Command Palette
Search for a command to run...
نمذجة الموارد البشرية للنصوص: تدريب مسبق فعّال يتجاوز حدود التوسعة
نمذجة الموارد البشرية للنصوص: تدريب مسبق فعّال يتجاوز حدود التوسعة
Guan Wang Changling Liu Chenyu Wang Cai Zhou Yuhao Sun Yifei Wu Shuai Zhen Luca Scimeca Yasin Abbasi Yadkori
الملخص
تعتمد نماذج اللغة الكبيرة (LLMs) الحالية في مرحلة التدريب المسبق على قدرات حوسبية هائلة وكميات ضخمة من النصوص الخام المتاحة عبر الإنترنت، مما يخلق حاجزاً كبيراً أمام البحوث الأساسية. وفي المقابل، تُظهر النظم البيولوجية قدرة عالية على التعلم بكفاءة عالية في استهلاك العينات من خلال معالجة متعددة المقاييس الزمنية، مثل التنظيم الوظيفي لحلقة الفص الجبهي الصدغي (frontoparietal loop). مستوحاةً من هذه الآليات، نقدم نموذج HRM-Text، الذي يحل محل معماريات Transformer القياسية بنموذج تكراري هرمي (Hierarchical Recurrent Model - HRM) يفكك الحساب إلى طبقتين: طبقة استراتيجية تتطور ببطء، وطبقة تنفيذية تتطور بسرعة. ولتثبيت هذا التكرار العميق في نمذجة اللغة، نقدم تقنية "MagicNorm" وأسلوب "المسند العميق للتدفق الحراري التدريجي" (warmup deep credit assignment). علاوة على ذلك، وبدلاً من الاعتماد على التدريب المسبق بالنصوص الخام القياسية، يتم تدريب النموذج حصرياً على أزواج التوجيه والاستجابة (instruction-response pairs) باستخدام هدف إكمال المهمة وقناع PrefixLM. ويُمثل هذا النموذج دليلاً تجريبياً على وجود بديل فعال للتدريب المسبق، حيث حقق نموذج HRM-Text ذو البليون معلمة (1B-parameter)، الذي تم تدريبه من الصفر على 40 مليار رمز فريد (token) فقط وبميزانية قدرها 1,500 دولار، نتائج بلغت 60.7% على مجموعة MMLU، و81.9% على ARC-C، و82.2% على DROP، و84.5% على GSM8K، و56.2% على MATH. وعلى الرغم من استخدامه لعدد أقل من رموز التدريب بمقدار 100-900 مرة وقدرات حوسبية أقل تقديراً بمقدار 96-432 مرة مقارنة بأساليب الأساس القياسية، فإن HRM-Text يتنافس competitively مع النماذج المفتوحة ذات البليونين إلى سبعة مليارات معلمة.
One-sentence Summary
HRM-Text replaces standard Transformers with a Hierarchical Recurrent Model that decouples computation into slow-evolving strategic and fast-evolving execution layers stabilized by MagicNorm and warmup deep credit assignment, utilizing exclusively instruction-response pairs with a task-completion objective and PrefixLM masking to enable a 1B-parameter model trained from scratch on 40 billion unique tokens and a $1,500 budget to achieve 60.7% on MMLU, 81.9% on ARC-C, 82.2% on DROP, 84.5% on GSM8K, and 56.2% on MATH while performing competitively with 2-7B parameter open models despite employing roughly 100-900x fewer training tokens and 96-432x less estimated compute.
Key Contributions
- HRM-Text replaces standard Transformers with a Hierarchical Recurrent Model that decouples computation into slow-evolving strategic and fast-evolving execution layers.
- The method stabilizes deep recurrence using MagicNorm and warmup deep credit assignment, while training exclusively on instruction-response pairs via a task-completion objective and PrefixLM masking.
- A 1B-parameter HRM-Text model trained from scratch on 40 billion unique tokens achieves competitive performance on benchmarks including MMLU and GSM8K with roughly 100 to 900 times fewer training tokens and 96 to 432 times less compute than standard baselines.
