a fundamental design dimension, moving beyond the fixed residual pattern inherited from the original Transformer.
The standard residual routing in DiTs is defined by the recurrence hl+1=hl+fl(hl;t), where hl is the hidden state at layer l, fl is the transformation (attention or MLP), and t is the denoising timestep. Unrolling this recurrence reveals that the output hl is a simple sum of the initial input and all preceding sublayer outputs: hl=h0+∑i=0l−1fi(hi;t). This method is inherently limited because it applies unit weights to all past representations, preventing the model from selectively retrieving or suppressing specific features based on the current depth or denoising stage. This fixed routing pattern is also distinct from U-Net-like skip connections, which manually pair deep and shallow layers for feature fusion but lack the scalability and homogeneity of a pure Transformer architecture.
DAR fundamentally rethinks this accumulation process. It replaces the unweighted sum with a softmax-weighted aggregation over the history of sublayer outputs. Let vi=fi(hi;t) denote the output of the i-th sublayer, with v0=h0. The aggregated hidden state hl at layer l is computed as:
hl=i=0∑l−1αi→l(t)viwithαi→l(t)=∑j=0l−1exp(ql(t)⊤kj/d)exp(ql(t)⊤ki/d),where ki=RMSNorm(vi) is the key for source vi, and the softmax is computed over the set Sl={v0,v1,…,vl−1}. This mechanism allows the model to learn which past representations are most relevant for the current sublayer, enabling non-incremental and adaptive information retrieval.
The query ql(t), which determines the routing weights, is parameterized in three ways to incorporate timestep awareness. The pure static variant uses a learnable, time-independent vector wl. The dynamic variant computes the query from the most recent sublayer output: ql(t)=Wq(l)vl−1, which implicitly injects the timestep information contained in vl−1. The explicit variant augments the static query with the timestep embedding e(t): ql(t)=wl+e(t), providing a direct, explicit signal. The authors find that both dynamic and explicit variants, which are aware of the denoising timestep, significantly outperform the static variant, highlighting the importance of timestep awareness for effective routing.
To manage the computational cost of retaining all L sublayer outputs, DAR implements a chunked aggregation strategy. The network is divided into N chunks of size S=L/N. Each chunk n is summarized by cn=vnS, the output of its final sublayer. For a sublayer l in chunk n, the source set for aggregation becomes:
Sl={c0,c1,…,cn−1}∪{v(n−1)S+1,⋯,vl−1},consisting of summaries from previous chunks and the raw outputs from the current chunk. This reduces the source memory footprint from O(Ld) to O((S+N)d). The optimal chunk size S∗ is derived to be S∗=L⋅1+α1−α, where α is a hyperparameter controlling the routing-entropy term. Empirical analysis confirms that a chunk size of S=4 is optimal for the SiT-XL/2 model.
The final aggregation for the prediction layer is further refined. A dedicated final aggregator is used, which has access to all raw sublayer outputs of the last chunk in addition to the summaries of all prior chunks. This design choice is motivated by the intuition that the most recent outputs contain the most task-specific signal, and preserving them in their raw form allows the final layer to recover fine-grained information that would be lost in a single summary. When combining DAR with REPA, the final aggregation reuses the parameters of the last chunk's MLP aggregator, an empirically motivated design that improves performance.
Experiment
Evaluated on ImageNet using standard diffusion training protocols, the experiments validate that conventional residual routing in DiTs suffers from magnitude inflation, gradient imbalance, and representational redundancy while naturally exhibiting timestep-dependent source preferences. By introducing learned, timestep-adaptive cross-layer aggregation, the proposed method accelerates convergence and improves generation quality beyond what can be achieved through parameter scaling or fixed skip connections. Further ablations confirm that this routing mechanism complements representation alignment techniques, performs optimally at intermediate chunk sizes, and effectively preserves fine visual details during large-scale model distillation. Ultimately, the findings demonstrate that adaptive cross-layer information flow resolves inherent architectural rigidity without compromising the homogeneous Transformer structure.
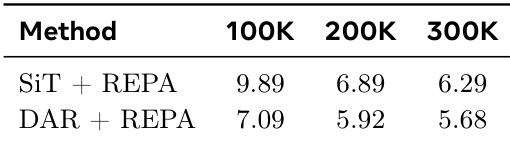
The authors compare the performance of SiT and DAR models combined with REPA, focusing on convergence speed and final quality. Results show that DAR combined with REPA achieves lower FID scores than SiT combined with REPA across all training iterations, indicating improved performance and faster convergence. The gains are consistent even when accounting for model size and alternative architectural designs. DAR combined with REPA outperforms SiT combined with REPA in FID across all training iterations. DAR with REPA achieves lower FID scores with fewer training iterations compared to SiT with REPA. The improvement of DAR with REPA is not due to increased model size or alternative architectural choices.
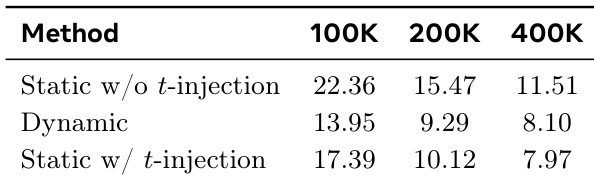
The authors analyze the performance of different variants of the DAR method in terms of convergence speed and final quality, comparing models with and without timestep injection. Results show that the dynamic variant achieves the lowest metric values at all training stages, indicating superior performance, while the static variant without timestep injection consistently underperforms. The inclusion of timestep injection improves results across both static and dynamic configurations. The dynamic variant achieves the best performance across all training stages. The static variant without timestep injection performs worse than both dynamic and static with timestep injection. Timestep injection improves performance for both static and dynamic variants.
