Command Palette
Search for a command to run...
تقدير عمق الفيديو الحتمي باستخدام مسبقات التوليد
تقدير عمق الفيديو الحتمي باستخدام مسبقات التوليد
دي في دي: تقدير عمق الفيديو الحتمي القائم على المسبقات التوليدية
الملخص
تواجه تقديرات العمق في الفيديو الحالية تحدياً جوهرياً يتمثل في مقايضة صعبة: حيث تعاني النماذج التوليدية من توهمات هندسية عشوائية وانزياح في المقياس، بينما تتطلب النماذج التمييزية مجموعات بيانات ضخمة موسومة لحل الغموض الدلالي. لكسر هذا الجمود، نقدم DVD، وهو الإطار الأول الذي يعيد نمذجة نماذج الانتشار للفيديو (Video Diffusion Models) المدربة مسبقاً بشكل حتمي لتصبح مٌرجعات للعمق في خطوة واحدة. على وجه التحديد، يتميز DVD بثلاثة تصاميم جوهرية: (أ) إعادة توظيف وقت الانتشار (Diffusion timestep) كمرساة هيكلية لتوازن بين الاستقرار العام والتفاصيل عالية التردد؛ (ب) تصحيح المتشعب الخفي (Latent Manifold Rectification - LMR) للتخفيف من التسطيح المفرط الناتج عن الانحدار، وفرض قيود تفاضلية لاستعادة الحواف الحادة والحركة المتماسكة؛ و(ج) الاتساق الإسقاطي العالمي، وهي خاصية جوهرية تحدّ من الانحراف بين النوافذ، مما يتيح الاستدلال على الفيديوهات طويلة المدى بسلاسة دون الحاجة إلى محاذاة زمنية معقدة. تُظهر التجارب الشاملة أن DVD يحقق أداءً رائداً (State-of-the-art) في وضع الصفرية (Zero-shot) عبر مجموعات الاختبار. وعلاوة على ذلك، يفتح DVD بنجاح الباب للاستفادة من الأفضليات الهندسية الضمنية الكامنة في نماذج الأساس للفيديو، باستخدام بيانات خاصة بالمهمة أقل بنسبة 163 مرة من النماذج الأساسية الرائدة. ومن الجدير بالذكر أننا نوفر بشكل كامل الـ Pipeline الخاص بنا، مقدمين مجموعة التدريب الكاملة لتحقيق أفضل أداء في تقديرات عمق الفيديو، مما يعود بالفائدة على مجتمع المصادر المفتوحة.
One-sentence Summary
The authors propose DVD, a framework that deterministically adapts pre-trained video diffusion models into single-pass depth regressors to address stochastic geometric hallucinations and massive labeled dataset requirements through latent manifold rectification and global affine coherence, achieving state-of-the-art zero-shot performance with 163× less task-specific data than leading baselines while unlocking profound geometric priors.
Key Contributions
- DVD is the first framework to deterministically adapt pre-trained video diffusion models into single-pass depth regressors. This approach bypasses stochastic sampling to resolve the ambiguity-hallucination dilemma while uniting semantic richness with structural stability.
- Three core designs include repurposing the diffusion timestep as a structural anchor and employing latent manifold rectification to enforce differential constraints on motion. Global affine coherence enables seamless long-video inference without requiring complex temporal alignment.
- Extensive experiments demonstrate state-of-the-art zero-shot performance across benchmarks using 163× less task-specific data than leading baselines. The complete training pipeline is fully released to benefit the open-source community.
Introduction
Video depth estimation serves as a foundational component for 3D scene understanding in fields ranging from autonomous driving to robotic manipulation. Current approaches face a fundamental trade-off where generative models suffer from stochastic geometric hallucinations and discriminative models demand massive labeled datasets to resolve semantic ambiguities. The authors introduce DVD, the first framework to deterministically adapt pre-trained video diffusion models into single-pass depth regressors. This approach leverages a timestep structural anchor and latent manifold rectification to balance global stability with high-frequency details, enabling state-of-the-art zero-shot performance with 163 times less task-specific data than leading baselines.
Method
The authors propose a novel framework for video depth estimation that bridges the gap between generative priors and deterministic stability. The method operates within a compressed latent manifold to leverage the rich semantic knowledge of large-scale pre-trained models while ensuring geometric consistency.
