Command Palette
Search for a command to run...
تتنافس الانتشرات المستمرة بشكل فعال مع الانتشارات المنفصلة في مجال اللغات
تتنافس الانتشرات المستمرة بشكل فعال مع الانتشارات المنفصلة في مجال اللغات
Zhihan Yang Wei Guo Shuibai Zhang Subham Sekhar Sahoo Yongxin Chen Arash Vahdat Morteza Mardani John Thickstun
الملخص
رغم الحيز الكبير الذي حظيت به عمليات النشر (Diffusion) مؤخراً في مجتمع نمذجة اللغات، إلا أن النشر المستمر (Continuous Diffusion) يُنظر إليه على أنه أقل قابلية للتوسع (Scalable) مقارنةً بالأساليب المنفصلة (Discrete approaches). ولمواجهة هذه الفكرة السائدة، أعدنا فحص نموذج "Plaid"، وهو نموذج لغة قائم على النشر المستمر (DLM) ويعتمد على الاحتمالية (Likelihood-based)، ومن ثم قمنا بإنشاء نموذج "RePlaid" من خلال محاذاة هندسة "Plaid" مع أحدث نماذج الدوال اللغوية المنفصلة (DLMs). في هذا الإطار الموحد، أثبتنا أول قانون للتوسع (Scaling law) يخص نماذج DLM المستمرة، والذي يتنافس بقوة مع النماذج المنفصلة: حيث يُظهر "RePlaid" فجوة في الحوسبة (Compute gap) تبلغ 20 مرة فقط مقارنةً بالنماذج الذاتية (Autoregressive models)، ويتفوق على "Duo" رغم استخدام عدد أقل من المعاملات (Parameters)، ويتفوق على "MDLM" في ظل ظروف التدريب المفرط (Over-trained regime).قمنا بتقييم أداء "RePlaid" مقارنةً بآخر نماذج DLM المستمرة: على مجموعة بيانات OpenWebText، حقق "RePlaid" رقماً قياسياً جديداً في الحد الأدنى لمعدل الخطأ اللغوي (PPL bound) قدره 22.1 بين نماذج DLM المستمرة، بالإضافة إلى جودة توليد فائقة. تشير هذه النتائج إلى أن النشر المستمر، عند تدريبه عبر دالة الاحتمالية، يمثل بديلاً تنافسياً للغاية وقابلاً للتوسع بالنسبة لنماذج DLM المنفصلة. وعلاوة على ذلك، نقدّم رؤى نظرية لفهم ميزة التدريب القائم على الاحتمالية. نظهر أن تحسين جدول الضوضاء (Noise schedule) لتقليل تباين الحد الأدنى العلوي للاحتمالية السفلية (ELBO) يؤدي بشكل طبيعي إلى ظهور خطأ تقاطع خطي (Linear cross-entropy)، الذي يمثل فقداناً للمعلومات، مع مرور الزمن. وهذا يؤدي إلى توزيع متساوٍ لصعوبة إزالة الضوضاء (Denoising difficulty) دون الحاجة إلى أي إعادة معايرة زمنية (Time reparameterization) خاصة بكل حالة.
One-sentence Summary
The authors construct RePlaid, a likelihood-based continuous diffusion language model, by aligning Plaid’s architecture with modern discrete DLMs to challenge scalability assumptions, establishing the first scaling law for continuous diffusion that rivals discrete approaches with a compute gap of only 20x compared to autoregressive models and a new state-of-the-art perplexity bound of 22.1 on OpenWebText among continuous DLMs, suggesting likelihood-based training as a competitive and scalable alternative.
Key Contributions
- This work constructs RePlaid by aligning the architecture of the likelihood-based continuous diffusion model Plaid with modern discrete diffusion language models. The resulting unified setting enables rigorous scalability comparisons with discrete approaches.
- Experiments establish the first scaling law for continuous diffusion language models, revealing a compute gap of only 20x compared to autoregressive models. RePlaid outperforms Duo while using fewer parameters and surpasses MDLM in the over-trained regime.
- Benchmarks on OpenWebText show that RePlaid achieves a new state-of-the-art perplexity bound of 22.1 among continuous diffusion language models. The paper also provides theoretical insights demonstrating that optimizing the noise schedule to minimize ELBO variance yields linear cross-entropy over time.
