Command Palette
Search for a command to run...
دمج تحسين السياسة الذاتية والتنقيح للاستدلال ذو السياق الطويل في النماذج اللغوية الكبيرة
دمج تحسين السياسة الذاتية والتنقيح للاستدلال ذو السياق الطويل في النماذج اللغوية الكبيرة
Miguel Moura Ramos Duarte M. Alves André F. T. Martins
الملخص
يتطلب تكييف النماذج اللغوية الكبيرة (LLMs) مع المهام ذات السياقات الطويلة أساليب ما بعد التدريب التي تحافظ على الدقة واتساق المعنى عبر آلاف الـtokens. تواجه النهج الحالية قيوداً عدة، تتمثل في: 1) معاناة الأساليب غير المتوافقة مع السياسة (off-policy)، مثل الضبط الدقيق المشرف (SFT) والضغط المعرفي (KD)، من انحياز التعرض (exposure bias) وصعوبة محدودة في التعافي من الأخطاء الناتجة عن النموذج على مدى زمني طويل؛ 2) تفوق أساليب التعلم التعزيزي المتوافقة مع السياسة (on-policy)، مثل تحسين السياسة النسبية الجماعية (GRPO)، في محاذاة التدريب مع الحالات التي يولدها النموذج، غير أنها تعاني من عدم الاستقرار وكفاءة عيّنات ضعيفة بسبب ندر المكافآت (sparse rewards)؛ 3) توفير الضغط المتوافق مع السياسة (OPD) إرشادات مكثفة على مستوى الـtokens، لكنه لا يحسّن مباشرة إشارات المكافآت التعسفية. في هذا البحث، نقترح طريقة «الضغط المتوافق مع السياسة النسبية الجماعية المُضاغطة» (dGRPO)، وهي منهج لاستنتاج النصوص طويلة السياق، يعزز GRPO بإرشادات مكثفة من نموذج معلمٍ أقوى عبر تقنية OPD. كما نقدم مجموعة بيانات اصطناعية طويلة السياق تُعرف بـ LONGBLOCKS، تغطي الاستنتاج متعدد الخطوات (multi-hop reasoning)، والإرساء السياقي (contextual grounding)، والتوليد طويل النموذج (long-form generation). أجرينا تجارب مكثفة ودراسات إزالة العناصر (ablations) لمقارنة التدريب غير المتوافق مع السياسة، وGRPO ذو المكافآت النادرة، ونهجنا المدمج، مما أسهم في تطوير وصفة محسّنة لمحاذاة السياقات الطويلة.
One-sentence Summary
This paper proposes Distilled Group Relative Policy Optimization (dGRPO), which augments GRPO with dense guidance from a stronger teacher via on-policy distillation to mitigate the exposure bias of off-policy methods and the instability of sparse-reward reinforcement learning, and introduces the LONGBLOCKS synthetic dataset spanning multi-hop reasoning, contextual grounding, and long-form generation to validate an improved recipe for long-context alignment through extensive experiments comparing off-policy training, sparse-reward GRPO, and the combined approach.
Key Contributions
- The paper introduces Distilled Group Relative Policy Optimization (dGRPO), a method that augments Group Relative Policy Optimization with dense guidance from a stronger teacher via on-policy distillation. This combination addresses the instability of sparse-reward reinforcement learning and the exposure bias of off-policy methods by optimizing on model-generated trajectories with dense supervision.
- A synthetic long-context dataset named LONGBLOCKS is presented to support long-context training with examples covering multi-hop reasoning, contextual grounding, and long-form generation. This resource enables the evaluation and training of models on tasks requiring robustness to distant dependencies and stable reasoning over extended horizons.
- Extensive experiments demonstrate that combining off-policy cold starts with on-policy optimization yields consistent improvements in long-context performance without sacrificing short-context capabilities. These findings establish a practical post-training recipe that effectively aligns large language models for complex long-horizon generation tasks.
Introduction
Adapting large language models to long-context tasks is essential for applications like codebase understanding and multi-session interactions. Existing post-training methods face significant hurdles where off-policy approaches suffer from exposure bias and on-policy reinforcement learning suffers from instability due to sparse rewards. The authors address these limitations by proposing Distilled Group Relative Policy Optimization (dGRPO), which augments Group Relative Policy Optimization with dense guidance from a stronger teacher. They also introduce LONGBLOCKS, a synthetic dataset designed to support multi-hop reasoning and long-form generation, resulting in a stable recipe for long-context alignment that preserves short-context capabilities.
Dataset
Dataset Composition and Sources
- The authors introduce LONGBLOCKS, a multilingual synthetic dataset containing 193,219 question-answer pairs designed for long-context adaptation.
- Data originates from diverse corpora including ArXiv, Wikipedia, StackExchange, Project Gutenberg Books, Stack-Edu, FineWeb2-HQ, and Institutional-Books-1.0.