The overall pipeline begins by formalizing video depth estimation as a mapping from an input RGB sequence x∈RF×3×H×W to a depth sequence d∈RF×H×W. To exploit pre-trained capabilities, a frozen variational autoencoder (VAE) encoder E projects both RGB and depth data into a unified latent space, defined as zx=E(x) and zd=E(d). The core objective is to learn a deterministic mapping Φ:zx↦zd that recovers geometric structure directly in this latent space, with the final depth reconstructed via a frozen VAE decoder.
Refer to the framework diagram for a visualization of the complete architecture, which encompasses both the training adaptation and the long-video inference stages.
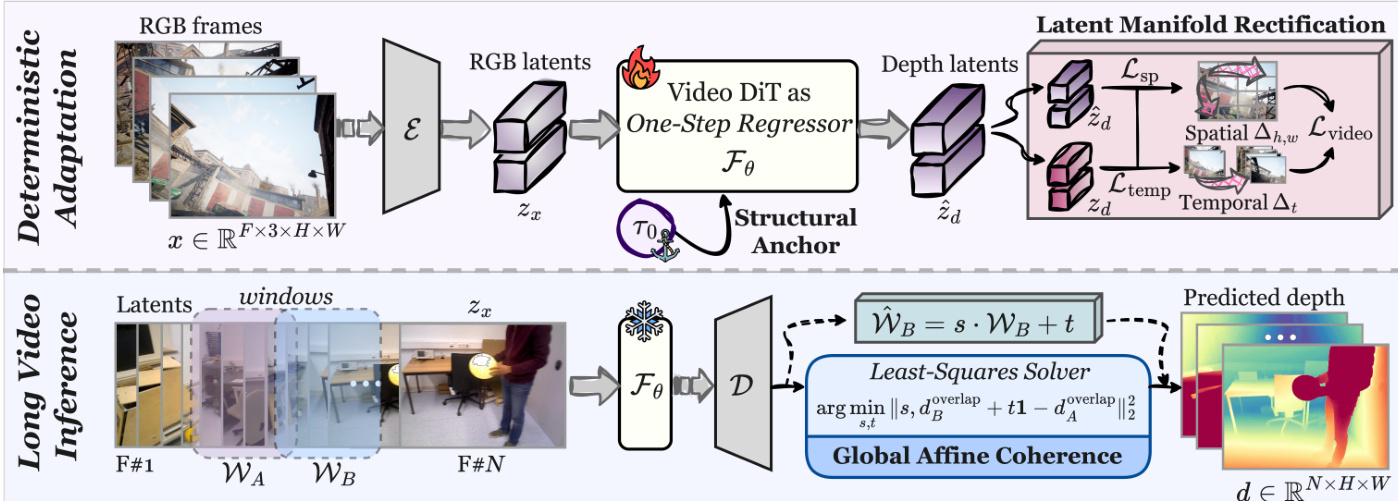
In the deterministic adaptation phase, the authors repurpose a pre-trained Video Diffusion Transformer (Video DiT) as a one-step regressor rather than performing iterative stochastic denoising. Instead of solving an ordinary differential equation over a noise trajectory, the network Fθ performs a direct functional mapping z^d=Fθ(zx,τ) in a single forward pass. A critical design choice involves the conditioning timestep τ. Unlike standard diffusion models where t parameterizes noise levels during generation, the authors leverage τ as a structural anchor. By fixing the timestep to an optimal state τ0 via a sinusoidal embedding, the model is calibrated to a specific geometric operating regime. This frequency-parameterized conditioning balances low-frequency global stability with high-frequency local detail recovery, preventing the over-smoothing often observed when adapting diffusion backbones to deterministic tasks.
To address the issue of mean collapse inherent in regression-based training, the framework introduces Latent Manifold Rectification (LMR). Standard point-wise losses tend to drive predictions toward the conditional expectation, washing out high-frequency structural details and causing temporal flickering. LMR counteracts this by enforcing differential consistency in the latent space without requiring auxiliary modules. The supervision strategy aligns the spatial gradients and temporal flows of the predicted latents with the ground truth. The spatial rectification loss Lsp penalizes low-frequency collapse to preserve sharp boundaries, while the temporal rectification loss Ltemp synchronizes inter-frame dynamics to ensure coherent motion. These terms are combined with a global L2 loss to form the total video objective, effectively preserving latent high-frequency structures against the smoothing effects of deterministic regression.
