Command Palette
Search for a command to run...
لانس: نمذجة متعددة الوسائط موحدة من خلال التآزر متعدد المهام
لانس: نمذجة متعددة الوسائط موحدة من خلال التآزر متعدد المهام
الملخص
نقدم لانس (Lance)، وهو نموذج موحد خفيف الوزن وأصلي يدعم الفهم متعدد الوسائط، والتوليد، والتحرير لكل من الصور ومقاطع الفيديو. بدلاً من الاعتماد على توسيع سعة النموذج أو التصاميم التي تهيمن عليها النصوص والصور، يستكشف لانس نموذجاً عملياً للنمذجة المتعددة الوسائط الموحدة من خلال التدريب التعاوني متعدد المهام. يستند هذا النموذج إلى مبدأين أساسيين: نمذجة السياق الموحدة ومسارات القدرات المفككة. على وجه التحديد، تم تدريب لانس من الصفر، ويعتمد على بنية مختلطة من الخبراء ذات تيارين مزدوجين على تسلسلات وسائط متعددة متداخلة مشتركة، مما يتيح التعلم المشترك للسياق مع فصل مسارات الفهم والتوليد. نقدم أيضاً ترميزاً موضعياً دورانياً واعياً بالوسائط لتخفيف التداخل بين الرموز البصرية غير المتجانسة وتعزيز المحاذاة عبر المهام. أثناء التدريب، يتبنى لانس نموذجاً تدريجياً للتدريب متعدد المهام مع أهداف موجهة نحو القدرات وجدولة بيانات تكيفية لتعزيز كل من الفهم الدائي والأداء في التوليد البصري. تظهر النتائج التجريبية أن لانس يتفوق بشكل كبير على النماذج الموحدة مفتوحة المصدر الحالية في توليد الصور ومقاطع الفيديو، مع الاحتفاظ بقدرات قوية على الفهم متعدد الوسائط. يمكن زيارة الصفحة الرئيسية للمشروع على الرابط https://lance-project.github.io.
One-sentence Summary
Lance is a lightweight unified multimodal model that supports image and video understanding, generation, and editing through collaborative multi-task training, employing a dual-stream mixture-of-experts architecture, modality-aware rotary positional encoding, and adaptive staged training to decouple understanding and generation pathways while substantially outperforming existing open-source models in generation and retaining strong multimodal understanding.
Key Contributions
- Lance is introduced as a lightweight native unified model that jointly performs multimodal understanding, generation, and editing for both images and videos.
- The architecture employs a dual-stream mixture-of-experts design on shared interleaved sequences, augmented by modality-aware rotary positional encoding and a staged multi-task training paradigm to decouple capability pathways while enabling joint context learning.
- Empirical evaluations demonstrate that the model substantially outperforms existing open-source unified systems across generation, editing, and understanding benchmarks, achieving these results with only 3B activated parameters and a 128-GPU training budget.
Introduction
Multimodal artificial intelligence is rapidly converging on a native unified paradigm that integrates understanding, reasoning, and generation within a single framework, which is essential for building more general and practically useful foundation models. Prior unified approaches, however, struggle with fundamental representational mismatches between the high-level semantic features required for comprehension and the low-level continuous representations needed for visual synthesis. Additionally, existing systems typically cover only narrow task subsets, often treating complex operations like video editing as separate fine-tuning steps rather than optimizing them alongside core understanding and generation tasks. To address these gaps, the authors leverage multi-task synergy to develop Lance, a lightweight unified model that combines interleaved context modeling with decoupled capability pathways. This architecture allows semantic understanding and visual synthesis to interact effectively while preserving task-specific specialization, delivering strong cross-modal performance with minimal computational overhead.
Dataset

- Dataset Composition and Sources: The authors assemble a large-scale multimodal corpus spanning image-text and video-text pairs, alongside interleaved understanding and generation samples drawn from diverse visual domains and task categories.
