Command Palette
Search for a command to run...
LongLive-2.0: بنية متوازية NVFP4 لتوليد الفيديو الطويل
LongLive-2.0: بنية متوازية NVFP4 لتوليد الفيديو الطويل
الملخص
نقدم LongLive-2.0، وهي بنية متوازية تعتمد على NVFP4 تغطي كامل سير عمل التدريب والاستنتاج لتوليد الفيديو الطويل، مما يعالج اختناقات السرعة والذاكرة. بالنسبة للتدريب، نقدم تدريباً ذاتياً متسلسلاً متوازياً (AR)، مُجسّداً في Balanced SP، الذي يصمم بشكل مشترك تخطيط الإكراه المعلمي الفعال مع تنفيذ SP من خلال اقتران مقاطع زمنية نظيرة-تاريخية وأخرى ضجيجية-هدفية على كل رتبة، مما يتيح قناع إكراه معلم طبيعي مع ترميز VAE مقطعي واعٍ لـ SP. وبدمجه مع دقة NVFP4، يقلل من تكلفة ذاكرة وحدات معالجة الرسومات (GPU) ويسرع حسابات GEMM أثناء التدريب، حيث تزداد نسبة هذه الحسابات مع زيادة طول الفيديو. علاوة على ذلك، نوضح أن البنية عالية الجودة ومجموعة البيانات تتيحان خط أنابيب تدريب نظيفاً بشكل ملحوظ. وعلى عكس طرق سلسلة Self-Forcing الحالية التي تعتمد على التهيئة بمعادلات تفاضلية عادية (ODE) وتلخيص مطابقة التوزيع اللاحق (DMD)، يقوم LongLive-2.0 بضبط نموذج الانتشار مباشرةً ليصبح نموذج انتشار ذاتي متسلسل (AR) طويل ومتعدد اللقطات وتفاعلي. يمكن تحويله لاحقاً إلى توليد في الوقت الفعلي (من 4 إلى خطوات إزالة ضجيج 2) باستخدام أوزان LoRA المستقلة. بالنسبة للاستنتاج على وحدات معالجة الرسومات من نوع Blackwell، نُمكّن استنتاج NVFP4 بوزن 4 بت وعامل 4 بت (W4A4)، ونكمّم ذاكرة التخزين المؤقت لـ KV إلى NVFP4 لتوفير الذاكرة، ونعزز الإنتاجية النهائية من خلال فك ترميز VAI المتدفق غير المتزامن. وعلى بنية وحدات معالجة الرسومات غير Blackwell، ننشر استنتاج SP لمطابقة السرعة على وحدات Blackwell، بينما يمكن للذاكرة المؤقتة لـ KV المكمّمة أن تقلل من اتصال SP بين وحدات معالجة الرسومات. تُظهر التجارب تسريعاً يصل إلى 2.15 مرة في التدريب، و1.84 مرة في الاستنتاج. يحقق LongLive-2.0-5B سرعة استنتاج تبلغ 45.7 إطاراً في الثانية مع أداء قوي على معايير التقييم. وإلى علمنا، يُعد LongLive-2.0 أول نظام تدريب واستنتاج NVFP4 لتوليد الفيديو الطويل.
One-sentence Summary
LongLive-2.0 presents an NVFP4-based parallel infrastructure that accelerates long video generation by combining sequence-parallel autoregressive training and W4A4 NVFP4 inference to directly convert diffusion models into interactive autoregressive systems without ODE initialization or distillation, achieving up to 2.15× training and 1.84× inference speedups while enabling the 5B variant to reach 45.7 FPS.
Key Contributions
- The paper introduces Balanced SP, a sequence-parallel autoregressive training framework that co-designs teacher-forcing layouts with parallel execution by pairing clean-history and noisy-target temporal chunks per rank. This architecture enables SP-aware chunked VAE encoding and directly fine-tunes a diffusion model into a multi-shot interactive autoregressive system without relying on ODE initialization or distribution matching distillation.
- The system establishes an end-to-end W4A4 NVFP4 inference pipeline that compresses the KV cache into NVFP4 and integrates asynchronous streaming VAE decoding to maximize throughput on Blackwell GPUs. It extends sequence-parallel inference to non-Blackwell architectures to maintain generation speed while reducing inter-GPU communication overhead.
- Experimental evaluations demonstrate up to 2.15x training acceleration and 1.84x inference speedup, with the LongLive-2.0-5B model achieving 45.7 FPS and strong performance across standard benchmarks. The framework further enables real-time generation by converting the trained model to two to four denoising steps using standalone LoRA adapters.