Introduction
Continuous diffusion language models offer unique advantages in controllability and sampling efficiency, yet they have historically underperformed discrete diffusion and autoregressive models in terms of scalability due to substantial compute overhead. To challenge this narrative, the authors introduce RePlaid, a modernized likelihood-based model that aligns continuous diffusion architectures with established discrete scaling protocols. Their unified benchmark reveals that continuous diffusion scales competitively by reducing the compute gap to only 20× relative to autoregressive baselines while achieving state-of-the-art perplexity. Additionally, the work provides theoretical insights demonstrating that likelihood-based training naturally optimizes noise schedules and embedding geometries to improve performance.
Dataset

- Composition and Sources: The authors utilize a reference corpus to precompute a dominant Universal POS tag for each GPT-2 subword token.
- Processing and Alignment: They align subwords to spaCy word spans via character offsets to resolve the mismatch between GPT-2 BPE splits and whole-word POS definitions.
- Usage: This data facilitates the analysis of embedding geometry conditioned on syntactic roles.
Method
The authors leverage a Variational Diffusion Model (VDM) framework adapted for text generation, referred to as Plaid. The methodology encompasses a robust data processing pipeline to construct valid input sequences, followed by a continuous diffusion process operating on low-dimensional token embeddings.
Input Representation and Data Processing
To ensure the input sequences align with the embedding space, the authors implement a specific pipeline for tokenization and part-of-speech (POS) alignment. Given a corpus of token IDs, the text is decoded and processed to recover character offsets for each subword. A POS tagger analyzes the decoded text at the word level, and these tags are inherited by the subwords based on character span overlap. This alignment ensures that syntactic information is preserved in the input representation.

The fast tokenizer then returns subwords with specific character spans, which may split a single word into multiple tokens. For instance, a verb like purring might be split into distinct subword units. The alignment procedure attributes all subwords belonging to a single word to the same POS tag.

To facilitate this alignment, a character-to-word map is allocated as an integer array. Each index in the array corresponds to a character position in the text and is filled with the index of the spaCy word covering that position. For each subword, the slice of this map corresponding to its span is analyzed, and the majority spaCy index is assigned as the tag.

Model Architecture and Diffusion Process
Once the input sequences are prepared, Plaid identifies a length-L sequence x with a matrix in {0,1}L×V, where V is the vocabulary size. The sequence is embedded into a continuous space via a learnable token-embedding matrix E∈RV×de, resulting in an embedded sequence e:=xE∈RL×de. The authors use low-dimensional embeddings with de=16 to reduce computational cost compared to high-dimensional one-hot injections.
The forward process q applies Gaussian noising to the embedding e:
q(zt∣x)=N(αte,σt2I),t∈[0,1],where αt and σt are smooth scalar functions satisfying the variance-preserving constraint αt2+σt2=1. The reverse process is parameterized by a time-conditioned denoising model xθ that outputs a categorical distribution over the vocabulary. The model predicts the clean embedding eθ(zt,t):=xθ(zt,t)E.
Training Procedure and Loss
Training minimizes the Negative Evidence Lower Bound (NELBO), which comprises three terms: prior loss, reconstruction loss, and diffusion loss. The prior loss regularizes the latent distribution at t=1. The reconstruction loss focuses on the clean data at t=0, while the diffusion loss optimizes the denoising trajectory across intermediate timesteps.
During training, the batch is adaptively split into a reconstruction sub-batch and a diffusion sub-batch. The reconstruction sub-batch samples time t=0 exactly, while the diffusion sub-batch samples t from a low-discrepancy distribution over [0,1]. The prior loss utilizes the entire batch. Additionally, self-conditioning is employed where, for a fraction of the batch, an initial gradient-free forward pass estimates the clean data to condition the subsequent prediction.
The noise schedule is learnable, parameterized as γ(t)=γ0+(γ1−γ0)γ~(t). The endpoints γ0 and γ1 minimize the diffusion loss directly, while the interior shape γ~(t) is updated to minimize the variance of the loss estimator. This learning process ensures that the per-timestep diffusion loss remains constant, effectively distributing denoising difficulty uniformly across time.
The overall training step involves computing the NELBO terms, backpropagating through the loss, and updating the optimizer. The schedule parameters and the denoiser weights are updated jointly to maximize the likelihood of the data under the model.