For long-duration video inference, memory constraints necessitate a sliding-window approach. While the deterministic backbone eliminates stochastic scale drift, the VAE decoder's context-dependent normalization can still induce fluctuations in depth values across windows. To resolve this, the authors exploit an inherent property of global affine coherence, observing that inter-window discrepancies can be approximated by linear scale-shift transformations. During inference, the system employs a Least-Squares Solver to estimate a global scale s and shift t based on the overlap between adjacent windows. This affine calibration is broadcast to the entire current window, allowing for seamless blending of overlapping frames. This strategy enables robust, flicker-free depth estimation for long videos without requiring complex feature matching or recurrent temporal modules. Finally, the model is optimized via an image-video joint training strategy, where static images act as high-frequency spatial anchors while video sequences enforce temporal coherence, ensuring both spatial sharpness and temporal stability.
Experiment
The evaluation utilizes standard video and image depth benchmarks to compare the proposed DVD method against state-of-the-art generative and discriminative baselines across tasks involving temporal consistency, boundary accuracy, and single-image generalization. Results indicate that DVD achieves superior geometric fidelity and long-term temporal coherence while maintaining competitive inference speeds and requiring significantly less training data than comparable generative models. Further analysis confirms that deterministic adaptation and joint image-video training are critical for preventing geometric hallucinations and ensuring robust scalability across diverse open-world scenes.
The authors compare their DVD method against ChronoDepth, DepthCrafter, and VDA across KITTI, DIODE, and NYUv2 datasets. Results indicate that DVD achieves the best performance on KITTI and DIODE, outperforming both discriminative and generative baselines. On the NYUv2 dataset, the method demonstrates competitive accuracy, closely trailing the top-performing VDA while significantly surpassing other approaches. DVD achieves the highest accuracy on KITTI and DIODE benchmarks compared to all listed baselines. The proposed method significantly outperforms generative models like DepthCrafter across all evaluated datasets. DVD demonstrates robust single-image generalization, performing competitively against the strong VDA baseline on NYUv2.

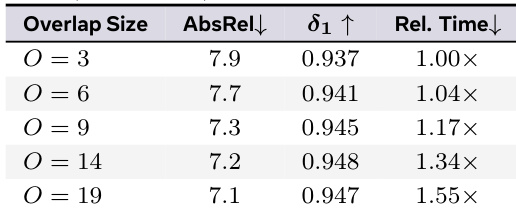
The authors analyze the impact of overlap size on model performance and efficiency. Results indicate that increasing the overlap size consistently improves geometric accuracy and threshold metrics. However, this enhancement in quality is accompanied by a significant increase in relative inference time. Absolute relative error decreases as overlap size increases. Threshold accuracy improves with larger overlap configurations. Relative inference time rises steadily with larger overlap settings.
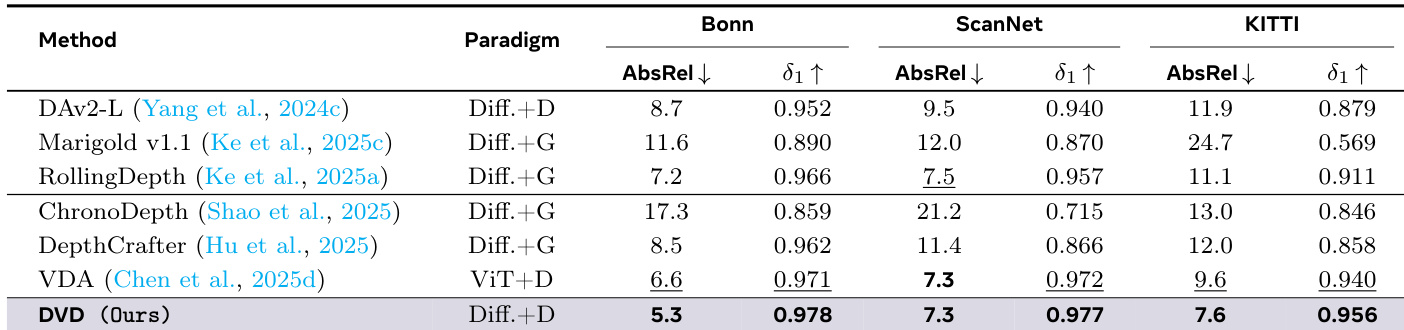
The authors evaluate DVD against state-of-the-art video depth estimation methods across standard benchmarks including Bonn, ScanNet, and KITTI. Results show that DVD consistently achieves superior geometric fidelity and temporal coherence compared to both generative and discriminative baselines. The method demonstrates significant efficiency gains by utilizing deterministic adaptation instead of iterative sampling. DVD achieves top-tier accuracy across all tested datasets, outperforming methods like DepthCrafter and VDA. The deterministic adaptation approach bypasses the computational bottlenecks associated with iterative generative sampling. Joint image-video training ensures the model retains high spatial precision while maintaining temporal consistency.
