Command Palette
Search for a command to run...
ملخص
ملخص
Ryan Wei Heng Quek Sanghyuk Lee Alfred Wei Lun Leong Arun Verma Alok Prakash Nancy F. Chen Bryan Kian Hsiang Low Daniela Rus Armando Solar-Lezama
الملخص
تحقق النماذج اللغوية الكبيرة (LLMs) أداءً قوياً عبر طيف واسع من المهام، إلا أنها تبقى مقيدة و«متجمدة» (frozen) بعد مرحلة التدريب المسبق (pretraining)، حتى يتم تحديثها لاحقاً. وتتطلب العديد من التطبيقات الواقعية معلومات محدثة ومتعلقة بمجال محدد، مما يبرر الحاجة إلى آليات فعّالة لدمج المعرفة الجديدة. وفي هذا الإطار، نقدم إطار عمل «MEMO» (والمعنى الحرفي له: الذاكرة كنموذج)، وهو إطار معياري يقوم بتشفير المعرفة الجديدة في نموذج ذاكرة مخصص (MEMORY model)، مع الحفاظ على معلمات النموذج اللغوي الكبيرة (LLM) دون تغيير.ومقارنةً بالطرق الحالية، يوفر إطار MEMO عدة مزايا: (أ) القدرة على التقاط العلاقات المعقدة عبر المستندات المتعددة؛ (ب) المرونة والصلابة تجاه الضوضاء الناتجة عن عمليات الاسترجاع المعلوماتي (retrieval noise)؛ (ج) تجنب مشكلة «النسيان الكارثي» (catastrophic forgetting) في النموذج اللغوي الكبير؛ (د) عدم الحاجة إلى الوصول إلى أوزان النموذج اللغوي الكبير (LLM) أو قيم اللوغاريتمات الاحتمالية الناتجة (output logits)، مما يتيح دمجه بسهولة كنموذج قابل للإضافة والاستخدام الفوري (plug-and-play) مع كل من النماذج مفتوحة المصدر والنماذج الخاصة المغلقة المصدر (proprietary closed-source LLMs)؛ و(هـ) أن تكلفة الاسترجاع المعلوماتي (retrieval cost) في وقت الاستدلال (inference time) لا تعتمد على حجم مجموعة البيانات المرجعية (corpus size).وتُظهر نتائجنا التجريبية على ثلاثة معايير تقييمية (benchmarks)، وهي: BrowseComp-Plus، وNarrativeQA، وMuSiQue، أن إطار MEMO يحقق أداءً متفوقاً مقارنة بالطرق الحالية، وذلك عبر إعدادات وتطبيقات متنوعة.
One-sentence Summary
This paper introduces MEMO, a modular framework that encodes new knowledge into a dedicated MEMORY model while keeping large language model parameters unchanged to avoid catastrophic forgetting and enable plug-and-play integration with open and proprietary closed-source LLMs without requiring weight access, demonstrating strong performance compared to existing methods across the BrowseComp-Plus, NarrativeQA, and MuSiQue benchmarks.
Key Contributions
- The paper introduces MEMO, a modular framework that encodes new knowledge into a dedicated MEMORY model while keeping the large language model parameters unchanged.
- This method enables plug-and-play integration with both open and proprietary closed-source LLMs by operating without access to model weights or output logits.
- Evaluation on three benchmarks, including BrowseComp-Plus, NarrativeQA, and MuSiQue, demonstrates that the system achieves strong performance compared to existing methods across diverse settings.
Introduction
Large language models typically rely on static knowledge that becomes outdated, yet updating them through fine-tuning risks catastrophic forgetting or requires access to proprietary weights. Existing retrieval methods often struggle with cross-document reasoning, suffer from retrieval noise, and incur high inference costs as the knowledge base grows. To address these challenges, the authors introduce MEMO, a modular framework that encodes new knowledge into a dedicated MEMORY model while keeping the primary LLM parameters unchanged. They leverage a novel data synthesis pipeline to train the memory component on compositional representations and utilize a structured multi-turn protocol for querying. This approach enables plug-and-play integration with both open and closed-source models while maintaining retrieval costs independent of corpus size.
