Command Palette
Search for a command to run...
Please provide the title you would like me to translate.
Please provide the title you would like me to translate.
نشر بي-تورش غراد-كام بضغطة واحدة: الذكاء الاصطناعي القابل للتفسير للرؤية الحاسوبية
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
Drawing on user interviews and contemporary research, the authors propose a research agenda for accessible explainable AI that addresses the modality gap for blind and low-vision users by advocating for multimodal, blame-aware conversational explanations and participatory development to mitigate self-blame and foster trust in autonomous, multi-step agentic systems.
Key Contributions
- This paper establishes a framework of explainable AI requirements for blind and low-vision users by synthesizing qualitative interview data with contemporary accessibility research.
- The analysis identifies a modality gap in current systems and documents how users navigate environmental perception and decision support tasks through non-visual verification and conversational interaction patterns.
- Empirical findings reveal a preference for conversational explanations alongside a "self-blame" phenomenon during AI failures, directly informing a research agenda for multimodal interfaces and blame-aware explanation design in agentic systems.
Introduction
The authors examine the critical need for accessible Explainable AI as autonomous systems transition from single-query tools to multi-step agentic workflows that execute complex, long-horizon tasks. This context matters because blind and low-vision users currently face a fundamental barrier to independent technology use when explanation interfaces remain exclusively visual. Prior work largely depends on visual attribution methods like heatmaps and fails to expose the underlying reasoning traces of agentic pipelines, which forces users to rely on inefficient manual workarounds and frequently triggers misplaced self-blame when systems hallucinate or err. To bridge this gap, the authors synthesize user interviews and contemporary research to map the distinct trust calibration and modality preferences of the BLV community. They deliver a structured research agenda that advocates for multimodal interfaces, blame-aware explanation frameworks, and participatory design to ensure future agentic AI systems remain transparent, accountable, and fully accessible.
Dataset
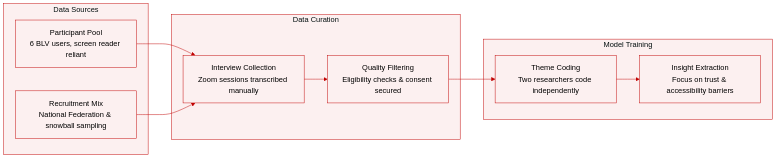
-
Dataset Composition and Sources: The authors compiled a qualitative dataset of semi-structured interview transcripts collected from six blind and low vision participants. Recruitment was conducted through the National Federation of the Blind, with additional participants sourced via snowball sampling.
-
Key Subset Details and Filtering Rules: The collection contains a single cohort of six users. Eligibility required US residency, age 18 or older, primary reliance on screen readers, English fluency, and prior experience with generative AI tools. The final group includes five female and one male participant spanning ages 18 to 60 and above.
-
Data Usage and Processing: The authors apply these transcripts to qualitative research on explainable AI, user trust, and accessibility barriers. Traditional training splits and mixture ratios do not apply to this collection. Instead, the data undergoes reflexive thematic analysis where two researchers independently code the interviews and hold weekly meetings to align on emerging themes and resolve coding discrepancies.
-
Additional Processing and Metadata Details: All sessions were conducted remotely via Zoom, video recorded with informed consent, and converted to text transcripts. Participants received a thirty dollar Amazon gift card as compensation. The study does not employ cropping strategies or automated metadata construction, relying instead on manual transcription and iterative thematic coding to extract insights about conversational interfaces and progressive disclosure.
Method
The authors leverage a user-centered approach to analyze verification strategies in non-visual AI systems, where users lack direct visual access to validate model outputs. In such environments, participants develop proxy strategies to infer truth through indirect means, relying on deterministic data sources or redundant inputs to compensate for the probabilistic nature of computer vision models. As shown in the figure below, one such strategy involves using a trusted anchor—such as a barcode—to cross-validate the AI's description. For instance, a user may first scan a barcode and then compare the system’s textual output to the barcode’s content, establishing consistency as a basis for trust. This method transforms a hard-coded, reliable data point into a verification mechanism, allowing users to audit the model’s predictions without visual confirmation.
Another approach observed is the multi-shot strategy, where users manually generate multiple inputs—such as taking several images from different angles—to achieve consensus across predictions. This behavior mimics an ensemble method, where repeated observations reduce the impact of a single erroneous prediction. While effective in lowering risk, this process imposes a significant cognitive and time burden on the user, highlighting a gap in the system’s ability to provide sufficient confidence guarantees autonomously. In high-stakes contexts—such as reading currency or documents—these manual workarounds prove insufficient when the AI’s output remains ambiguous or inconsistent. In such cases, users resort to human fallback, abandoning the automated system entirely to seek external validation. This reliance underscores the limitations of current explainability methods, which fail to deliver standalone, interpretable evidence that enables users to resolve uncertainty independently.
The analysis further reveals that the absence of visual ground truth shifts the central challenge in explainable AI (XAI) from model architecture comprehension to outcome verification. Users often exhibit a self-blame bias, attributing system failures to their own input quality rather than model uncertainty. To address this, the authors argue for a shift in XAI design toward blame-aware interfaces that explicitly signal input quality issues and support functional contestability. Participants demonstrated a strong preference for conversational, back-and-forth interactions, where they can challenge the AI’s confidence and request re-evaluation. This interactive modality allows users to demand non-visual evidence and question the system’s logic, thereby reducing the need for human fallback. In agentic systems, where decisions can lead to irreversible actions, such interaction becomes critical. The ability to perform step-level attribution—distinguishing between input quality failures and model errors at each stage—and to require explicit user confirmation before execution enables safer, more transparent agent behavior. The conversational framework, which allows the agent to explain its reasoning and accept follow-up challenges, directly supports this need for accountability and control in non-visual contexts.
Experiment
Qualitative studies with blind and low vision participants reveal how users interact with and evaluate AI reliability across varying task contexts. The experiments validate that trust operates as a risk-calibrated sliding scale, yet is frequently compromised by a self-blame bias where users internalize algorithmic failures as personal execution errors rather than system limitations. Ultimately, the research confirms that conversational, non-visual explanations are essential for resolving uncertainty and mitigating hallucination-driven distrust, underscoring the critical need for interactive design as AI systems assume more autonomous functions.