Command Palette
Search for a command to run...
الغاوسيات ثلاثية الأبعاد التوليدية مع التحكم في الكثافة المتعلمة
الغاوسيات ثلاثية الأبعاد التوليدية مع التحكم في الكثافة المتعلمة
Runjie Yan Yan-Pei Cao Peng Wang Ding Liang Yuan-Chen Guo
الملخص
نقدم "غاوسيانات العينة الكثافة" (DeG)، وهو تمثيل ثلاثي الأبعاد مبتكر صُمم لسد الفجوة بين البدالات التكيفية في التصيير والنمذجة التوليدية القابلة للتوسع. وعلى عكس النهج الحالية التي تقيد الغاوسيانات الثلاثية الأبعاد بشبكات بلورية (voxel grids) أو مصفوفات ثابتة، يُمثّل DeG مراكز الغاوسيانات كأخذات عينة من دالة كثافة احتمالية قابلة للتعلم مُعرَّفة فوق شجرة ثمانيات (octree). توفر هذه الصياغة إطاراً رياضياً رصيناً للتحكم التكيفي في الكثافة: ومن خلال التحسين المشترك للكثافة المكانية وخصائص الغاوسيانات تحت إشراف التصيير، يركّز نموذجنا بشكل طبيعي البدالات في المناطق ذات التعقيد الهندسي العالي. نحقق ذلك من خلال تدرج جديد لمساهمة خسارة التصيير، والذي يعمل كبديل قابل للتفاضل التام للحدس التكثيف والقص المنفصلة المستخدمة في خوارزمية Gaussian Splatting القياسية. التمثيل الناتج مرن للغاية، ويدعم فك ترميزاً متعدد الدقة من كامن واحد (latent code) بسيطاً عن طريق ضبط ميزانية أخذ العينات فقط. لتمكين التركيب التوليدي، ندرّب نموذج انتشار كامناً (latent diffusion model) على DeG. نُحدّد تحدياً حاسماً في تطبيق الانتشار على الكامنين ذيي البنية مجموعات غير مرتبة، والذي يمكن أن يبطئ التقارب بشكل كبير، ونقترح "VecSeq"، وهي آلية إعادة ترقيم قياسية تربط رموز الكامنين (latent tokens) بتسلسل سوبول ثلاثي الأبعاد حتمي (deterministic 3D Sobol sequence). يحول هذا مشكلة التوليد الغامضة للمجموعة إلى مهمة نمذجة تسلسل قوية. تُظهر التجارب الواسعة أن خطتنا التحليلية (pipeline) تحقق جودةً متفوقة في توليد ثلاثي الأبعاد من صورة واحدة، حيث تجمع بين التكيف الهيكلي للبدالات غير المهيكلة مع استقرار التدريب في الطرق القائمة على الشبكات.
One-sentence Summary
The authors propose Density-Sampled Gaussians (DeG), a 3D representation that models Gaussian centers as samples from a learnable probability density over an octree and employs a differentiable render loss contribution gradient for adaptive density control, and combine it with VecSeq, a deterministic Sobol-sequence re-indexing that stabilizes latent diffusion on unordered sets, achieving state-of-the-art single-image-to-3D generation.
Key Contributions
- Density-Sampled Gaussians (DeG) models Gaussian centers as samples from a learnable probability density function defined over an octree. A fully differentiable render loss contribution gradient replaces non-differentiable densification and pruning, enabling adaptive allocation of primitives to geometrically complex regions and variable-resolution decoding from a single latent code.
- A paired autoencoder compresses 3D assets into compact latent tokens and decodes them into DeG with end-to-end density optimization under rendering supervision. This yields substantially improved reconstruction quality under a comparable Gaussian budget and smooth scaling with increased anchor counts or token lengths.
- VecSeq addresses slow convergence caused by permutation ambiguity in unordered set-structured latents by anchoring latent tokens to a deterministic 3D Sobol sequence via optimal transport. This converts the set-generation problem into a robust sequence modeling task, leading to faster convergence and state-of-the-art single-image-to-3D generation quality.