- Subset Details: Pre-training includes approximately 1 billion image-text samples covering natural, human, object, knowledge, and stylized content, plus 140 million video-text samples capturing dynamic actions, events, and temporal transitions. Continual training comprises 2.73 million interleaved understanding samples spanning captioning, VQA, OCR, reasoning, grounding, classification, conversation, and text-to-text tasks, combined with 10.6 million generation samples including image and video editing plus subject-driven creation. Supervised fine-tuning utilizes a carefully curated high-quality subset containing 190,000 image captions, 5,000 video captions, 2.73 million understanding samples, and specialized generation, editing, and subject-driven samples for both modalities.
- Training Usage and Mixture Strategy: The pre-training phase freezes the VAE and ViT encoders while optimizing the multimodal backbone, applying a strict image-to-video sampling ratio of 1 to 4 to balance computational difficulty and strengthen temporal reasoning. During continual training, the authors implement a progressive mixture strategy that gradually increases the sampling weight of complex tasks like editing and subject-driven generation while reducing simpler caption-style supervision, totaling approximately 300 billion tokens. The fine-tuning stage applies a reduced learning rate to the curated subset to prioritize instruction fidelity, visual consistency, and generation accuracy over raw scale.
- Processing and Metadata Construction: The pipeline employs a progressive resolution curriculum scaling from 192p to 360p and finally to 480p, with dynamic resolution enabled at each stage to improve scalability. Task-specific system prompts are constructed to explicitly define input-output formats and provide clear task priors, ensuring the model distinguishes between heterogeneous understanding and generation tasks within a unified sequence. High-quality samples are explicitly separated and prioritized during the fine-tuning phase to maintain strict annotation standards and ensure precise instruction alignment.
Method
The authors leverage a dual-stream mixture-of-experts architecture to achieve unified multimodal understanding and generation within a single model, grounded in two core principles: unified context modeling and decoupled capability pathways. Refer to the framework diagram 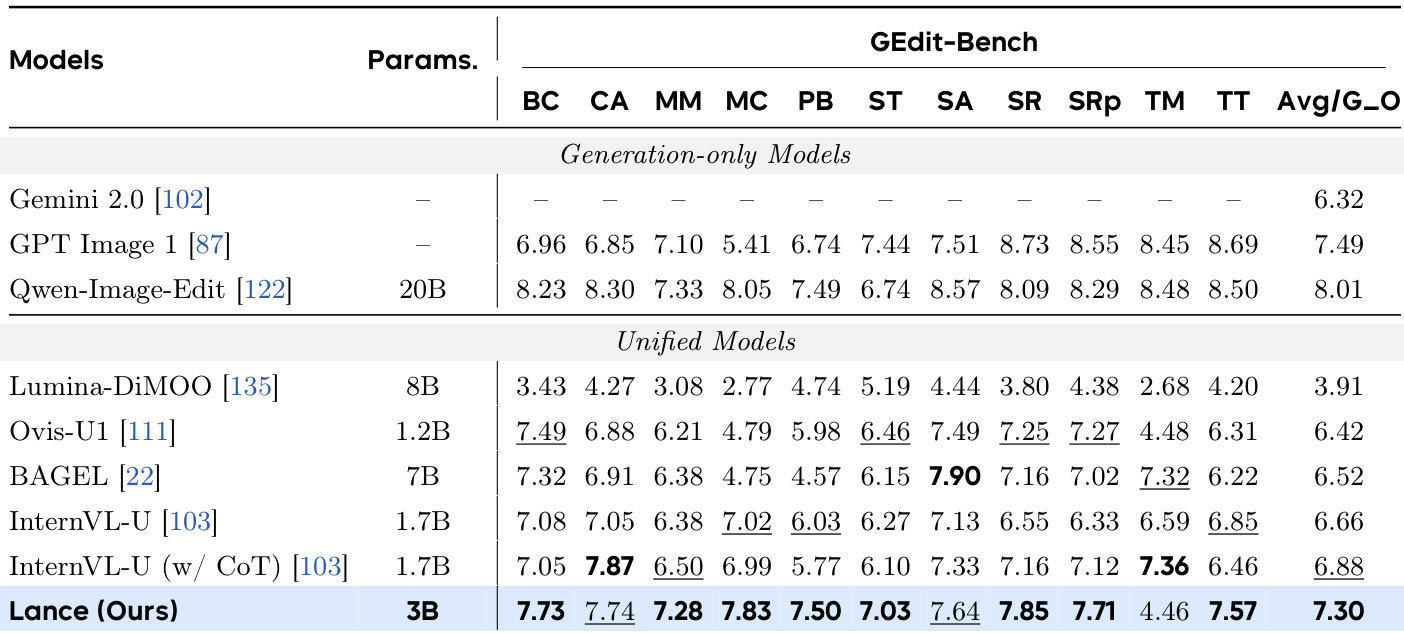 for an overview of the system. The overall framework processes interleaved inputs from text, images, and videos, encoding each modality into task-appropriate token representations. These heterogeneous tokens are then organized into a shared interleaved multimodal sequence using modality-aware rotary positional encoding, enabling unified context learning across diverse task formats. The model employs a dual-expert backbone initialized from Qwen2.5-VL, with a dedicated understanding expert (LLMUND) and a generation expert (LLMGEN). The understanding expert processes text and semantic visual tokens for multimodal reasoning and text generation, while the generation expert operates on VAE latent tokens for visual synthesis and editing. Both experts operate over the same interleaved multimodal context, preserving cross-task interaction while avoiding direct competition between heterogeneous objectives.