Introduction
Causal autoregressive synthesis has become the standard for streaming long video generation, offering scalable frame-by-frame creation with real-time potential. Despite advances in mitigating exposure bias and temporal drift, prior methods face persistent bottlenecks in memory management, cache overhead, and a critical mismatch between training precision and deployment efficiency. While low-bit formats like FP4 have successfully compressed large language models, they remain largely untested for video diffusion, where extended spatio-temporal sequences, repeated denoising cycles, and growing key-value caches demand strict precision alignment. The authors leverage a unified NVFP4 quantization framework to resolve these bottlenecks, jointly stabilizing training, enabling weight-and-activation 4-bit inference, compressing key-value cache storage, and streamlining long-video deployment.
Dataset

-
Dataset Composition and Sources
- The authors curate a large-scale long-video dataset from raw footage to train LongLive-2.0.
- The final collection contains 120,000 videos, each segmented into independent shots.
-
Subset Details and Distribution
- The dataset is evenly divided into three duration groups: 16 to 32 seconds, 32 to 64 seconds, and over 64 seconds, with each category representing one-third of the total volume.
-
Filtering and Quality Control
- The authors remove samples exhibiting excessively short shots, logos, watermarks, prominent text, severe camera shake, abnormal playback speeds, exposure issues, blur, and low-motion clips with frozen frames or minimal zoom.
- Visual quality is assessed using the MANIQA metric, where the average score across sampled frames determines the overall rating. Only the highest-ranked videos are retained.
-
Metadata Construction and Processing
- Each shot receives structured captions covering visual elements, scene context, characters, actions, and cinematography.
- The authors merge captions from all shots within a single video and refine the combined text to ensure temporal coherence and logical consistency across consecutive frames and scenes.
-
Model Usage
- The curated dataset serves as the primary training resource for LongLive-2.0, with the authors leveraging the shot-level annotations and temporally aligned long-form descriptions to optimize model performance.
Method
The LongLive-2.0 framework presents a co-designed infrastructure for efficient long video generation, integrating a novel training methodology with a parallel inference system. The core of the training process is sequence-parallel autoregressive (AR) training, instantiated as Balanced SP, which co-designs the data layout with the sequence-parallel execution to address memory and computational bottlenecks. This approach ensures that each GPU rank is responsible for both clean and noisy latent tokens from the same temporal chunk, balancing the loss-bearing workload across devices and enabling a natural teacher-forcing attention mask. This paired layout is applied consistently across VAE encoding, latent construction, and loss computation, eliminating the need for replicated VAE preparation and ensuring that the sequence sharding is aligned with the DiT's attention mechanism. The training process is further accelerated by NVFP4 precision, which reduces memory footprint and speeds up GEMM operations, particularly as video length increases. The authors leverage this infrastructure to directly fine-tune a bidirectional diffusion model into a long, interactive, multi-shot AR model, bypassing the complex multi-stage processes of prior methods. The resulting model can be converted to real-time generation with few-step denoising using standalone LoRA weights, which are derived through a simplified DMD distillation process that optimizes only the LoRA adapters.

For inference, LongLive-2.0 employs a multi-faceted strategy to achieve high throughput and low latency. On Blackwell GPUs, the system enables W4A4 NVFP4 inference, quantizing both the model weights and the key-value (KV) cache to NVFP4, which significantly reduces memory usage and accelerates computation. The KV cache is quantized at the frame-chunk level, with each chunk containing eight frames, and a customized parallel CUDA dequantization kernel is used to reconstruct the cache for efficient in-window attention. To further improve throughput, the framework implements asynchronous streaming VAE decoding. This heterogeneous pipeline dedicates one GPU to VAE decoding, which runs concurrently with the DiT inference cluster, effectively hiding the decoding latency behind the dominant DiT denoising steps. This design reduces end-to-end latency and enables memory-efficient streaming generation. For non-Blackwell GPU architectures, LongLive-2.0 deploys sequence-parallel inference to match the speed of Blackwell GPUs, with the quantized KV cache reducing inter-GPU communication overhead. The system also introduces a multi-shot attention sink mechanism to maintain coherence during multi-shot generation. This mechanism uses two cooperating anchor sets: a global sink to preserve the identity of the entire video and a shot-level sink to maintain local coherence within each shot. This design integrates seamlessly with the chunk-wise interactive prompting interface, allowing for minute-scale interactive generation without redundant recomputation. The overall architecture is designed to maximize end-to-end generation speed, a more practical metric than diffusion-model FPS alone, by minimizing the overhead of low-bit KV computation and overlapping VAE decoding with model denoising.
