Command Palette
Search for a command to run...
إزالة الغموض عن YOLOv11: دليل عملي للكشف عن الأجسام عالي الأداء
إزالة الغموض عن YOLOv11: دليل عملي للكشف عن الأجسام عالي الأداء
Nikhileswara Rao Sulake
نشر YOLOv11 بنقرة واحدة
الملخص
YOLOv11 هو أحدث إصدار في سلسلة YOLO (You Only Look Once) للكاشفات عن الأجسام في الزمن الحقيقي، حيث يقدم وحدات معمارية جديدة لتحسين استخراج الميزات وكشف الأجسام الصغيرة. في هذه الورقة، نقدم تحليلاً مفصلاً لـ YOLOv11، بما في ذلك مكونات العمود الفقري (backbone)، والرقبة (neck)، والرأس (head). تعزز الابتكارات الرئيسية للنموذج، وهي كتل C3K2، وتجميع الهرم المكاني السريع (SPPF)، ووحدات C2PSA (المرحلة الجزئية عبر المراحل مع الانتباه المكاني)، معالجة الميزات المكانية مع الحفاظ على السرعة. نقارن أداء YOLOv11 مع الإصدارات السابقة من YOLO على معايير قياسية، مسلطين الضوء على التحسينات في متوسط الدقة المتوسطة (mAP) وسرعة الاستدلال. تُظهر نتائجنا أن YOLOv11 يحقق دقة متفوقة دون التضحية بالقدرة على العمل في الزمن الحقيقي، مما يجعله مناسبًا جيدًا للتطبيقات في القيادة الذاتية، والمراقبة، وتحليل الفيديو. تؤطر هذه الورقة YOLOv11 في سياق بحثي، وتوفر مرجعًا واضحًا للدراسات المستقبلية.
One-sentence Summary
This paper presents a detailed architectural analysis of YOLOv11, demonstrating how its C3K2 blocks, Spatial Pyramid Pooling - Fast (SPPF), and C2PSA modules enhance spatial feature extraction and small-object detection while preserving real-time inference speeds, as benchmark comparisons against prior YOLO versions confirm improvements in mean Average Precision (mAP) and position the model as a practical reference for autonomous driving, surveillance, and video analytics.
Key Contributions
- This work formalizes the YOLOv11 architecture by systematically detailing its backbone, neck, and head components to establish a clear reference for future research.
- The study examines three core structural innovations, specifically the C3K2 blocks, Spatial Pyramid Pooling-Fast (SPPF) module, and C2PSA attention mechanism, which enhance spatial feature processing and small-object detection.
- Benchmark evaluations on COCO demonstrate that the refined design achieves higher mean Average Precision (mAP) with a 22% parameter reduction compared to prior iterations while preserving real-time inference capabilities.
Introduction
Object detection remains a foundational computer vision task where balancing high accuracy with low latency is critical for real-world deployment. While the YOLO family has consistently advanced single-pass detection, earlier iterations still struggled to efficiently capture small or occluded objects without compromising inference speed. To address these limitations, the authors introduce YOLOv11, which leverages C3K2 blocks, an optimized Spatial Pyramid Pooling Fast module, and a C2PSA partial spatial attention mechanism. These architectural enhancements strengthen feature extraction and small-object localization, delivering higher mean average precision with fewer parameters while preserving the real-time performance that defines the YOLO lineage.
Method
The authors leverage a modular, backbone-neck-head architecture in YOLOv11, which follows the standard design of single-shot object detectors while introducing several novel components to enhance feature extraction and detection performance. The overall framework is structured into three primary components: a backbone for feature extraction, a neck for multi-scale feature aggregation, and a detection head for predicting object locations and classes. Refer to the framework diagram for an overview of the complete architecture.
The backbone of YOLOv11 is responsible for extracting hierarchical features from the input image. It begins with a focus layer followed by a sequence of convolutional and residual-like blocks. The basic building block consists of a Conv2D layer, Batch Normalization, and an activation function. The model employs the SiLU activation function, which is known for its smoothness and non-monotonic properties, offering advantages over traditional ReLU-like activations. The backbone incorporates Bottleneck blocks, similar to those in ResNet, which use identity shortcuts to mitigate gradient degradation in deeper networks. These blocks process features through a series of convolutions and include a residual connection that adds the input to the output of the block. This design enables the construction of deeper networks without performance degradation.