for an overview of the system. The overall framework processes interleaved inputs from text, images, and videos, encoding each modality into task-appropriate token representations. These heterogeneous tokens are then organized into a shared interleaved multimodal sequence using modality-aware rotary positional encoding, enabling unified context learning across diverse task formats. The model employs a dual-expert backbone initialized from Qwen2.5-VL, with a dedicated understanding expert (LLMUND) and a generation expert (LLMGEN). The understanding expert processes text and semantic visual tokens for multimodal reasoning and text generation, while the generation expert operates on VAE latent tokens for visual synthesis and editing. Both experts operate over the same interleaved multimodal context, preserving cross-task interaction while avoiding direct competition between heterogeneous objectives.
Unified context learning is achieved by converting heterogeneous inputs into a shared interleaved multimodal sequence. Text instructions are embedded using the language embedding layer of Qwen2.5-VL. For understanding-oriented visual inputs, the Qwen2.5-VL ViT encoder is used, which employs 14× spatial and 2× temporal patching followed by a 2×2 spatial merge to produce compact semantic visual tokens. For generation-oriented inputs, images or videos are encoded into continuous latent representations using the Wan2.2 3D causal VAE encoder, which supports both modalities through a unified latent space with 16× spatial downsampling and 4× temporal downsampling for videos. The resulting latent features preserve low-level appearance and temporal structure required for high-fidelity visual generation. As a result, Lance represents each sample as a unified interleaved multimodal sequence of text tokens, ViT semantic tokens, clean VAE latent tokens, and noisy VAE latent tokens. To handle such heterogeneous sequences, Lance adopts generalized 3D causal attention, partitioning the sequence into modality-specific segments where each segment attends to preceding clean segments to preserve causal dependencies. Within each segment, text tokens use causal attention, while visual tokens use bidirectional attention to capture spatial and spatiotemporal structure.
Decoupled capability pathways are implemented through specialized expert pathways. The understanding expert LLMUND primarily operates on text tokens and semantic visual tokens, autoregressively predicting target text tokens for multimodal understanding. Its hidden states are mapped by a language modeling head and optimized with the standard next-token prediction loss. The generation expert LLMGEN operates on VAE latent tokens and predicts generation-side hidden states conditioned on the interleaved multimodal context. These hidden states are projected through an LLM-to-VAE connector into the latent space and passed to a flow prediction head. The generation expert is optimized with a flow-matching objective, where the model predicts the velocity of the interpolated latent between a clean latent and Gaussian noise. The overall objective is a weighted sum of the understanding and generation losses, enabling the model to preserve unified context interaction while allowing semantic understanding and visual synthesis to specialize in their own representations, parameters, and objectives.