Experiment
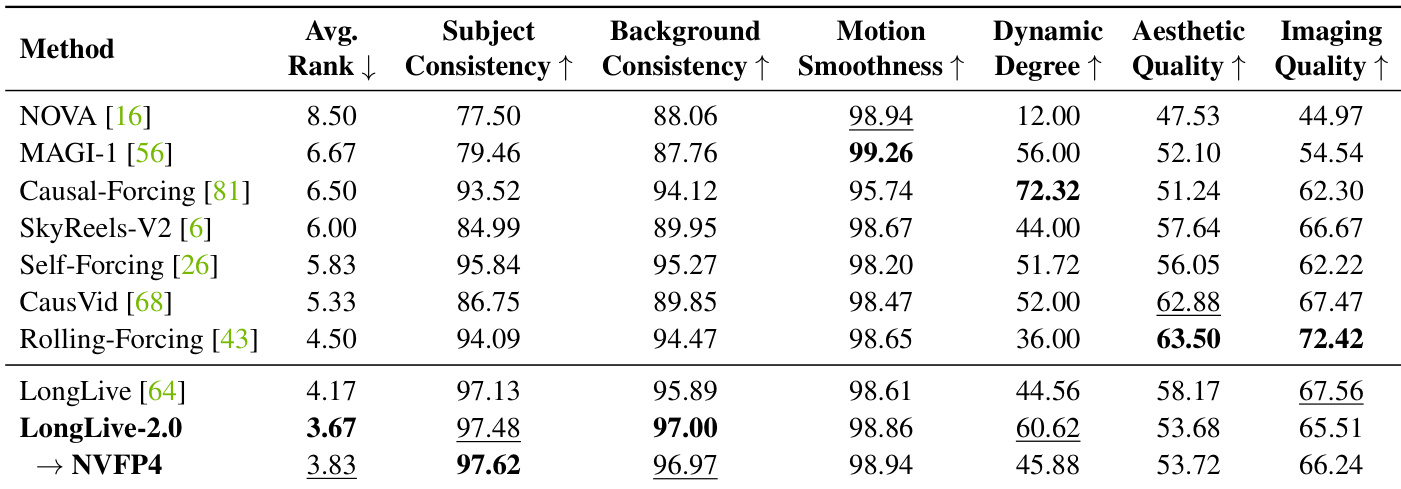
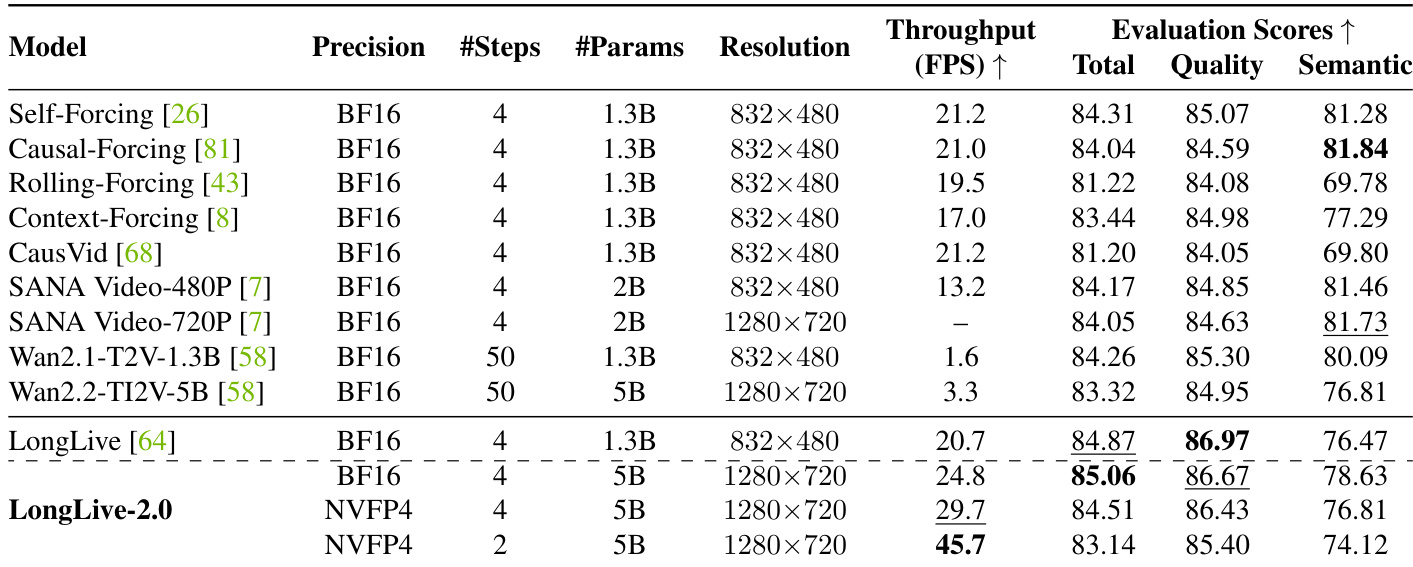
The evaluation setup assesses training and inference efficiency, generation quality across short and long videos, and the impact of key architectural and precision design choices. Experiments validate that combining balanced sequence parallelism with NVFP4 quantization significantly reduces memory usage and accelerates training while preserving visual fidelity. Qualitative ablations further confirm that the multi-shot attention mechanism prevents temporal drift and maintains subject consistency across extended sequences, whereas pre-training the quantized precision avoids the detail degradation associated with post-training conversion. Collectively, these findings demonstrate that the optimized framework enables high-throughput, real-time video generation with robust long-range stability and minimal quality loss.