Introduction
Current large language model pretraining relies on massive compute and internet-scale raw text, creating a barrier that limits foundational research to resource-rich institutions. This brute-force scaling paradigm is inefficient in data-limited regimes, and prior recurrent architectures often suffer from severe gradient instability. To overcome these challenges, the authors introduce HRM-Text, which replaces standard Transformers with a Hierarchical Recurrent Model inspired by biological multi-timescale processing. They stabilize deep recurrence through techniques like MagicNorm and warmup deep credit assignment while training exclusively on instruction-response pairs using a task-completion objective. This co-design enables a 1B-parameter model to achieve competitive performance with 2 to 7B baselines using up to 900 times fewer training tokens and significantly less compute.
Dataset

- The authors train HRM-Text on open-source datasets including general instructions, rewritten knowledge, mathematical tasks, textbook exercises, and web-extracted questions. The initial corpus holds 176.5B tokens across 593.7M documents.
- They sample 40B unique tokens for a total training duration of 60B tokens. Stratified sampling treats each dataset as an independent stratum with caps on document counts to prevent over-representation of massive sources.
- Specific sampling limits and multipliers ensure a balanced training mixture while smaller datasets are upsampled according to the stratified schedule.
- The authors prepend condition tags for direct, chain-of-thought, synthetic, and noisy styles to control output format. Text within ... boundaries is stripped to eliminate explicit reasoning traces.
Method
The HRM-Text model is built upon an improved HRM architecture featuring a dual-timescale recurrence. The forward pass is initialized with a high-level state zH0 derived from input token embeddings, alongside a fixed low-level state zL0. The core processing sequence consists of two high-level cycles. Each cycle executes three fast L module updates followed by a single slow H module update. Token logits are generated by applying a linear head to the output of the final H module state.
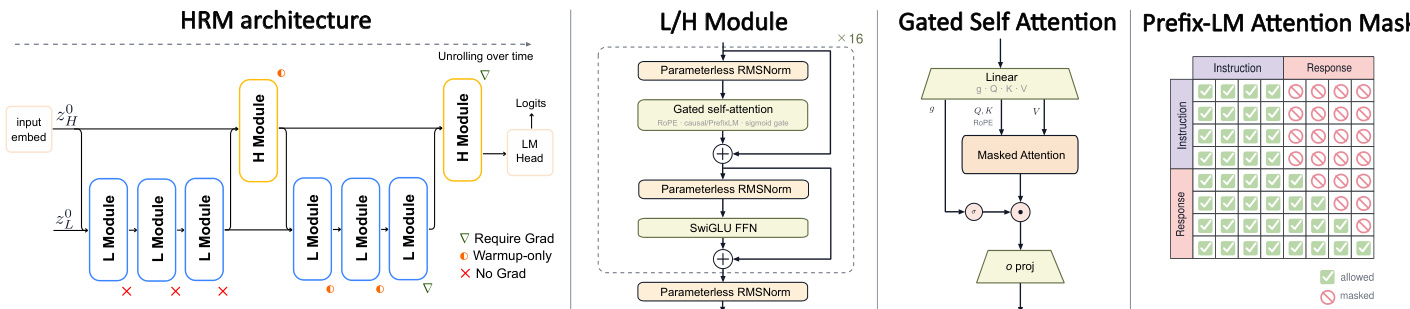
Internally, both the H and L recurrent modules are structured using MagicNorm to address gradient instability. This design exploits the asymmetry between the forward and backward computational horizons induced by truncated backpropagation through time. Each recurrent module is composed of L internal PreNorm blocks but is capped with a final normalization layer at its exit. During the forward pass, the recurrent state z is subjected to module-level normalization operations at the end of every recurrent step, bounding activation variance. Conversely, during the backward pass, the truncated gradient horizon means the error signal passes through the module-level normalization fewer times than the internal PreNorm identity connections. Additionally, the modules utilize parameterless RMSNorm, SwiGLU activation functions, Rotary Position Embeddings, and a sigmoid-gated self-attention mechanism. This attention mechanism employs linear projections for query, key, and value vectors, followed by a masked attention block where a sigmoid gate modulates the output before the final projection.
The model optimizes a task-completion objective rather than standard autoregressive pretraining on raw text. It is pretrained directly on instruction-response pairs from scratch using a negative log-likelihood loss computed exclusively over the response. This objective is naturally paired with a PrefixLM attention mask, enabling full bidirectional attention across the instruction tokens while maintaining standard causal masking over the response sequence. To ensure stability during optimization, the authors employ a warmup deep credit assignment strategy. Gradients are initially backpropagated through only the final two recurrent steps, expanding to the final five steps as training progresses. This progressive deepening allows the model to exploit longer recurrent computation while reducing exposure to optimization pathologies at initialization.