To better coordinate heterogeneous visual tokens within the unified context sequence, the authors introduce modality-aware rotary positional encoding (MaPE). Standard 3D-RoPE assigns positional indices based on spatiotemporal layout, but does not explicitly distinguish between heterogeneous token groups. MaPE injects token-group awareness into the positional indices by applying a modality-specific offset only along the temporal dimension. This design explicitly separates different visual token groups in the global positional space, enabling the model to better distinguish the roles of semantic ViT features, clean VAE conditions, and noisy VAE targets, while preserving the intrinsic spatial layouts and temporal coherence within images and videos. Refer to the illustration of modality-aware rotary positional encoding  for a visual explanation.
for a visual explanation.
Experiment
The evaluation utilizes standard benchmarks for image and video generation, multimodal editing, and video understanding, complemented by ablation studies on training scaling, data composition, and architectural design. These experiments validate that the unified framework consistently produces semantically aligned images and temporally coherent videos while precisely preserving structural details during editing tasks. Further analysis confirms that incorporating understanding-oriented and multi-task generation data significantly enhances cross-task contextual reasoning, while modality-aware positional encoding effectively reduces spatial ambiguity among heterogeneous visual tokens. Ultimately, the findings demonstrate that jointly optimizing generation, editing, and understanding within a compact architecture yields robust, scalable multimodal capabilities.
The authors evaluate a unified multimodal model across image and video generation, editing, and understanding tasks. Results show that the model achieves strong performance across diverse benchmarks, particularly in video generation and editing, while maintaining competitive results in understanding tasks despite using a smaller parameter count compared to many specialized models. The model's capabilities improve with increased training data and benefit from multi-task learning and modality-aware positional encoding. The model achieves top-tier performance in video generation among unified models, with strong results across quality and semantic dimensions. It demonstrates competitive image editing capabilities, particularly in preserving structural coherence and realistic textures. Performance improves with larger training budgets and benefits from multi-task training, indicating synergistic effects across generation and understanding tasks.
The authors evaluate the image editing performance of their model, Lance, on GEdit-Bench, comparing it against other unified and generation-only models. Results show that Lance achieves the highest overall score among unified models, demonstrating strong editing capabilities across multiple categories, particularly in background change, material modification, and subject replacement. The model outperforms several baselines with similar or larger parameter counts, indicating effective performance within a compact parameter budget. Lance achieves the best overall score among unified models on GEdit-Bench. Lance shows strong performance in key editing categories such as background change and material modification. Lance outperforms several baselines with larger parameter counts, indicating high efficiency within a compact model size.
The authors evaluate the impact of Modality-Aware Rotary Positional Encoding (MaPE) on a unified multimodal model across multiple tasks, including image generation, image editing, video generation, and video understanding. Results show that incorporating MaPE consistently improves performance across all evaluated tasks, with the most significant gains observed in image editing, suggesting that MaPE enhances cross-task alignment and visual synthesis by reducing positional ambiguity. Incorporating MaPE improves performance across all evaluated tasks, including image generation, image editing, video generation, and video understanding. The most notable improvement from MaPE is in image editing, indicating enhanced cross-task reasoning and alignment. The absence of MaPE leads to reduced performance across all tasks, highlighting its importance in maintaining contextual coherence and visual fidelity in unified multimodal modeling.