Experiment
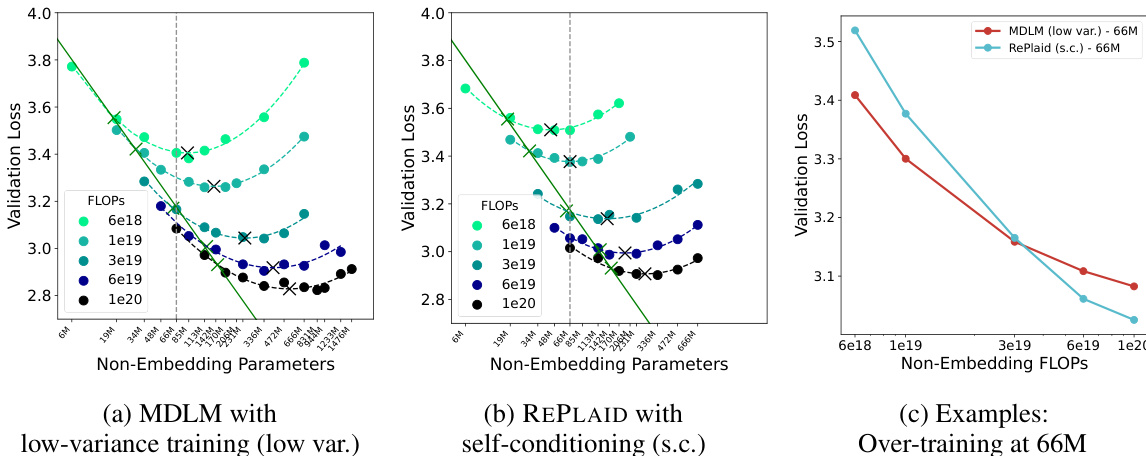
The evaluation utilizes a unified scaling benchmark on SlimPajama and generation tests on OpenWebText and LM1B to compare RePlaid against discrete and continuous diffusion language models. IsoFLOP analysis reveals that RePlaid scales competitively with autoregressive baselines while demonstrating superior parameter efficiency and outperforming MDLM in over-trained regimes. Furthermore, likelihood and sampling evaluations confirm that RePlaid achieves the best perplexity bounds among considered models and generates high-quality text comparable to discrete counterparts, highlighting the benefits of optimizing a true variational bound.
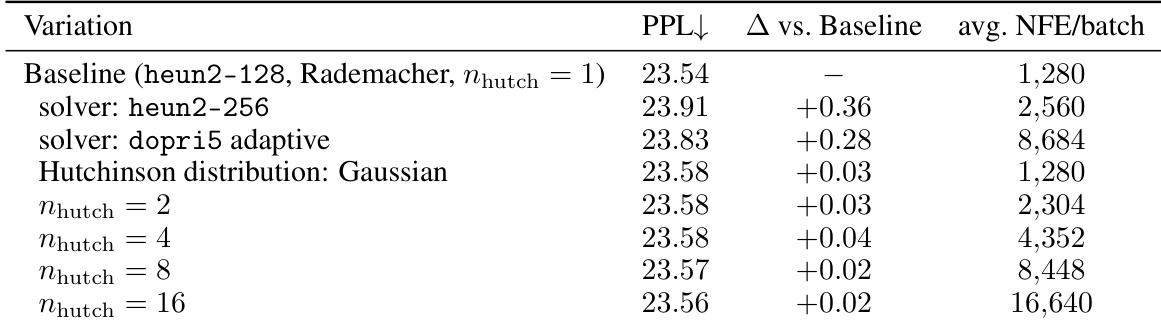
The experiment assesses the stability of the ODE-based likelihood estimator by varying solver settings and divergence estimation parameters. Results show that the mean Perplexity remains consistent across different configurations, indicating that the baseline solver is sufficiently converged and the estimator is unbiased. Increasing computational complexity, such as using more Hutchinson samples, does not yield significant performance gains. Solver variations, including higher step counts and adaptive methods, result in negligible changes to the likelihood estimate. The divergence estimator maintains consistent performance whether using Rademacher or Gaussian distributions. Raising the Hutchinson sample count increases computational cost substantially while having little effect on the final Perplexity score.