Experiment
The experiments evaluate the HRM architecture against standard and recurrent baselines under matched training compute to validate architectural efficiency and the impact of specific training objectives. Results demonstrate that recurrent designs coupled with task-completion objectives significantly improve benchmark yield, allowing HRM to compete with much larger models using substantially less training compute. Qualitative analysis confirms these gains stem from greater effective depth and stable gradient dynamics rather than data contamination or training instability.
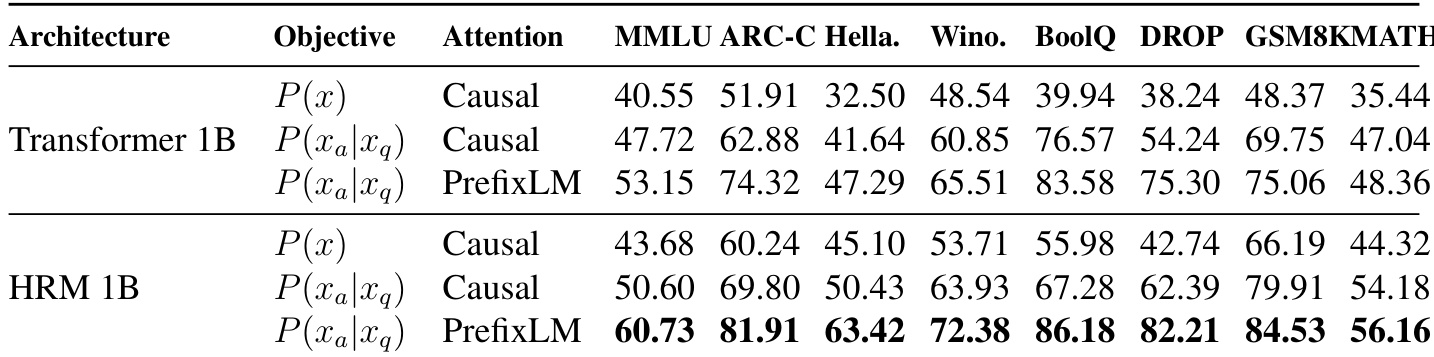
The authors investigate how training objectives and attention mechanisms affect model performance by comparing standard Transformers with HRM. The data indicates that shifting to a task-completion objective and utilizing PrefixLM attention consistently improves results for both architectures. Additionally, the HRM architecture demonstrates superior capabilities compared to the standard Transformer, achieving peak performance when combined with the task-completion objective and PrefixLM attention. HRM 1B consistently outperforms the Transformer 1B baseline across all tested configurations. The task-completion objective yields significant performance gains over the standard objective for both model types. Switching to PrefixLM attention further enhances results, producing the highest scores when paired with the HRM architecture.
The authors compare the proposed HRM architecture against a variant called TRM across different parameter scales to evaluate stability and compute efficiency. Results indicate that HRM maintains stable training dynamics at the larger scale where TRM becomes unstable and underperforms, while at the smaller scale, HRM achieves competitive benchmark performance with substantially lower computational cost. HRM maintains stable training dynamics across all scales, whereas the TRM variant suffers from severe instability at the larger parameter scale. At the smaller scale, HRM achieves competitive performance across most benchmarks while requiring substantially less compute than TRM. HRM demonstrates consistent performance gains over the unstable TRM variant at the larger parameter scale.