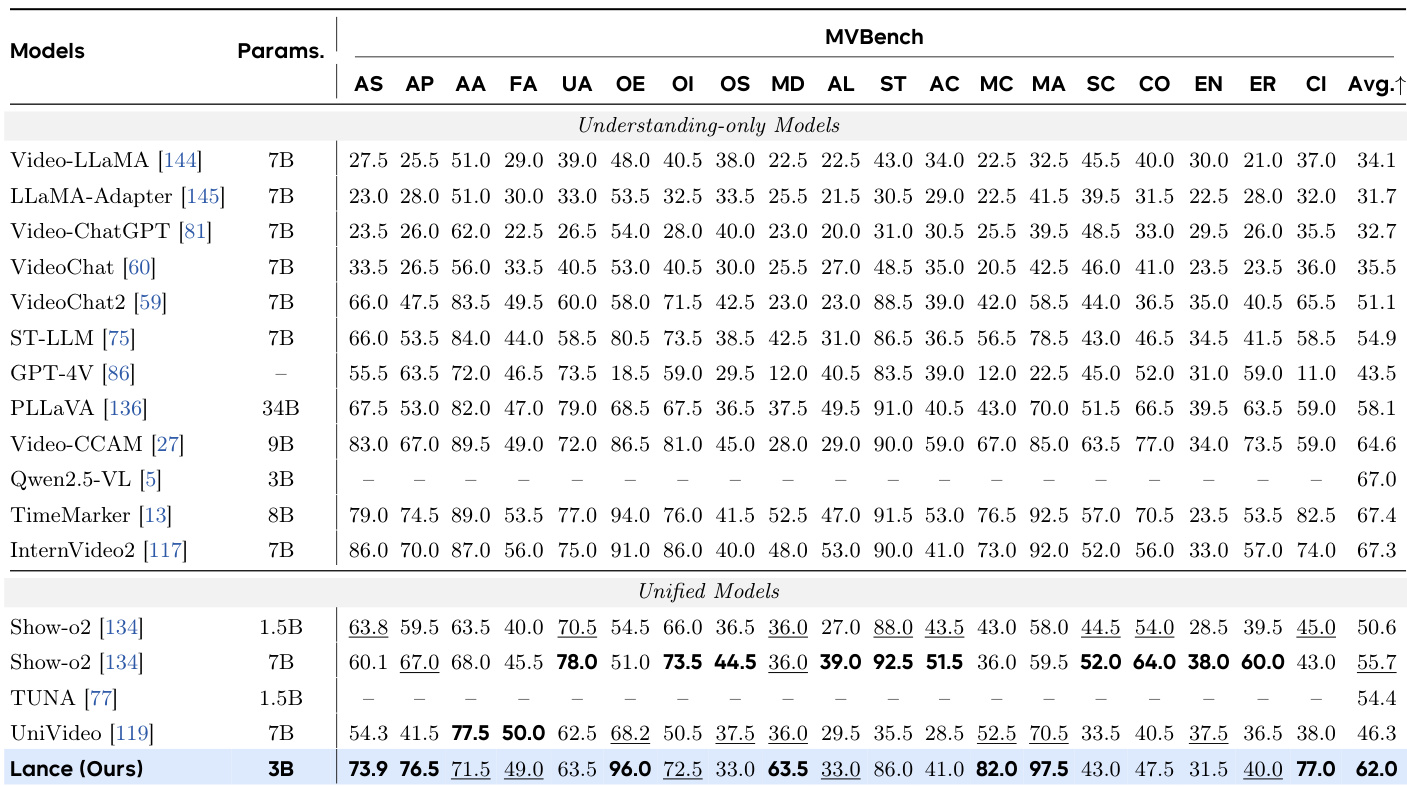
The authors evaluate Lance, a unified multimodal model with 3B activated parameters, across various tasks including video understanding, generation, and editing. Results show that Lance achieves top-tier performance among unified models on MVBench, outperforming existing models with significantly fewer parameters while maintaining strong capabilities in both generation and understanding. The model demonstrates robust performance across multiple dimensions, including visual quality, semantic fidelity, and temporal consistency, indicating effective integration of diverse tasks within a single framework. Lance achieves the highest overall score among unified models on MVBench, surpassing models with significantly more parameters. The model shows strong performance across both generation and understanding tasks, indicating effective multi-task synergy. Lance demonstrates high-quality outputs in video understanding, generation, and editing, highlighting its versatility in multimodal applications.