A key innovation in the backbone is the C3K2 block, which is an evolution of the Cross Stage Partial (CSP) bottleneck introduced in earlier YOLO versions. The C3K2 block optimizes information flow by splitting the feature map and applying a series of smaller 3×3 convolutions, which are computationally efficient while preserving essential features. This block is composed of two initial Conv blocks, followed by a series of C3K blocks, and concludes with a final Conv block. The C3K block itself does not split the input but processes the entire feature map through a series of bottleneck layers with concatenations. The C3K2 block combines the C3K structure with the C2F design, where the output of the final C3K block is concatenated with the output of the initial Conv block before the final Conv layer. This structure maintains a balance between computational efficiency and accuracy, building on the CSP framework to reduce redundancy and improve gradient flow. Figure 1 illustrates the full backbone structure, showing the progression of stages with C2F, C3K2, and Conv blocks at progressively lower resolutions, designed to balance accuracy and speed.
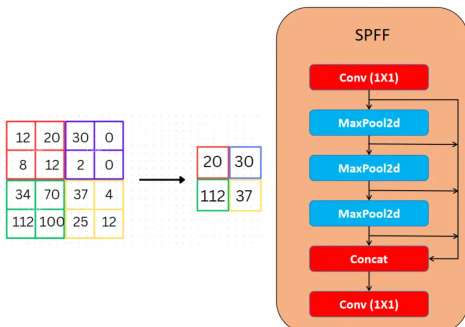
The neck of the network is designed for multi-scale feature aggregation, combining features from different backbone stages to enable detection at various scales. YOLOv11 employs an improved Spatial Pyramid Pooling - Fast (SPPF) module, which applies multiple parallel max-pooling operations with different kernel sizes to the same feature map. This captures contextual information at multiple scales, which is crucial for detecting both small and large objects. The SPPF module is followed by concatenation and additional convolutions to fuse the pooled features. This "Fast" variant reduces latency compared to the original SPP by streamlining the pooling operations. After SPPF, the network uses upsampling and concatenation to merge features from different backbone stages, forming a path similar to PANet. This combination ensures that both fine-grained details from early layers and high-level semantic information from deeper layers are effectively utilized. As shown in the figure below, the SPPF block processes the feature map through multiple max-pooling layers with different kernel sizes and then concatenates the results.
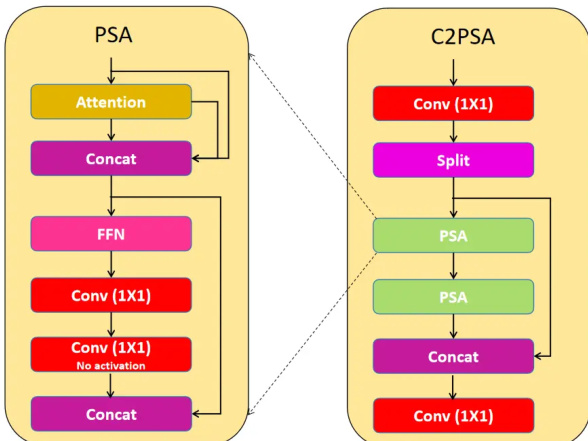
One of the significant innovations in YOLOv11 is the C2PSA block, which introduces lightweight attention mechanisms to enhance the model's focus on important regions within an image. This block combines the Cross Stage Partial (CSP) structure with a Partial Spatial Attention (PSA) module. The PSA layer computes spatial attention maps that highlight salient regions, allowing the network to emphasize features from small or partially occluded objects. The C2PSA block uses two PSA modules operating on separate branches of the feature map, which are then concatenated in a manner similar to the C2F block structure. This setup ensures that spatial information is emphasized while maintaining a balance between computational cost and detection accuracy. The C2PSA block refines the model's ability to selectively focus on regions of interest by applying spatial attention over the extracted features. This allows the network to allocate more capacity to challenging areas, improving accuracy on small and occluded objects. The architecture diagram of the C2PSA block is shown below.
The detection head processes the aggregated features from the neck to generate final predictions for object locations, classes, and confidence scores. It consists of a series of Conv blocks and detection modules that output predictions at multiple scales, enabling the model to detect objects of various sizes. The overall architecture is designed to maintain real-time inference speed while achieving high accuracy, making it suitable for applications such as autonomous driving and surveillance.
Experiment
The evaluation setup encompasses qualitative inference on diverse imagery and video, cross-device benchmarking on CPU and GPU, and comparative testing against prior YOLO versions and state-of-the-art models using the COCO dataset. These experiments validate the model's robust localization and classification capabilities under occlusion and scale variation, while confirming its real-time viability through substantially reduced GPU inference latency. Ultimately, the findings indicate that YOLOv11 delivers a superior accuracy-efficiency balance compared to previous iterations and competing architectures, driven by its refined structural enhancements.