- The collection spans more than 30 natural languages and 15 programming languages.
Processing and Filtering
- A two-stage pipeline generates the data by sampling sufficiently long, self-contained documents from the source corpora.
- The team uses Qwen3-Next-80B-A3B-Thinking to create candidate question-answer pairs that require integrating evidence across extended contexts.
- Malformed and near-duplicate documents are removed using fuzzy deduplication.
- An LLM-as-a-judge step verifies candidates and rejects malformed outputs, incomplete answers, unsupported answers, and questions answerable from a local span.
- Question types include summary, multi-part information retrieval, multi-hop reasoning, comprehensive, and classification questions.
Training Usage and Mixture
- The dataset supports both off-policy warm-up and on-policy alignment.
- During SFT and RL, the authors maintain a fixed 10/90 token-level mixture of short- and long-context data.
- Short-context samples are drawn uniformly from Nemotron-Post-Training-Dataset-v2 while long-context samples come from LONGBLOCKS.
Additional Processing Details
- Programming and markup languages are sampled uniformly from Stack-Edu.
- Generated outputs strictly follow a format of Question: followed by Answer: .
- Prompts ensure questions require locating information from multiple parts of the document or reasoning across different sections and themes.
Method
The authors propose a unified training pipeline designed to scale reinforcement learning to long-context reasoning tasks. Refer to the framework diagram for an overview of the two-stage process.
The pipeline begins with an off-policy cold-start stage using Supervised Fine-Tuning (SFT). This initial phase utilizes high-quality short- and long-context instructions to bootstrap long-context behavior. By providing dense token-level supervision, this warm-up improves the coherence of long-context rollouts and stabilizes subsequent on-policy learning. This initialization is critical in long-horizon settings where token-level advantage estimation can become brittle if rollout quality is low.
Following initialization, the model undergoes on-policy optimization using Distilled Group Relative Policy Optimization (dGRPO). This stage addresses the limitations of standard off-policy methods, such as exposure bias, and the sample inefficiency of pure on-policy RL. dGRPO combines two complementary signals: sparse outcome-level rewards from Group Relative Policy Optimization (GRPO) and dense token-level guidance from a teacher model via On-Policy Distillation (OPD).
GRPO simplifies value estimation by removing the need for a separate value function critic. Instead, it estimates the baseline from a group of sampled completions {o1,o2,…,oG} for a given prompt p. To mitigate the brittleness of sparse rewards in long-context training, dGRPO adds a KL divergence term that anchors the student policy to the teacher policy on the trajectories actually visited by the student. The objective function is defined as:
IdGRPO(θ)=Ep∼P,{oi}i=1G∼πθold(⋅∣p)G1i=1∑G∣oi∣1t=1∑∣oi∣min(ρi,t(θ)A^i,t,ρˉi,t(θ)A^i,t)−βDKL(πθ(⋅∣p,oi,<t)πteacher(⋅∣p,oi,<t))where β≥0 controls the strength of teacher regularization. The first term optimizes sparse rewards, while the KL term provides token-level feedback.
To support this training, the authors utilize a synthetic long-context dataset. High-quality instructions are generated to ensure tasks require understanding the full document. As shown in the figure below:

Experiment
The evaluation compares a two-stage post-training pipeline against base and SFT-only models using comprehensive short-context reasoning and long-context retrieval benchmarks. Main results indicate that combining SFT with dGRPO enables robust scaling to long-context tasks while preserving short-task accuracy, whereas reinforcement learning without a warm start degrades performance. Ablation studies confirm that dGRPO stabilizes optimization compared to alternatives and achieves optimal performance with an external teacher and balanced data allocation, validating that the approach shifts the performance frontier beyond larger baseline models.