Dataset

-
Dataset Composition and Sources
- The authors construct a Reflection QA dataset (Qfinal) from a target corpus using a five-step synthesis pipeline driven by a Qwen2.5-32B-Instruct generator model.
- The source material consists of three knowledge-intensive benchmarks: BrowseComp-Plus, NarrativeQA, and MuSiQue.
- The pipeline aims to capture both single-document facts and cross-document relationships without embedding document identifiers or watermarks.
-
Key Details for Each Subset
- BrowseComp-Plus includes 300 sampled questions paired with 1,775 evidence and 1,766 negative documents, totaling 3,541 documents after filtering non-English instances.
- NarrativeQA consists of 293 questions spread across approximately 100,000 long-form documents such as books and movie scripts without negative documents.
- MuSiQue features 1,000 questions requiring multi-step reasoning across Wikipedia paragraphs, utilizing 2,648 evidence and 2,648 negative documents for a total of 5,296 documents.
-
Data Usage and Training
- The MEMORY model is initialized from Qwen2.5-14B-Instruct and trained for 3 epochs on the synthesized QA pairs.
- The synthesis process generates verified self-contained pairs, entity-surfacing pairs, and cross-document synthesis pairs to provide diverse training signals.
- For continual integration experiments, NarrativeQA is partitioned into two disjoint subsets containing roughly 640k QA pairs each to test model merging methods.
-
Processing and Chunking Strategies
- NarrativeQA documents undergo sliding window chunking with a 6,400-word window and 640-word overlap to handle long contexts, resulting in chunks primarily between 4,097 and 16,384 tokens.
- MuSiQue and BrowseComp-Plus documents are treated as single chunks since most fall below 512 tokens or 32,768 tokens respectively.
- QA pairs undergo verification to ensure self-containment, rewriting any instances with unresolved pronouns or implicit references while discarding ambiguous pairs.
- Negative document counts are capped per question to manage computational costs arising from the quadratic scaling of the cross-document synthesis step.
Method
The authors introduce MEMO (Memory as a Model), a modular framework designed to integrate domain-specific knowledge into large language models without modifying the parameters of the primary reasoning engine. The architecture decouples knowledge storage from reasoning by employing a frozen Executive model for inference and a dedicated, trainable Memory model to encode knowledge from a target corpus. The overall framework operates through two distinct phases: a training phase to construct the Memory model and an inference phase where the Executive model queries this memory.
Refer to the framework diagram for a visual breakdown of the training and inference pipelines.
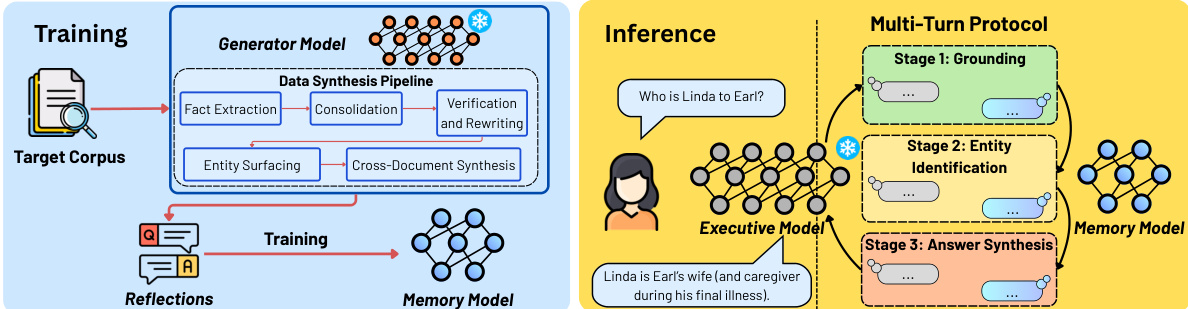