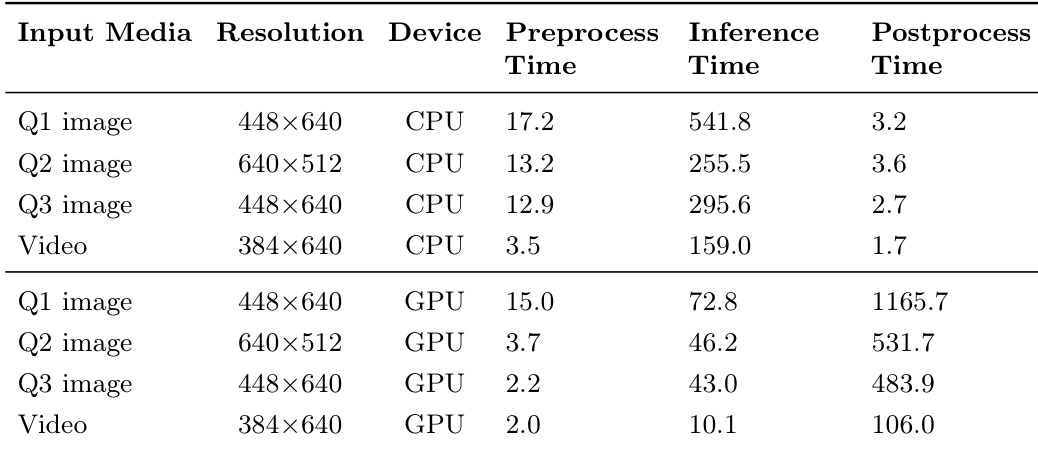
The authors evaluate YOLOv11's inference performance across different input types and devices, comparing CPU and GPU execution times for preprocessing, inference, and postprocessing. The results show that GPU acceleration significantly reduces inference time, while postprocessing time is higher on GPU due to increased resolution and I/O overhead. GPU inference reduces latency compared to CPU, with faster processing for all input types. Postprocessing time is higher on GPU, particularly for higher-resolution inputs. Inference time decreases significantly with GPU, while preprocessing and postprocessing times vary by input resolution and device.
The authors compare YOLOv11 with prior YOLO versions using standard metrics such as mAP and inference speed across CPU and GPU configurations. Results show that YOLOv11 achieves higher accuracy and faster inference compared to earlier models, with notable improvements in the balance between performance and computational efficiency. YOLOv11 achieves higher mAP than previous YOLO versions while maintaining faster inference speeds on both CPU and GPU. YOLOv11 variants demonstrate improved accuracy-efficiency trade-offs, particularly in real-time deployment scenarios. The model's performance gains are attributed to architectural enhancements, leading to better detection capabilities under various conditions.
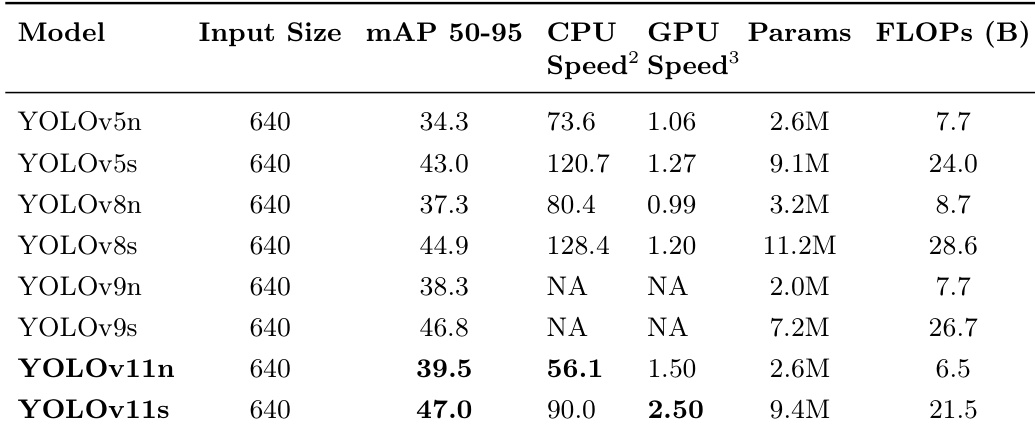
The authors evaluate YOLOv11 across CPU and GPU devices with varying input resolutions to assess hardware acceleration impacts and benchmark its performance against previous YOLO iterations. The experiments validate that GPU deployment substantially reduces inference latency, despite increased postprocessing overhead at higher resolutions. Overall, YOLOv11 demonstrates superior accuracy and faster processing compared to earlier models, establishing a more favorable balance between computational efficiency and detection performance for real-time applications.