Introduction
3D Gaussian Splatting has become a leading representation for real-time novel view synthesis, but existing generative pipelines struggle to preserve the core flexibility that makes Gaussians attractive: they typically tie output to a fixed structure (voxel grids, per-pixel or per-patch counts) and thus cannot adaptively allocate more primitives to complex regions. Methods that try to loosen these constraints either require costly per-object optimization to create ground-truth targets or sample primitives uniformly, failing to learn a global density that directs detail where it is needed most. The authors address this with Density-Sampled Gaussians (DeG), a generative representation that defines a rendering-optimized density over an octree and samples Gaussian centers from it, enabling variable-sized outputs and smart, adaptive capacity allocation under a learnable budget. They further build a paired autoencoding and diffusion pipeline with a VecSeq formulation that resolves permutation ambiguity in latent tokens, yielding high-quality single-image conditional generation with consistent gains in low-budget regimes.
Method
The authors present a generative framework comprising two core components: a Density-sampled Gaussian VAE (DeG-VAE) and a VecSeq diffusion transformer. The DeG-VAE encodes 3D assets into a compact latent space and decodes them via a learned spatial probability density, allowing for dynamic allocation of Gaussian primitives. The diffusion model then learns the distribution of these latents conditioned on a single input image. As shown in the framework diagram, the pipeline integrates encoding, density decoding, and attribute decoding to support variable-resolution outputs.
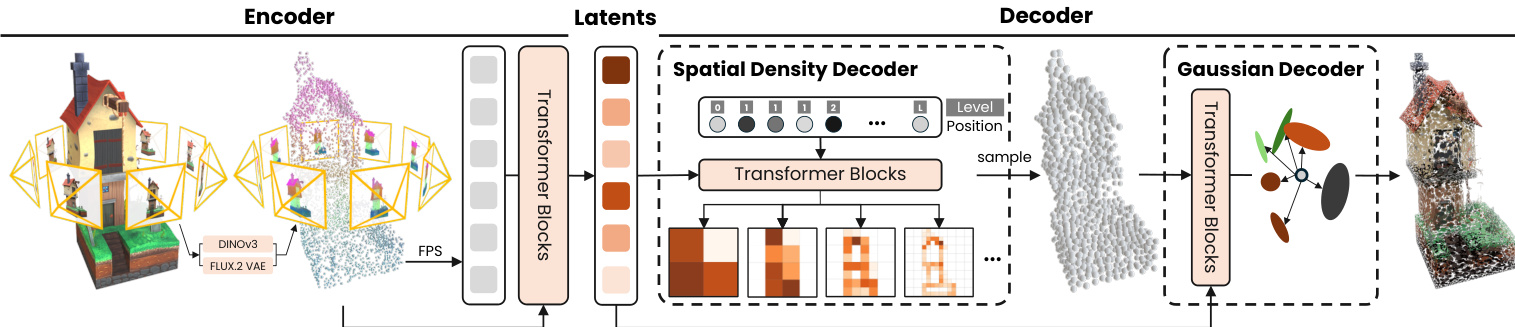
The DeG-VAE begins with a Set Encoder. For a 3D asset, the authors represent geometry and appearance as a set of latent tokens Z. They aggregate information from multi-view RGB renderings and explicit surface geometry. Feature maps are extracted using DINOv3 for semantic consistency and a FLUX.2 VAE for high-frequency texture details. Surface points are projected onto these feature maps. A transformer-based set encoder compresses these variable-length point features into a fixed-size latent set Z using Farthest Point Sampling (FPS).
To enable adaptive allocation, the authors formulate Gaussian center prediction as a sampling process from a learned conditional probability density qθ(x∣Z) over R3. This density is parameterized using an L-level octree factorization to maintain sparse computation. The joint probability is factorized as a product of conditional distributions over children cells. At inference, anchor points are drawn from this density, and the number of anchors P is adjustable to trade off speed for fidelity. As shown in the figure below, the network iteratively predicts density values for occupied voxels to allocate points from the coarsest to the finest level.