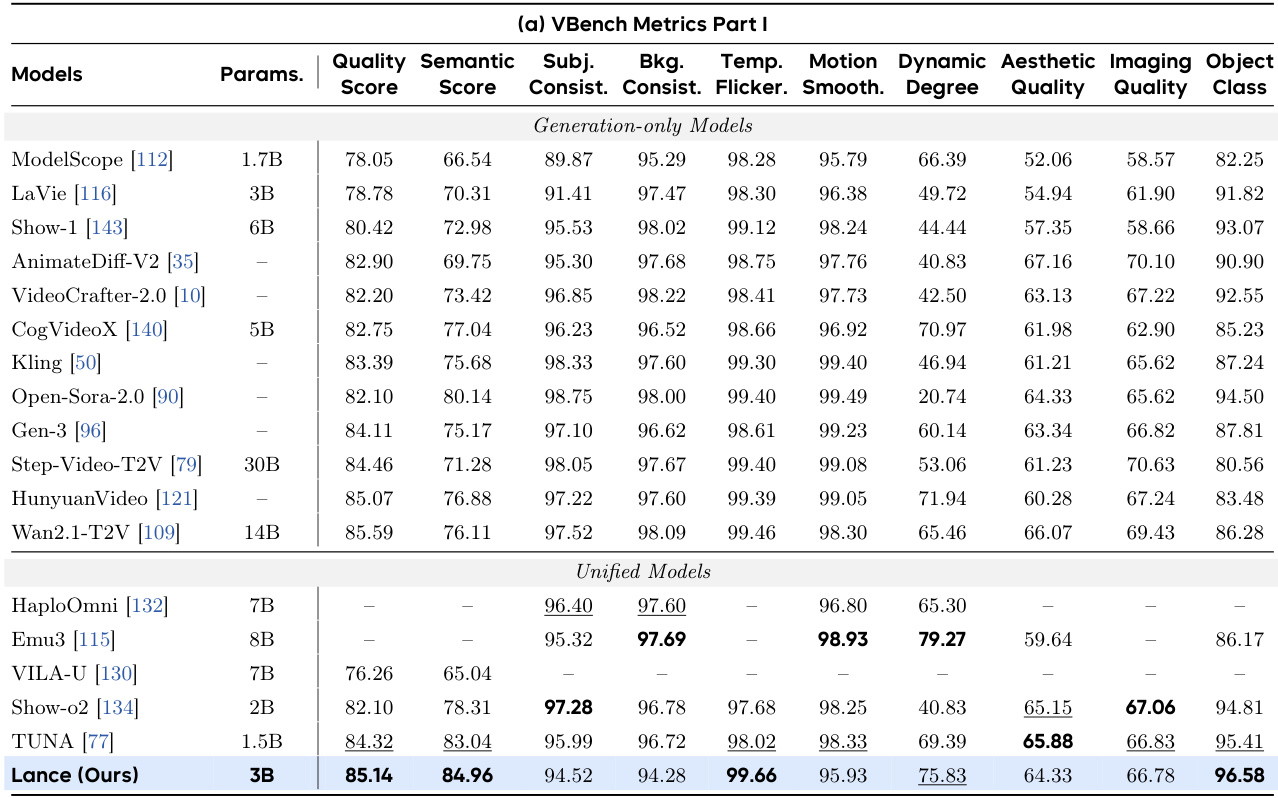
The authors evaluate the performance of Lance, a unified multimodal model with 3B activated parameters, across image generation, video generation, image editing, and video understanding tasks. Results show that Lance achieves competitive or top-tier performance compared to larger models on benchmarks for image and video generation, while also demonstrating strong capabilities in image editing and video understanding. The model's performance is further enhanced by multi-task training and a modality-aware positional encoding mechanism. The authors analyze the impact of training data composition and model scaling, showing that increasing training tokens improves prompt alignment, visual fidelity, and temporal consistency. Lance achieves top-tier performance on image generation benchmarks despite having significantly fewer parameters than competing models. Lance demonstrates strong multimodal editing capabilities, particularly in preserving structural coherence and realistic textures in both images and videos. The model's performance improves with increased training tokens and benefits from multi-task training, indicating the effectiveness of shared learning across different modalities and tasks.
