Command Palette
Search for a command to run...
التباعد الذاتي المضاد للاستدلال المعزز بالتعلم عبر المعلومات المتبادلة النقطية
التباعد الذاتي المضاد للاستدلال المعزز بالتعلم عبر المعلومات المتبادلة النقطية
Guobin Shen Xiang Cheng Chenxiao Zhao Lei Huang Jindong Li Dongcheng Zhao Xing Yu
الملخص
التلخيص الذاتي القائم على السياسة، حيث يُسحب نموذج الطالب نحو نسخة من نفسه مشروطة بسياق مفضل (مثل حل مُتحقق منه أو ملاحظات)، يمثل اتجاهاً واعداً لتعزيز القدرة على الاستدلال دون الحاجة إلى معلم خارجي أقوى. ومع ذلك، فإن المكاسب في الاستدلال الرياضي تكون غير متسقة، حتى عندما ينجح النهج نفسه في مجالات أخرى. تُرجح تحليلات المعلومات المتبادلة النقطية هذا الفشل إلى السياق المفضل نفسه: فهو يبالغ في تقدير ثقة المعلم على الرموز (tokens) التي يفترضها الحل بالفعل (الروابط الهيكلية، والادعاءات القابلة للتحقق)، ويقلل من تقديرها على رموز التأمل (مثل "انتظر"، "لنفترض"، "ربما") التي تقود البحث متعدد الخطوات. نقترح هنا التلخيص الذاتي المعاكس (AntiSD)، الذي يصعد تبايناً بين الطالب والمعلم بدلاً من النزول فيه: وهذا يعكس إشارة الرمز الواحد ويؤدي إلى ميزة محدودة طبيعياً في خطوة واحدة. تقوم بوابة مُفعَّلة بالإنتروبيا بإيقاف هذا الحد بمجرد انهيار إنتروبيا المعلم، مما يكمل استبدالاً مباشراً للتلخيص الذاتي الافتراضي. عبر خمسة نماذج تتراوح بين 4 مليار و30 مليار معلمة على مقاييس الاستدلال الرياضي، يحقق AntiSD دقة أساس GRPO في عدد خطوات تدريب أقل بمقدار 2 إلى 10 أضعاف، ويحسن الدقة النهائية بمقدار يصل إلى 11.5 نقطة. يفتح AntiSD مساراً نحو التحسين الذاتي القابل للتوسع، حيث يستفيد نموذج اللغة من إشارته التدريبية لتعزيز استدلاله الخاص.
One-sentence Summary
The authors propose Anti-Self-Distillation (AntiSD), a reinforcement learning technique that reverses the per-token sign during self-distillation to prioritize deliberation tokens over structural ones, pairing this mechanism with an entropy-triggered gate that disables the term upon entropy collapse to enable five models ranging from 4B to 30B parameters to reach GRPO baseline accuracy in 2 to 10 times fewer training steps while improving final math reasoning accuracy by up to 11.5 points.
Key Contributions
- A pointwise mutual information analysis reveals that standard on-policy self-distillation underperforms on mathematical reasoning because oracle-conditioned teachers overconfidently reinforce structural tokens while suppressing the deliberation tokens required for multi-step search.
- Anti-Self-Distillation (AntiSD) reverses the per-token distillation gradient to preserve exploratory reasoning and integrates an entropy-triggered gate that deactivates the signal once teacher confidence collapses, serving as a drop-in replacement for default self-distillation.
- Evaluations across five models ranging from 4B to 30B parameters demonstrate that AntiSD reaches GRPO baseline accuracy in 2 to 10 times fewer training steps and improves final accuracy by up to 11.5 points on mathematical reasoning benchmarks.
Introduction
Reinforcement learning from verifiable rewards has become the standard for post-training reasoning models, yet sparse trajectory-level signals make it difficult to assign credit to individual reasoning steps. While prior work relies on external process reward models or on-policy distillation, on-policy self-distillation offers a model-free alternative by using the student itself as a teacher under privileged context. The authors note that default self-distillation often fails on complex mathematical reasoning because conditioning the teacher on a verified solution creates an oracle that reinforces hindsight tokens while suppressing necessary deliberation. To resolve this, the authors leverage a gradient inversion strategy that ascends divergence rather than minimizing it, effectively preserving exploratory reasoning steps. Paired with an entropy-triggered gating mechanism, this Anti-Self-Distillation framework serves as a drop-in replacement that accelerates training convergence and delivers substantial accuracy gains across multiple model sizes on challenging math benchmarks.