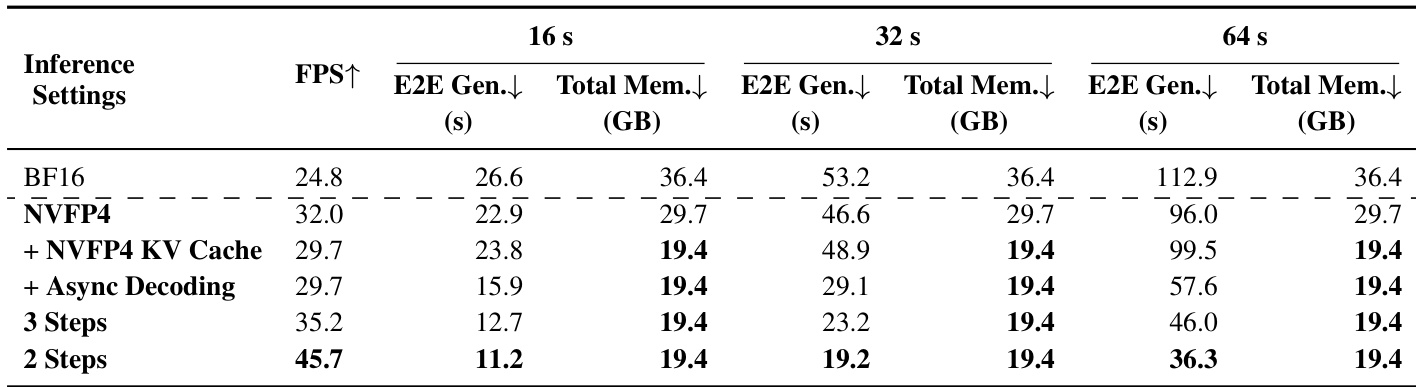
The authors evaluate inference efficiency across different settings, comparing performance metrics such as frames per second, end-to-end generation time, and memory usage across various video lengths. Results show that reducing denoising steps and applying NVFP4 with KV cache and asynchronous decoding improves throughput and reduces latency while maintaining consistent memory footprint. Reducing denoising steps significantly increases inference speed, with the 2-step setting achieving the highest frames per second. NVFP4 with KV cache and asynchronous decoding maintains low memory usage while substantially reducing end-to-end generation time. The 2-step configuration achieves the fastest inference speed and lowest end-to-end latency across all video lengths.