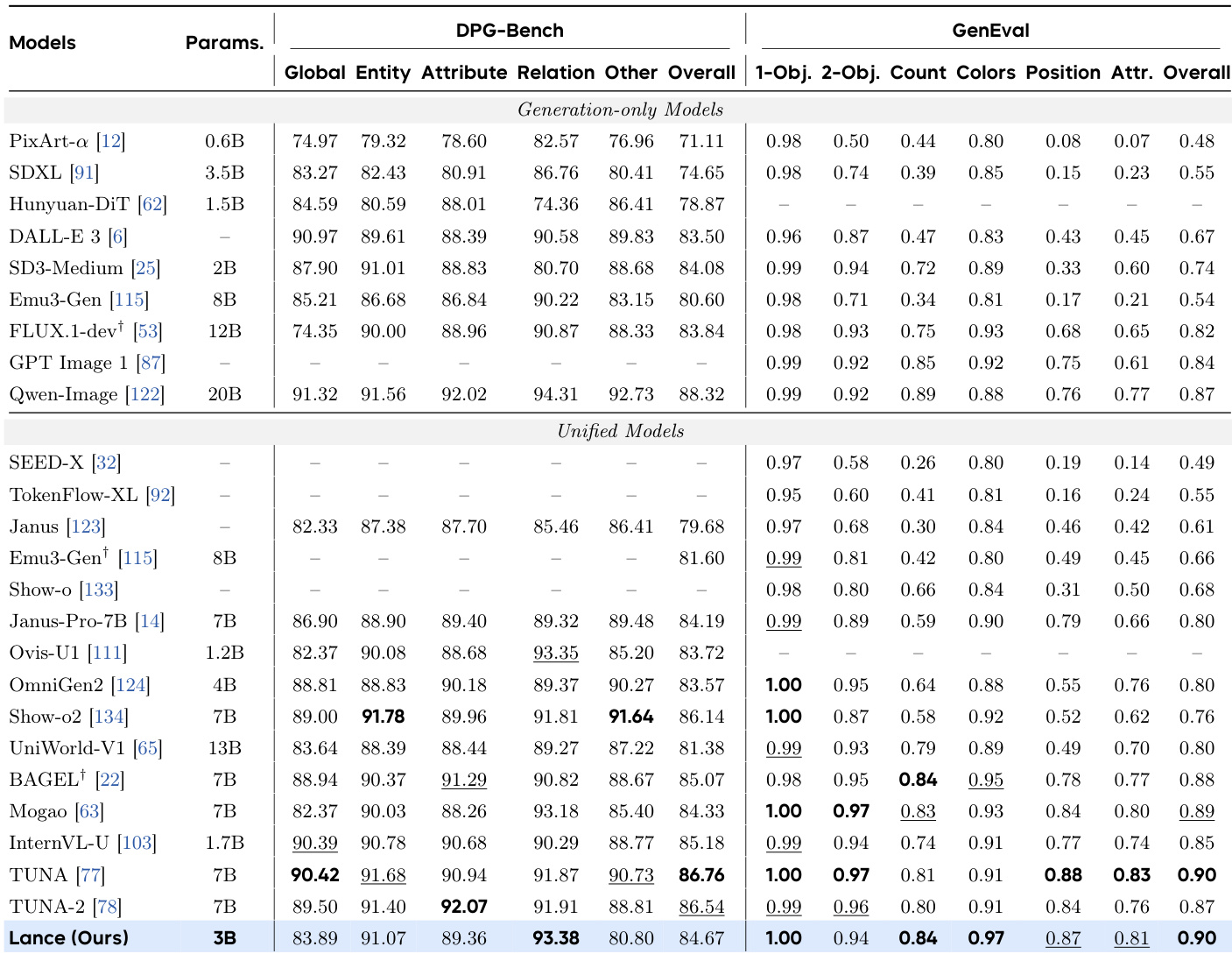
The authors evaluate a compact 3B-parameter unified multimodal model across image and video generation, editing, and understanding tasks to validate its cross-modal versatility and architectural efficiency. Benchmark assessments confirm that the model delivers top-tier performance among unified architectures, effectively balancing high-fidelity generation with robust understanding while surpassing larger specialized baselines. Ablation and comparative analyses further demonstrate that multi-task training and modality-aware positional encoding consistently improve cross-task alignment, structural coherence, and temporal consistency. These qualitative findings collectively indicate that shared learning across diverse modalities generates strong synergistic effects, allowing a streamlined model to maintain competitive performance without sacrificing visual or semantic fidelity.