Method
The authors leverage a framework that rethinks the fundamental gradient direction in on-policy self-distillation for reasoning tasks, particularly in math problem solving. The core idea builds on the observation that standard self-distillation, which minimizes the Kullback-Leibler (KL) divergence between a student policy and a teacher policy conditioned on privileged context, introduces a structural bias that undermines multi-step reasoning. This bias arises because the per-token signal, derived from the difference in log-probabilities between the teacher and student, corresponds to the conditional pointwise mutual information (PMI) between the next token and the privileged context. As shown in the figure below, this signal disproportionately rewards tokens that are implied by the privileged context—such as structural connectives and verifiable claims—and penalizes deliberation tokens—such as "Wait," "Let," or "Maybe"—that are essential for exploring alternative solution paths.
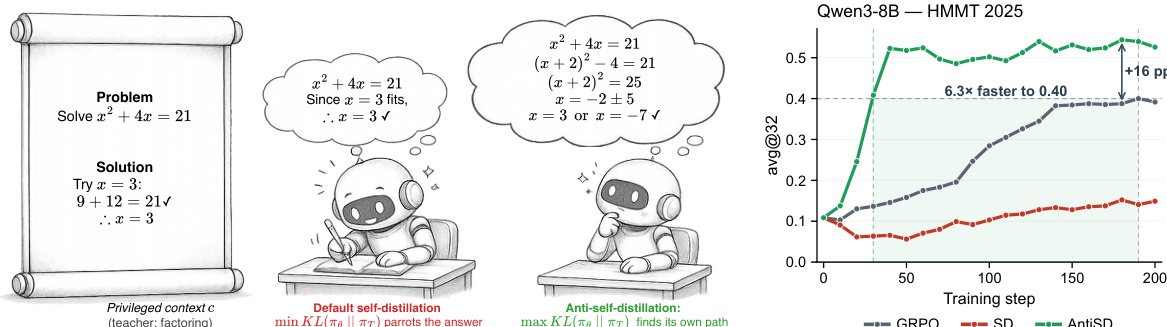
The framework diagram illustrates this phenomenon: under default self-distillation, the student is pulled toward the teacher's confidence, which is inflated on tokens already entailed by the solution, effectively shortening the reasoning trace. In contrast, the proposed Anti-Self-Distillation (AntiSD) method reverses this gradient direction by ascending the Jensen-Shannon (JS) divergence between the student and teacher distributions. This inversion naturally flips the sign of the per-token reward, thereby encouraging the student to explore deliberation tokens and avoid premature convergence to shortcut solutions. The JS divergence provides an intrinsic upper bound on the gradient magnitude, which stabilizes training and eliminates the need for manual scaling. A key component of the method is an entropy-triggered gate that dynamically disables the AntiSD term once the teacher's per-token entropy collapses, ensuring the method remains robust and operates as a drop-in replacement for standard self-distillation. This design enables faster convergence and higher final accuracy across models ranging from 4B to 30B parameters on math reasoning benchmarks, as demonstrated by the performance curves in the graph.
Experiment
The evaluation trains multiple language models on mathematical and coding reasoning tasks to compare AntiSD against standard GRPO and default self-distillation across varying scales. Main results and ablation studies validate that AntiSD’s inverted per-token reward accelerates convergence, sustains generation diversity, and prevents the entropy collapse inherent in conventional self-distillation. Supplementary experiments further confirm that an adaptive entropy gate stabilizes training dynamics while enabling the method to effectively refine already-saturated policies. Ultimately, AntiSD consistently surpasses baseline approaches by rewarding deliberative token generation and delivering robust optimization stability across diverse model architectures.
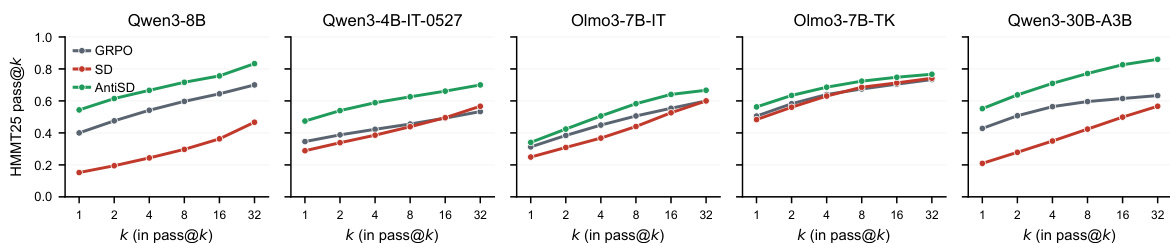
The authors compare AntiSD, a method that inverts the gradient direction of self-distillation to avoid shortcut bias, against GRPO and default self-distillation across multiple language models. Results show that AntiSD achieves higher accuracy than GRPO in fewer training steps and significantly outperforms default self-distillation, which fails to converge on most models. The method's effectiveness is consistent across model sizes and benchmarks, with gains sustained even when applied as a refinement to a saturated GRPO checkpoint. AntiSD achieves higher accuracy than GRPO in fewer training steps across all models, with speedups ranging from 2× to 10×. Default self-distillation underperforms GRPO on every model, often failing to converge, while AntiSD consistently improves performance. AntiSD's gains are sustained across benchmarks and remain effective even when applied as a refinement to a saturated GRPO model.