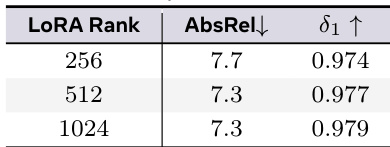
The the the table presents an ablation study evaluating the impact of LoRA rank on model performance. Results show that increasing the rank from the lowest setting significantly reduces error and improves accuracy metrics. However, moving from the medium to the highest rank yields diminishing returns, suggesting a moderate rank is sufficient for optimal performance. Increasing the LoRA rank leads to consistent improvements in error reduction and accuracy. Performance stabilizes at the medium rank, with the highest rank offering negligible additional benefits. The lowest rank setting demonstrates the weakest performance across all measured metrics.
The authors evaluate their DVD method against state-of-the-art video and image depth estimation baselines across multiple standard benchmarks. The results demonstrate that DVD achieves superior geometric fidelity and temporal coherence, consistently outperforming both generative and discriminative approaches on most metrics. Notably, the model attains these leading results while utilizing a significantly smaller training dataset compared to massive-scale competitors. DVD achieves the lowest absolute relative error on KITTI, ScanNet, and Bonn datasets. The method achieves the highest threshold accuracy across all four evaluated datasets. DVD demonstrates high data efficiency, achieving top results with a training set size much smaller than that of the VDA baseline.
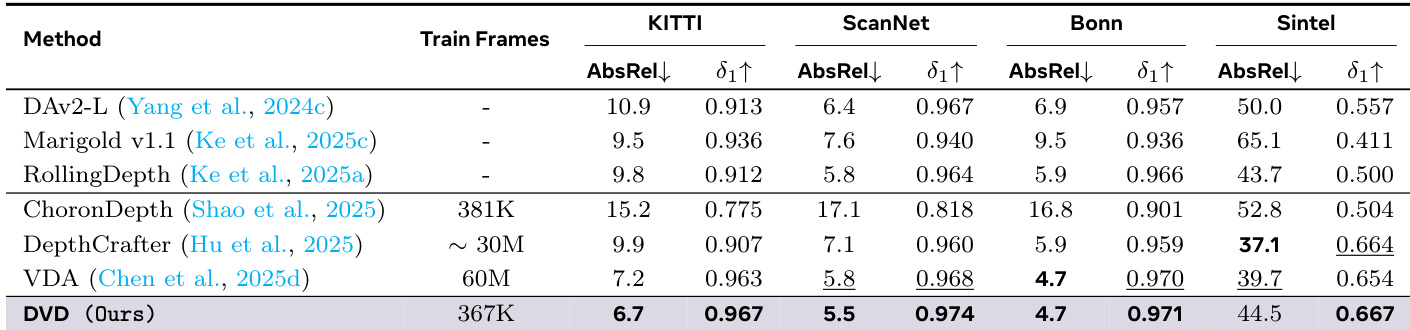
The DVD method is evaluated against state-of-the-art discriminative and generative baselines across multiple standard datasets to assess geometric fidelity and temporal coherence. Results indicate that DVD consistently outperforms competitors in accuracy and efficiency, achieving top-tier performance even with a significantly smaller training dataset. Additional experiments validate that increasing overlap size enhances accuracy at the cost of inference time, while a moderate LoRA rank provides optimal performance without diminishing returns.