The training phase begins with a Target Corpus, which is processed by a Generator Model through a Data Synthesis Pipeline. This pipeline first performs Fact Extraction, followed by Consolidation and Verification and Rewriting to ensure accuracy. Simultaneously, the system conducts Entity Surfacing and Cross-Document Synthesis to capture complex relationships across the corpus. The output of this process is a set of Reflections, which serve as a reflection QA dataset. The Memory Model is then initialized from a small pretrained language model and trained via supervised fine-tuning on these reflections. Crucially, the model is optimized to map questions directly to answers without access to source documents at inference time. This forces the Memory Model to internalize knowledge parametrically rather than relying on retrieval. The training objective minimizes the next-token prediction loss over answer tokens only:
L(φ)=−(qi,ai)∈Qfinal∑t=1∑∣ai∣logMφ(ai(t)qi,ai(1:t−1)).During the inference phase, the frozen Executive Model interacts with the Memory Model through a structured Multi-Turn Protocol. This protocol is designed to progressively improve the likelihood of producing a correct final answer through three sequential stages. In Stage 1 (Grounding), the Executive Model decomposes the user query into atomic, clue-probing sub-questions. The Memory Model answers these independently to provide contextual grounding. In Stage 2 (Entity Identification), the Executive Model uses the grounding responses to iteratively narrow a set of candidate entities via targeted follow-up queries until a single entity is identified. Finally, in Stage 3 (Answer Synthesis), the Executive Model queries the Memory Model for supporting facts regarding the identified entity. Once sufficient evidence is gathered, the Executive Model synthesizes the accumulated responses into a final answer. This process ensures that interactions remain compact and independent of the corpus size, allowing the system to function effectively even with black-box Executive models.
Experiment
MEMO consistently outperforms retrieval-based baselines across long-context and multi-hop reasoning benchmarks while maintaining robustness against retrieval noise where other methods degrade. The framework supports flexible plug-and-play integration with diverse EXECUTIVE and MEMORY models, demonstrating that structured multi-turn evaluation and specific data synthesis steps are critical for maximizing performance. Furthermore, continual integration via model merging offers significant compute savings compared to full retraining without sacrificing the qualitative advantages over standard retrieval approaches.
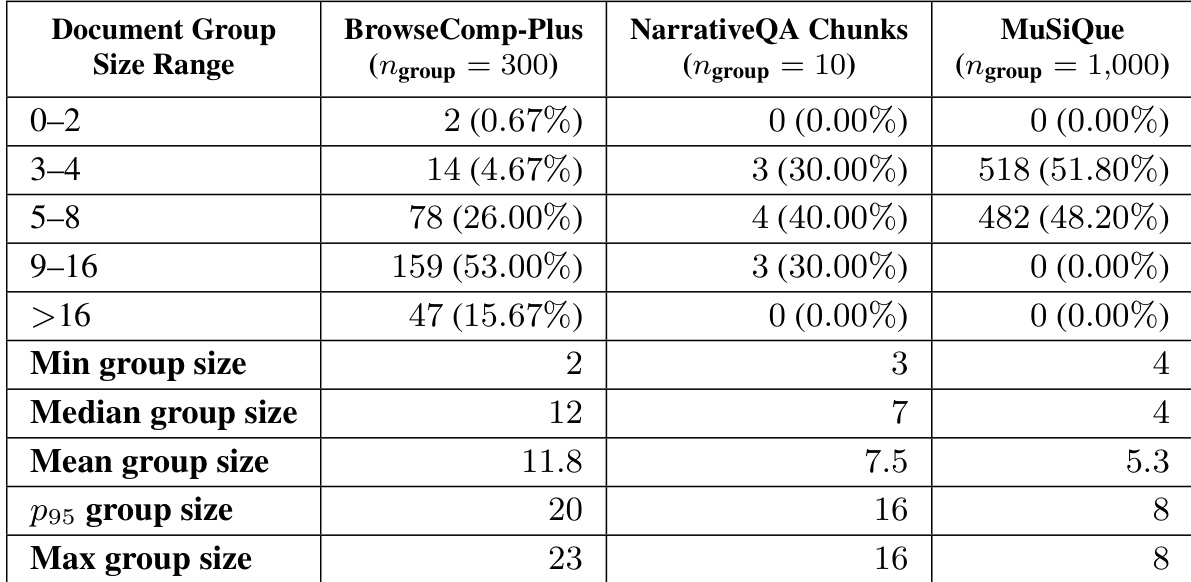
The the the table presents the distribution of document group sizes across three benchmarks: BrowseComp-Plus, NarrativeQA Chunks, and MuSiQue. BrowseComp-Plus exhibits the largest group sizes, indicating a higher demand for multi-document synthesis compared to the other datasets. Conversely, MuSiQue is characterized by smaller group sizes, while NarrativeQA Chunks occupies an intermediate position. BrowseComp-Plus exhibits the largest document group sizes, with the majority of samples falling into the upper ranges. MuSiQue demonstrates the smallest group sizes, with the maximum group size being notably lower than the other datasets. NarrativeQA Chunks displays a moderate distribution, with the highest concentration of samples in the middle size ranges.