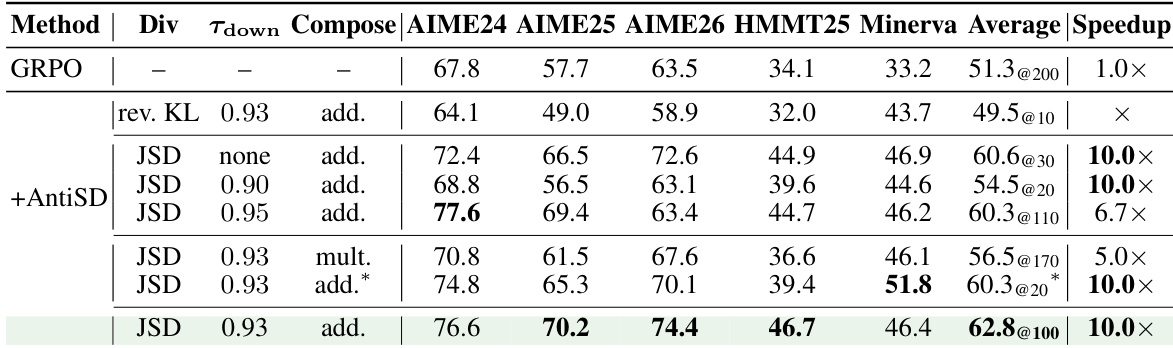
The authors compare AntiSD with GRPO and default self-distillation across multiple language models, showing that AntiSD achieves higher accuracy than GRPO in fewer training steps and outperforms default self-distillation significantly. AntiSD maintains a consistent performance lead across different numbers of rollouts, indicating sustained problem-solving ability without sacrificing diversity. The results demonstrate that AntiSD's advantage is stable across model sizes and can be applied as a refinement to an existing GRPO checkpoint. AntiSD reaches higher accuracy than GRPO in a fraction of the training steps and improves final performance on all models. AntiSD maintains its lead over GRPO across varying numbers of rollouts, indicating sustained problem-solving capability without loss of diversity. AntiSD's gains are robust and can be applied as a refinement to an already-trained GRPO model, improving performance further.
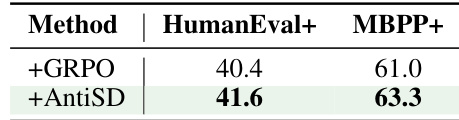
The authors evaluate the performance of AntiSD on code reasoning tasks using two benchmarks, HumanEval+ and MBPP+, and compare it to the GRPO baseline. Results show that AntiSD achieves higher accuracy than GRPO on both benchmarks, with improvements observed across the board. The gains are smaller than those seen in math reasoning but remain consistent in direction, indicating that the method transfers to code generation settings where trajectory-level rewards are denser. AntiSD improves over the GRPO baseline on both HumanEval+ and MBPP+ benchmarks. The performance gains on code reasoning are smaller than those observed in math reasoning but are consistent in direction. AntiSD's advantage extends to code generation, suggesting the method generalizes beyond mathematical problem solving.
{"summary": "The authors compare several training methods on language models, focusing on AntiSD, a variant that uses a sign-reversed reward signal and an entropy-triggered gate to avoid the failure modes of default self-distillation. Results show that AntiSD achieves higher accuracy than GRPO and default self-distillation across all models, reaching GRPO's performance in fewer training steps and maintaining gains even when applied to a saturated GRPO checkpoint. The method improves both speed and final accuracy while preserving rollout diversity, and its effectiveness is supported by stable training dynamics and ablation studies that highlight the importance of the privileged context and gate mechanism.", "highlights": ["AntiSD achieves higher accuracy than GRPO and default self-distillation across all models while reaching GRPO's performance in fewer training steps.", "AntiSD preserves rollout diversity, as shown by sustained pass@k gains across multiple attempts, indicating genuine problem-solving rather than mode collapse.", "The method's success depends on the privileged context and an entropy-triggered gate, with ablations showing that removing these components leads to training failure or reduced performance."]