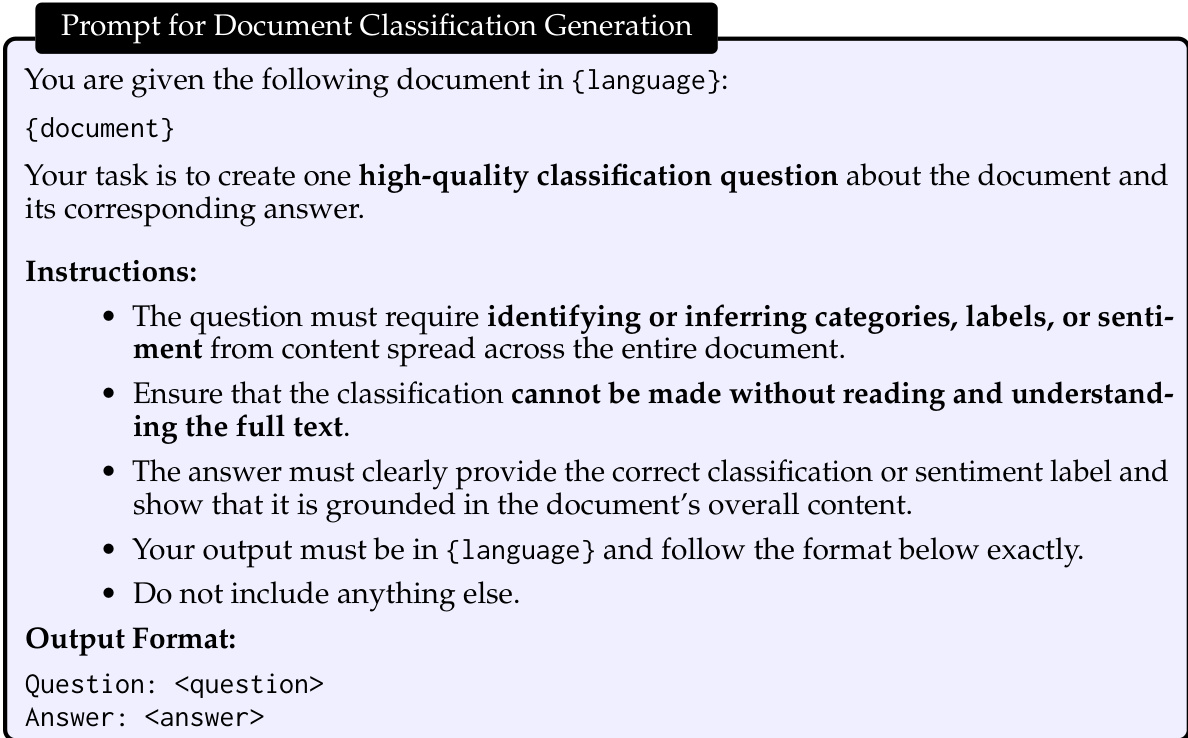
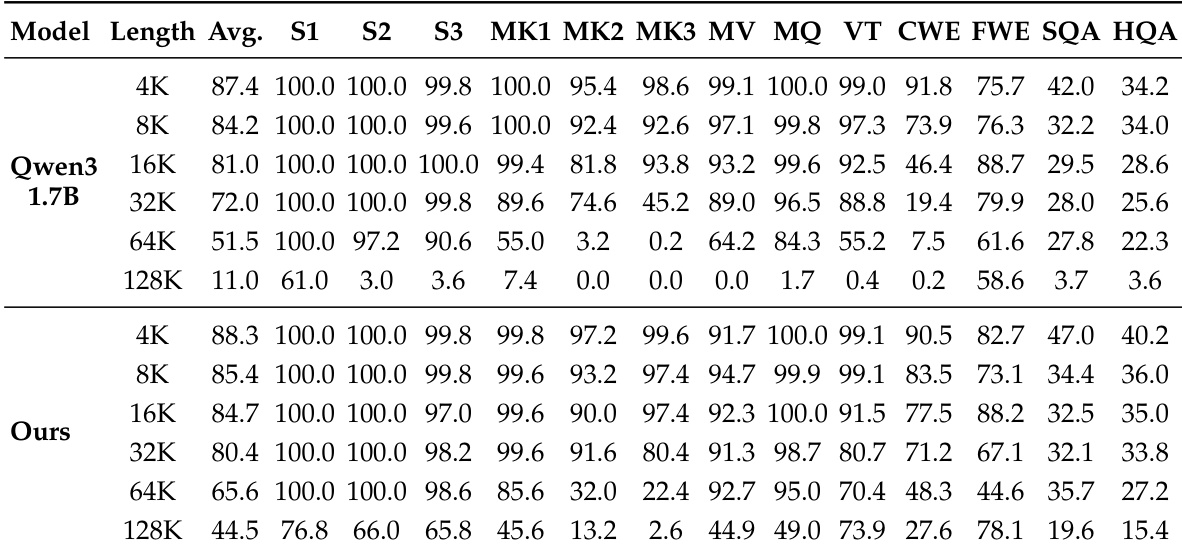
The authors compare their proposed model against the base Qwen3-1.7B model using the RULER benchmark to evaluate performance across varying context lengths. Results indicate that the proposed approach achieves a higher average score and demonstrates substantial improvements over the base model, particularly as the sequence length increases. While the base model struggles significantly at the longest context length, the proposed model maintains much stronger performance, showing effective scaling for long-context retrieval and reasoning tasks. The proposed model achieves a higher average RULER score compared to the base Qwen3-1.7B model. Performance gains become increasingly pronounced at longer sequence lengths, with a significant advantage observed at the maximum context length. The base model shows a sharp decline in performance at the longest context length, whereas the proposed model retains substantially higher accuracy.