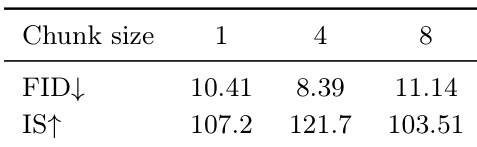
The experiment evaluates the impact of different chunk sizes on model performance, measuring quality through FID and IS. Results show that a chunk size of 4 achieves the best FID, while the highest IS is observed at a chunk size of 4, indicating a trade-off between these metrics across different configurations. A chunk size of 4 yields the best FID performance compared to chunk sizes of 1 and 8. The highest IS is achieved with a chunk size of 4, suggesting optimal representational quality at this setting. Performance varies with chunk size, showing a U-shaped trend where intermediate values outperform extremes.
The authors compare their proposed method, DAR, against standard residual and U-Net-like routing baselines on image generation tasks, using metrics such as FID and Inception Score. Results show that DAR achieves superior performance with fewer training iterations and parameters, and its effectiveness is further enhanced when combined with REPA. The method demonstrates strong convergence and quality improvements across different configurations, particularly in the dynamic variant with guidance. DAR achieves better performance than standard residuals and U-Net-like routing with fewer training iterations and parameters. The dynamic variant of DAR outperforms baselines in both quality and convergence speed, especially under classifier-free guidance. Combining DAR with REPA leads to significant improvements, indicating orthogonal and compounding benefits.
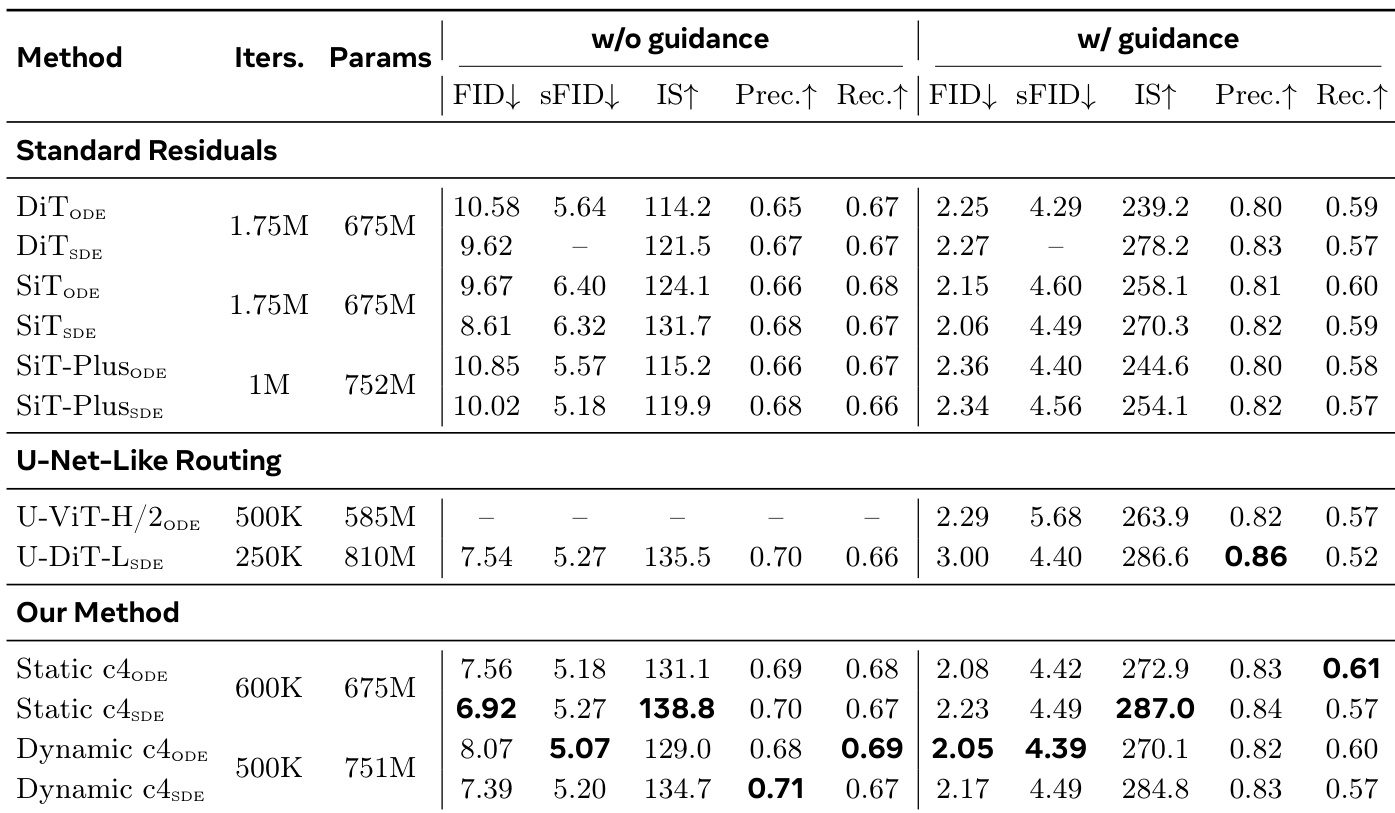
The evaluation compares the proposed DAR method against SiT and standard routing baselines to validate convergence speed, generation quality, and parameter efficiency. Component ablations further verify that dynamic routing and timestep injection consistently enhance performance, while intermediate chunk sizes optimally balance quality metrics. Collectively, the experiments demonstrate that DAR delivers superior generation quality and faster convergence with fewer parameters, achieving compounding improvements when integrated with REPA.