With the sampled anchors establishing spatial support, a transformer-based attribute decoder predicts the parameters of the Gaussian primitives, including opacity, scaling, rotation, and spherical harmonic coefficients. To capture local surface details, a local expansion mechanism allows each anchor to spawn K individual Gaussians with learned local offsets. This hierarchical approach yields N=P⋅K total splats. Refer to the detailed architecture diagram for the specific neural architectures of the encoder, density decoder, attribute decoder, and the diffusion transformer.
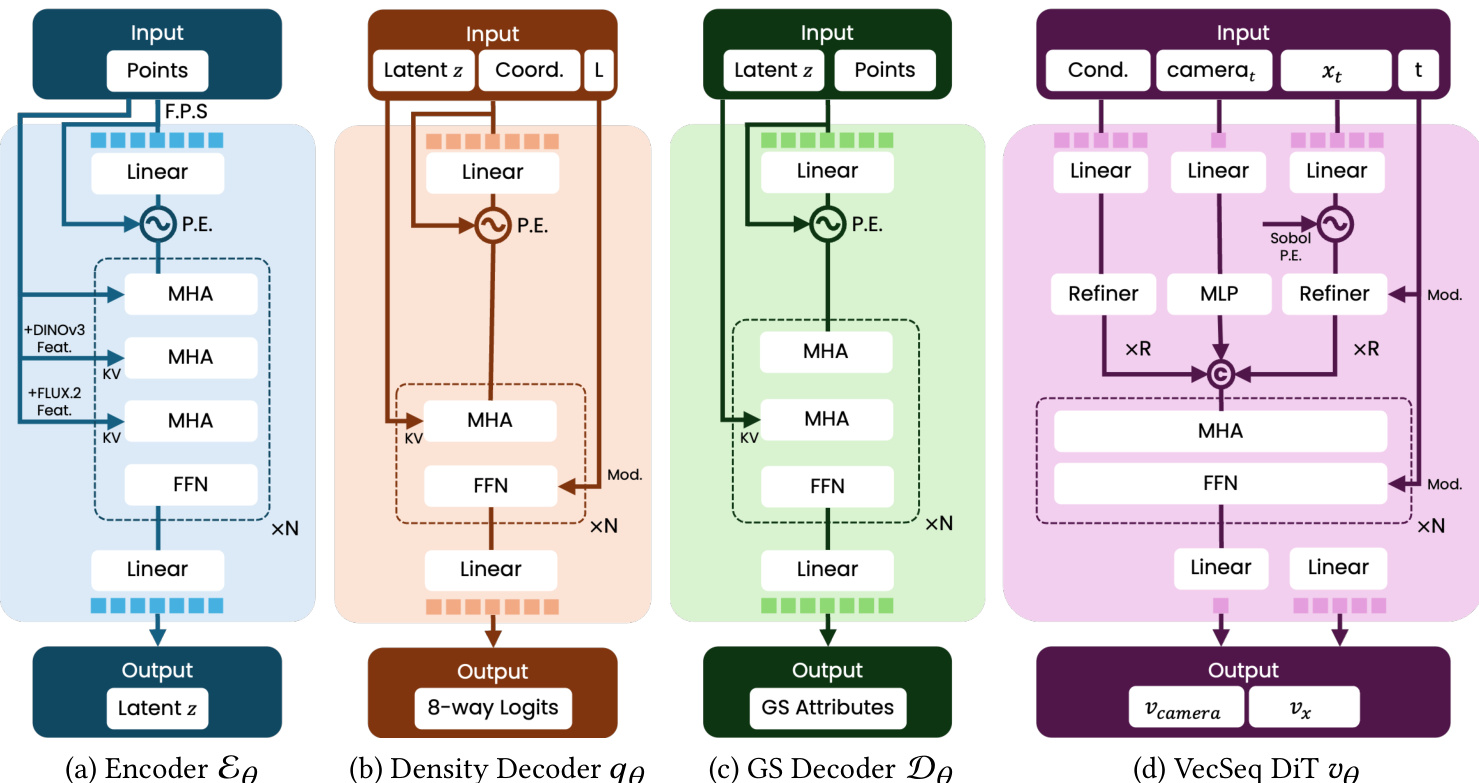
A key challenge in this pipeline is optimizing the spatial density qθ end-to-end, as the sampling operation is non-differentiable. The authors address this by deriving the render loss contribution gradient. They seek to minimize the expected rendering loss over the density distribution. The gradient computation involves a difference reward term: ΔLrender=Lrender({xi}i=1P)−Lrender({xi}i=jP). This term measures the marginal contribution of each anchor xj to reducing the rendering error, effectively performing differentiable densification and pruning. The authors implement an efficient version of this gradient by accumulating primitive-level contributions inside the standard 3DGS backward rasterization pass. The VAE is trained with a combination of structural supervision and rendering supervision via a three-stage curriculum: Structural Initialization, Appearance training, and Joint Refinement.