The authors investigate the impact of the chain-rule term on ODE-based likelihood estimation for RePlaid and LangFlow. They find that omitting this term significantly deflates PPL scores, creating a substantial bias, whereas including it ensures the estimate serves as a valid upper bound on negative log-likelihood. RePlaid consistently demonstrates superior likelihood performance compared to LangFlow under the corrected protocol. Excluding the chain-rule term creates a substantial downward bias in PPL estimation for both models. RePlaid achieves lower perplexity than LangFlow when the chain-rule correction is properly applied. The corrected estimation method produces results consistent with VDM NELBO baselines, unlike the uncorrected version which yields implausible scores.

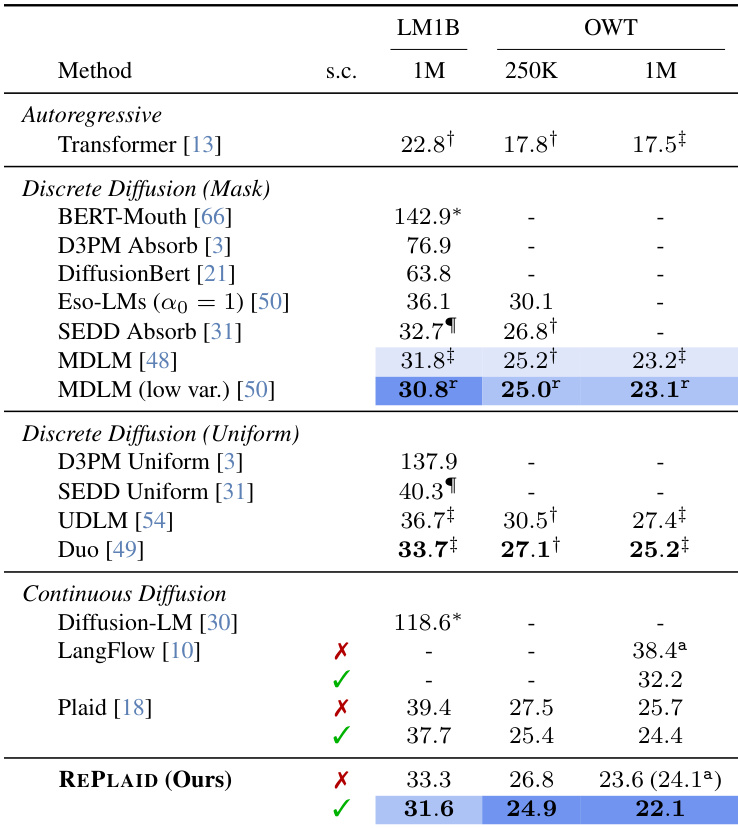
The the the table compares test perplexity across autoregressive, discrete diffusion, and continuous diffusion language models on LM1B and OpenWebText datasets. Results show that RePlaid with self-conditioning achieves the best performance among diffusion models, outperforming strong discrete baselines like MDLM and Duo on OpenWebText. Even without self-conditioning, RePlaid demonstrates superior performance compared to other continuous diffusion methods and the Duo baseline. RePlaid with self-conditioning achieves the lowest perplexity among diffusion models on OpenWebText. On LM1B, RePlaid with self-conditioning outperforms Duo but trails MDLM. RePlaid without self-conditioning outperforms Duo and LangFlow on OpenWebText.
The the the table presents an ablation study evaluating the contribution of specific architectural components to the RePlaid model's perplexity performance. The full configuration with self-conditioning achieves the optimal results, whereas removing learnable embeddings leads to the most severe degradation in model quality. Other components, including the learnable noise schedule and output prior, also demonstrate positive contributions to the final performance metrics. The complete RePlaid model with self-conditioning achieves the lowest perplexity among all tested configurations. Removing learnable embeddings results in the largest performance drop, significantly worsening the perplexity score. The learnable noise schedule and self-conditioning components provide substantial gains over their respective ablated versions.

Experiments evaluate the stability of an ODE-based likelihood estimator, demonstrating that baseline solver settings yield consistent results without requiring increased computational complexity. Further analysis validates the necessity of a chain-rule correction to prevent biased perplexity scores, confirming that RePlaid outperforms LangFlow when the estimation is properly calibrated. Comparative and ablation studies reveal that RePlaid with self-conditioning achieves superior performance against various diffusion and discrete baselines, with learnable embeddings identified as the most critical architectural component.