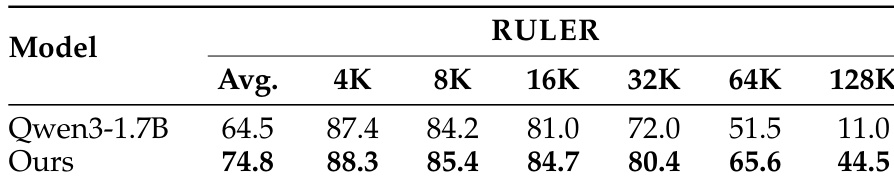
The authors compare their proposed method against the base Qwen3-1.7B model on a suite of long-context benchmarks. The results indicate that the proposed recipe yields substantial improvements across most categories, particularly in retrieval and question-answering tasks, while preserving performance in other areas. Retrieval tasks like PassKey and Number retrieval show dramatic performance increases compared to the baseline. Question answering and reasoning categories demonstrate significant relative gains over the base model. The average score across all categories increases substantially, validating the method's effectiveness.
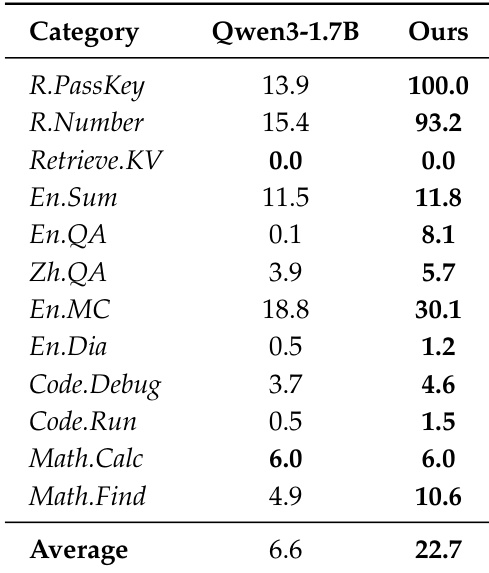
The the the table compares multilingual benchmark results between the base Qwen3-1.7B model and the authors' proposed model. The proposed model demonstrates an overall improvement in average performance across the tested languages. While the base model retains higher scores in German and French, the authors' approach yields substantial gains in Japanese and Chinese. The proposed model achieves a higher average score compared to the base Qwen3-1.7B model. Substantial performance improvements are observed in Japanese and Chinese. The base model outperforms the proposed version in German and French tasks.
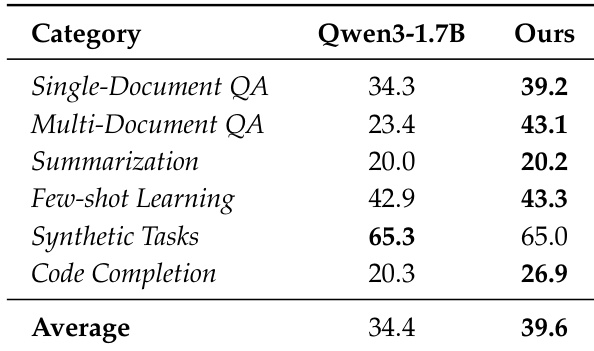
The authors evaluate their proposed training recipe against the base Qwen3-1.7B model across a diverse suite of tasks including QA, summarization, and coding. The results indicate that their method achieves a higher average performance, driven largely by substantial gains in Multi-Document QA and Code Completion. While performance on Synthetic Tasks remains comparable to the baseline, the approach successfully enhances capabilities in complex reasoning and generation tasks without degrading performance in others. The proposed model achieves a higher overall average score compared to the base model. Significant performance improvements are observed in Multi-Document QA and Code Completion categories. Performance in Single-Document QA, Summarization, and Few-shot Learning shows modest gains over the baseline.
The authors compare their proposed model against the base Qwen3-1.7B across varying context lengths to evaluate long-context capabilities. The results show that while the base model suffers significant performance degradation as context length increases, the proposed method maintains robust accuracy even at the maximum tested lengths. This indicates that the training recipe successfully scales retrieval and reasoning abilities without compromising short-context performance. The proposed model achieves substantial gains over the base model on long-context benchmarks, particularly at the longest sequence lengths. Short-context performance remains stable or improves slightly, demonstrating that long-context alignment preserves core capabilities. Specific sub-tasks show significant resilience in the proposed model, whereas the base model struggles with retrieval and reasoning at extended lengths.
The authors evaluate their proposed model against the base Qwen3-1.7B model across diverse benchmarks including RULER, multilingual assessments, and tasks ranging from coding to question answering. Results indicate the proposed approach consistently achieves higher average performance with substantial gains in long-context retrieval and reasoning where the base model struggles significantly. While performance varies slightly across specific languages, the method successfully scales long-context capabilities without compromising short-context accuracy or other core competencies.