The authors evaluate various model merging strategies to facilitate continual integration, comparing families such as linear, SLERP, TIES, and DARE. The results indicate that merging methods employing sparsification and sign-conflict resolution generally outperform simple linear averaging or interpolation, with TIES showing the strongest performance. TIES demonstrates the highest accuracy among the tested merging configurations. Lower sparsification densities combined with sign-conflict resolution yield more robust results than higher densities. SLERP interpolation produces the lowest accuracy compared to other merging approaches.

The experiment assesses the robustness of retrieval-based baselines NV-Embed-V2 and HippoRAG2 against varying levels of retrieval noise. Both methods exhibit pronounced sensitivity to distractor documents, with accuracy declining consistently as noise levels increase from zero to double the evidence count. This degradation confirms that standard retrieval systems struggle to filter irrelevant information effectively under realistic corpus conditions. Both NV-Embed-V2 and HippoRAG2 show consistent performance drops as noise levels rise from zero to double the evidence count across both datasets. Accuracy degradation is immediate even with a single distractor document per evidence item, indicating high fragility to noise. HippoRAG2 experiences a larger accuracy reduction on BrowseComp-Plus than on MuSiQue when the noise level is doubled.

The authors evaluate model merging as a cost-effective alternative to full retraining for continual integration on the NarrativeQA dataset. Results indicate that merging substantially lowers computational costs while maintaining performance that exceeds retrieval-based methods, despite a trade-off in accuracy compared to the retrained baseline. Merging models trained on disjoint subsets significantly reduces cumulative compute requirements compared to full retraining on the combined dataset. The merging approach incurs a measurable accuracy penalty relative to full retraining across both tested executive models. Despite the performance gap, the merged model maintains superior performance over standard retrieval-based baselines.

The authors evaluate model performance without context versus with perfect retrieval to assess dataset suitability. Results show a substantial disparity across all benchmarks, confirming that the models rely heavily on evidence documents to answer questions correctly. BrowseComp-Plus exhibits the largest gap, indicating answers are absent from parametric knowledge, while MuSiQue shows higher baseline performance without context. Large performance gaps between no context and perfect retrieval confirm that all benchmarks require external evidence. BrowseComp-Plus demonstrates the widest gap, indicating answers are absent from the model's parametric knowledge. MuSiQue yields the highest scores without context, suggesting its Wikipedia-based questions align with pre-trained knowledge.

The evaluation analyzes benchmark characteristics, model merging strategies, and retrieval robustness across datasets including BrowseComp-Plus and MuSiQue. Results indicate that BrowseComp-Plus demands significant multi-document synthesis and that standard retrieval baselines exhibit high sensitivity to noise. Furthermore, merging techniques like TIES offer a cost-effective alternative to full retraining that surpasses retrieval methods, while substantial disparities between performance without context and with perfect retrieval confirm that models rely heavily on external evidence.