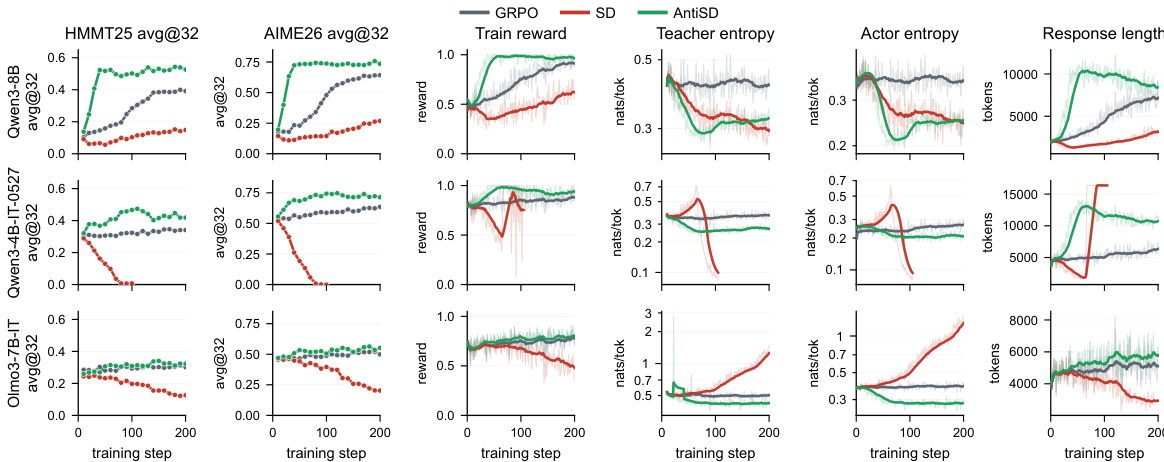
The authors compare AntiSD against GRPO and default self-distillation across multiple language models, showing that AntiSD achieves higher accuracy and faster convergence. Results demonstrate that AntiSD reaches GRPO's peak performance in fewer steps and consistently outperforms it in final accuracy, with the largest gains on smaller models. Default self-distillation underperforms GRPO on all models, indicating a failure due to biased optimization. AntiSD achieves higher accuracy and faster convergence compared to GRPO, with speedups of up to 10 times on smaller models. AntiSD consistently outperforms GRPO in final accuracy, with gains ranging from 2.1 to 11.5 points across all models. Default self-distillation underperforms GRPO on every model, highlighting a failure in optimization due to biased reward signals.
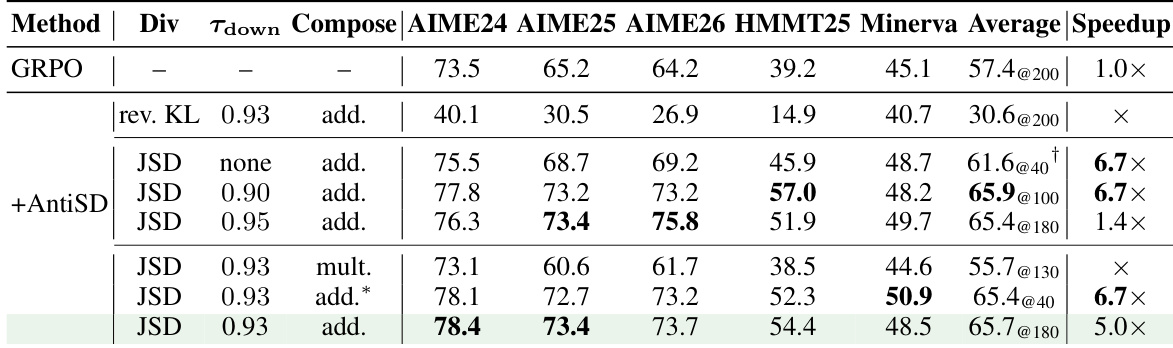
The experiments evaluate AntiSD against GRPO and default self-distillation across multiple language models and reasoning benchmarks to validate training efficiency, final accuracy, and cross-task generalization. Results show that AntiSD converges significantly faster while achieving higher accuracy, successfully circumventing the shortcut bias and optimization failures inherent in default self-distillation. The method maintains robust performance across varying model sizes, rollout configurations, and code generation tasks, demonstrating its capacity to preserve rollout diversity and serve as a reliable refinement for existing checkpoints. Ablation studies further validate that these improvements depend on a privileged context mechanism and an entropy-triggered gate to ensure stable learning dynamics.