For the generative modeling task, the authors model the distribution of latent codes Z using a diffusion transformer based on the Flow Matching framework. A fundamental challenge here is permutation ambiguity; unordered set tokens lack intrinsic ordering, leading to slow convergence. To resolve this, the authors propose VecSeq, a canonical re-indexing strategy. They align the unordered latent tokens to a fixed, deterministic 3D Sobol sequence using optimal transport. This transforms the ambiguous set-generation problem into a robust sequence modeling task. As shown in the figure below, latent tokens are associated with 3D positions and canonically ordered by matching them to deterministic anchors, enabling the use of positional encoding in the diffusion transformer.
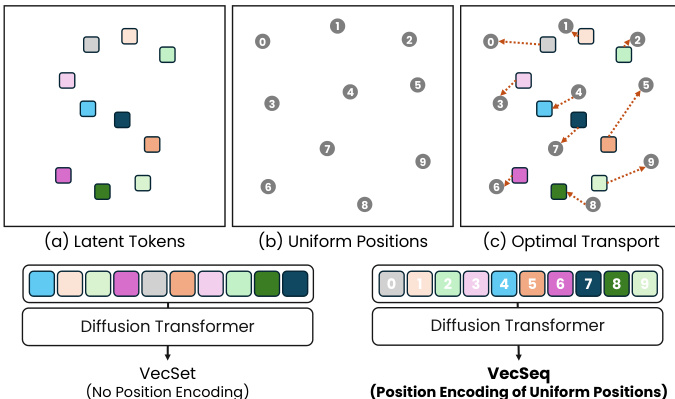
By injecting sinusoidal positional embeddings of the Sobol anchors into the diffusion model, the model learns to predict a sequence where the j-th output corresponds to a specific spatial location, significantly improving convergence and generation quality.
Experiment
The evaluation uses the Toys4K dataset for quantitative reconstruction and generation tests, with self-collected high-quality images for qualitative generation comparisons. Reconstruction experiments show that DeG‑VAE outperforms baselines by learning efficient, variable-sized Gaussian allocations that improve visual fidelity, especially under limited capacity, and that learned density control further enhances low-budget reconstruction. The generation pipeline achieves state-of-the-art image‑condition alignment and perceptual quality, with token reordering proving crucial for semantic consistency, while user studies confirm strong preference for its richer details and natural colors over competing mesh and Gaussian models. Occasional failure cases arise in novel views due to challenging conditioning inputs or limited generative capacity.
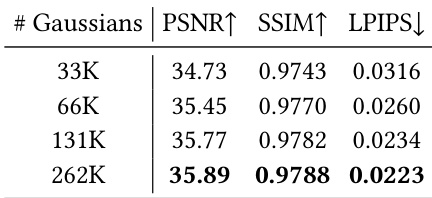
The authors evaluate the impact of the Gaussian budget on reconstruction quality by varying the number of decoded Gaussians while keeping the token length fixed. Results show that increasing the number of Gaussians consistently improves visual fidelity across all evaluated metrics. Reconstruction quality improves steadily as the number of decoded Gaussians increases. Higher Gaussian budgets yield better PSNR and SSIM scores while reducing LPIPS. The model demonstrates favorable scaling behavior with respect to the available Gaussian capacity.