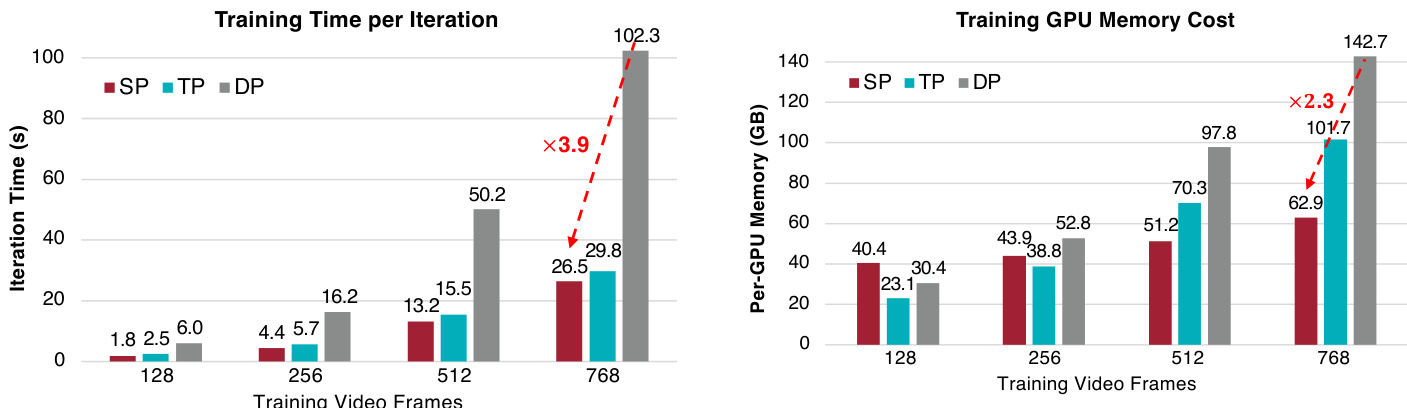
The authors analyze training efficiency by comparing different parallelism strategies and precision settings, showing that sequence parallelism enables longer video training and that combining it with NVFP4 quantization significantly reduces iteration time and memory usage. Results demonstrate that the proposed methods improve scalability and efficiency across various video lengths, with the most significant gains observed at longer sequences. Sequence parallelism enables training on longer videos by reducing memory usage and iteration time compared to baseline methods. Combining NVFP4 quantization with balanced sequence parallelism achieves the fastest training iteration times and lowest memory costs. The proposed approach shows the most significant improvements in efficiency at the longest video lengths, with substantial reductions in both time and memory requirements.
The authors evaluate different precision configurations for video generation models, focusing on memory usage and efficiency. The results show that combining NVFP4 with LoRA reduces peak memory significantly compared to BF16, with the most substantial improvement observed in the final configuration. The ratio of memory reduction indicates a clear efficiency gain when using NVFP4+LoRA over the baseline. NVFP4+LoRA reduces peak memory usage compared to BF16 and NVFP4 configurations. The combination of NVFP4 and LoRA achieves the lowest memory footprint among the tested setups. The memory reduction ratio shows a significant improvement over the baseline configuration.
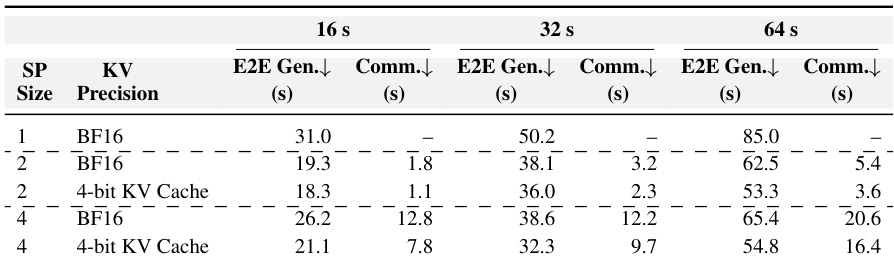
The authors present a series of ablation studies on training and inference efficiency, focusing on sequence parallelism, quantization, and KV-cache compression. Results show that combining these techniques significantly reduces end-to-end generation time and memory usage, particularly for longer sequences, while maintaining or improving performance. The proposed methods enable efficient high-resolution video generation with reduced latency and memory footprint. Combining sequence parallelism with quantization and KV-cache compression reduces end-to-end generation time and memory usage across different sequence lengths. The integration of NVFP4 quantization and KV-cache compression leads to substantial improvements in inference efficiency with minimal latency cost. The proposed methods achieve strong performance in long-video generation, demonstrating superior consistency and quality compared to baselines.
The authors compare different precision configurations for video generation models, focusing on training and inference efficiency. Results show that using NVFP4 with pre-trained quantization maintains high quality while reducing memory usage and improving speed, particularly when combined with fewer denoising steps. NVFP4 with pre-trained quantization achieves high quality and efficiency, matching BF16 performance while reducing memory usage. Fewer denoising steps improve inference speed significantly, enabling real-time video generation. Pre-trained NVFP4 outperforms post-training quantization in preserving visual details and maintaining quality.

The authors evaluate inference and training efficiency across varying video lengths by systematically testing precision configurations, sequence parallelism, and decoding optimizations. These experiments validate that integrating NVFP4 quantization with sequence parallelism, KV-cache compression, and reduced denoising steps substantially accelerates model execution while significantly lowering memory consumption. The combined approaches enable scalable, high-resolution video generation with minimal latency and preserved visual quality, demonstrating consistent advantages particularly for long-sequence tasks.