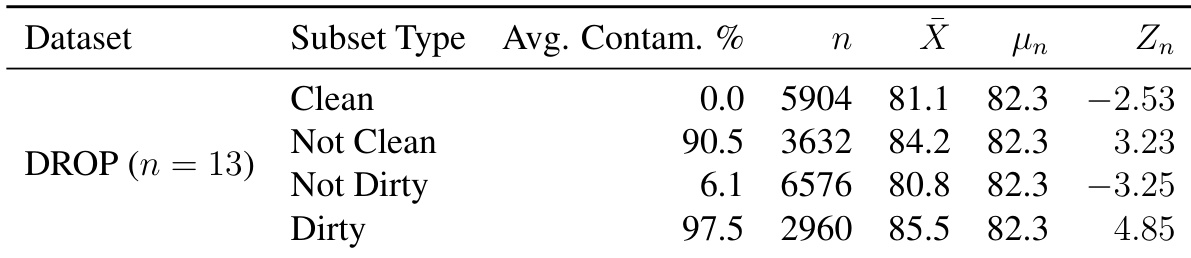
The the the table presents a statistical analysis of dataset contamination on the DROP benchmark, categorizing samples into subsets based on their contamination levels. Results indicate that subsets with higher contamination percentages tend to achieve higher average performance scores compared to those with lower contamination. Despite these trends, the model demonstrates robust performance on the strictly clean subset, suggesting its capabilities are not solely driven by data overlap. The subset with the highest contamination levels achieves the highest average performance. Statistical test values are positive for contaminated groups and negative for cleaner groups. Strong performance is maintained on the subset with no detected contamination.
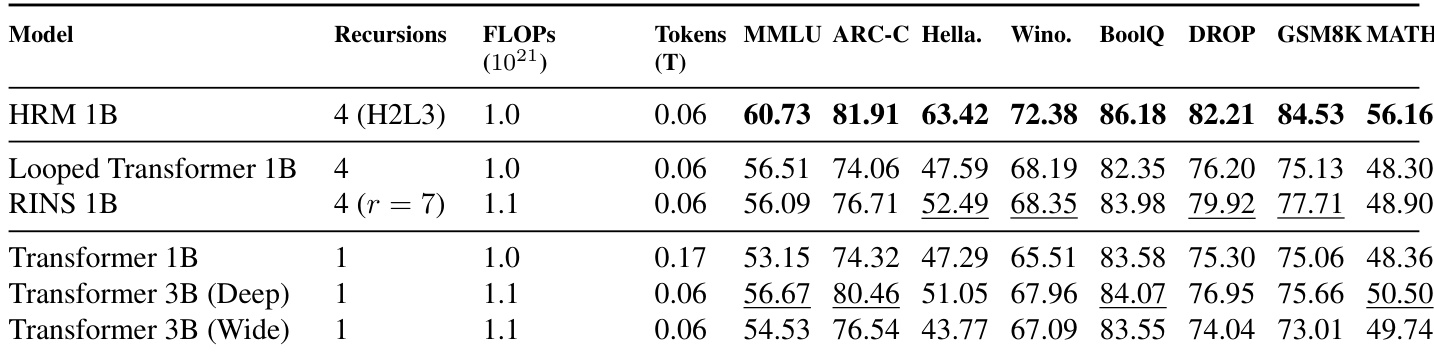
The authors evaluate architecture efficiency by comparing HRM against standard Transformers, Looped Transformers, and RINS under matched training compute budgets. Results indicate that HRM achieves superior performance across most benchmarks compared to both standard and other recurrent architectures with similar computational costs. Notably, the HRM model outperforms larger standard Transformer models and other recurrent baselines. HRM achieves the highest scores across nearly all evaluated benchmarks compared to the baselines. Recurrent architectures generally outperform standard Transformers of the same parameter size, with HRM showing the strongest gains. The proposed model maintains a performance advantage even when compared against larger standard Transformer models with matched FLOPs.
The authors investigate an inference-time auto-guidance mechanism that interpolates or extrapolates logits from various recursion depths to improve model performance. Results show that applying this guidance consistently yields slight performance gains across all evaluated benchmarks compared to standard inference. The optimal guidance parameter varies depending on the specific task, indicating that different problems benefit from different effective recurrent depths. Guidance consistently improves scores across MMLU, ARC-C, and other benchmarks. The method leverages intermediate hidden states without incurring additional computation overhead. Optimal guidance weights differ per task, ranging from interpolation to extrapolation.

The study evaluates the HRM architecture against standard Transformers and recurrent baselines by varying training objectives, attention mechanisms, and parameter scales. Results indicate that HRM ensures stable training dynamics and superior performance, particularly when combined with task-completion objectives and PrefixLM attention. Furthermore, the model demonstrates robustness against data contamination and maintains efficiency advantages over larger baselines, while an inference-time auto-guidance mechanism improves accuracy without additional overhead.