The authors conducted a user study to evaluate the perceptual quality of their method against several baselines using complex prompts. Participants performed pairwise comparisons of rendered videos to assess overall quality and condition alignment. The proposed method achieved the highest preference rating, significantly outperforming competing mesh and Gaussian generation models. The proposed method secures the top rank in user preference, demonstrating superior visual quality and alignment with input images. All competing baselines receive lower preference ratings, with the proposed method showing a significant margin over the second-best approach. The study validates that the generated 3D assets are preferred over both mesh-based and Gaussian-based alternatives.

The authors evaluate the impact of token reordering during diffusion training by comparing their approach against a baseline that uses unordered latents. The results demonstrate that reordering tokens to establish consistent spatial correspondence significantly improves both prompt alignment and the overall distributional quality of the generated assets. Token reordering leads to better image-condition alignment compared to the unordered baseline. The proposed method achieves superior distributional quality with lower distance metrics. Establishing consistent spatial meaning for token indices makes positional embeddings more effective during training.

The authors evaluate their reconstruction method against representative baselines on a standard dataset. Results show that their approach substantially outperforms competing methods across all reported reconstruction quality metrics while using a comparable number of Gaussians, demonstrating more effective allocation of rendering capacity. The proposed method achieves the highest reconstruction quality among the compared approaches across all evaluated metrics. The method utilizes a similar Gaussian budget as the baselines but delivers superior visual fidelity through adaptive density allocation. Decoding time for the proposed method is slightly higher than the baselines, reflecting a minor trade-off for significantly improved reconstruction performance.

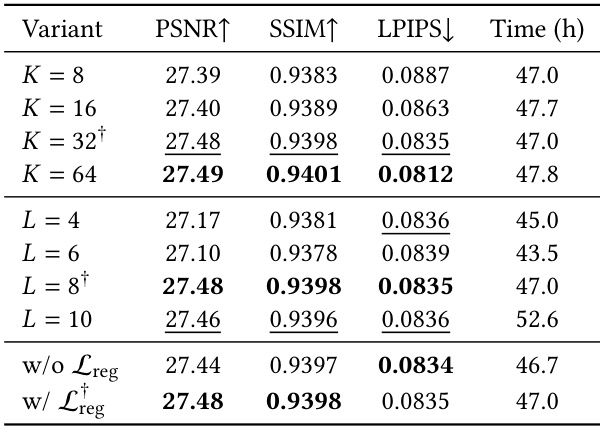
The authors ablate key hyperparameters of the DeG-VAE model, including the local expansion factor, octree depth, and regularization loss. The experiments demonstrate that moderate hyperparameter settings offer the best balance between reconstruction fidelity and computational efficiency. Incorporating the regularization loss is also shown to slightly enhance the overall reconstruction quality. Increasing the local expansion factor beyond a moderate value yields only marginal gains in reconstruction quality while increasing computational cost. Setting the octree depth to a moderate level achieves the best reconstruction performance, whereas deeper octrees incur higher training times with comparable quality. Omitting the regularization loss leads to a slight reduction in reconstruction fidelity compared to the full model configuration.
Experiments assess reconstruction quality scaling with Gaussian budget, user preference against baselines, token reordering benefits, and hyperparameter choices. Increasing the number of decoded Gaussians steadily improves visual fidelity, and moderate hyperparameter settings best balance quality and cost. A user study reveals the proposed method significantly outperforms mesh and Gaussian baselines in perceived quality and condition alignment. Token reordering to establish spatial correspondence consistently boosts prompt alignment and distributional quality, and the reconstruction method achieves superior results with similar Gaussian counts through more effective capacity allocation.