Command Palette
Search for a command to run...
إطار عمل vLLM الإصدار صفر: ملحق لنماذج البرمجة الداخلية في vLLM
إطار عمل vLLM الإصدار صفر: ملحق لنماذج البرمجة الداخلية في vLLM
Ching-Yun Ko Pin-Yu Chen
نشر Gemma-3-27B-IT باستخدام vLLM
الملخص
النماذج الحديثة للذكاء الاصطناعي (AI) تُنشر على محركات الاستدلال (inference engines) لتحسين كفاءة وقت التشغيل وتخصيص الموارد، ولا سيما النماذج اللغوية الكبيرة (LLMs) القائمة على معمارية المحولات (transformers). يُعد مشروع vLLM مكتبة مفتوحة المصدر رئيسية لدعم خدمة النماذج والاستدلال. ومع ذلك، فإن التنفيذ الحالي لـ vLLM يحد من قابلية برمجة الحالات الداخلية للنماذج المنشرة. وهذا يمنع استخدام طرق مواءمة وتحسين النماذج الشائعة أثناء وقت الاختبار (test-time). على سبيل المثال، فإنه يمنع اكتشاف المطالبات المعادية (adversarial prompts) بناءً على أنماط الانتباه (attention patterns)، أو تعديل استجابات النموذج بناءً على التوجيه التنشيطي (activation steering). لسد هذه الفجوة الحرجة، نقدم vLLM Hook، وهو ملحق مفتوح المصدر لتمكين برمجة الحالات الداخلية لنماذج vLLM. وبناءً على ملف تكوين يحدد الحالات الداخلية المراد التقاطها، يوفر vLLM Hook تكاملاً سلساً مع vLLM ويدعم ميزتين أساسيتين: البرمجة السلبية والبرمجة النشطة. بالنسبة للبرمجة السلبية، يقوم vLLM Hook بفحص الحالات الداخلية المحددة للتحليل اللاحق، مع الحفاظ على عملية توليد النموذج دون تغيير. أما بالنسبة للبرمجة النشطة، فيُمكّن vLLM Hook من التدخل الفعال في توليد النموذج من خلال تعديل الحالات الداخلية المحددة.
One-sentence Summary
The authors present vLLM Hook, an open-source plug-in for the vLLM inference engine that enables configurable programming of internal model states through passive probing and active intervention, thereby overcoming existing programmability constraints to support test-time alignment, adversarial prompt detection, and activation steering for large language models.
Key Contributions
- vLLM Hook is an open-source plugin that enables configuration-driven programming of internal states within the vLLM inference engine, directly addressing the limitation that restricts test-time model alignment and enhancement methods.
- The system implements two core programming modes, passive programming for non-intrusive state probing that preserves generation, and active programming for real-time intervention via the alteration of selected internal states.
- Three practical demonstrations validate the plugin, showcasing prompt injection detection, enhanced retrieval-augmented retrieval, and activation steering to verify its utility for runtime model monitoring and adjustment.
Introduction
Modern large language models rely on inference engines like vLLM to optimize deployment efficiency and resource allocation. However, the current vLLM implementation restricts access to and modification of internal model states during inference, which blocks essential test-time alignment techniques such as adversarial prompt detection and activation steering. To address this limitation, the authors develop vLLM Hook, an open-source plug-in that enables precise programming of internal states through a simple configuration file. The framework supports passive probing for real-time analysis and active intervention to directly alter model outputs, effectively unlocking practical applications like enhanced retrieval-augmented generation and secure prompt monitoring.
Dataset
- The authors do not provide a dataset description in the submitted text.
- Dataset composition and sources: The content only outlines a GitHub contribution workflow and references a repository URL. No data sources or composition details are included.
- Key details for each subset: The text contains no information regarding subset sizes, origins, or filtering criteria.
- How the paper uses the data: No training splits, mixture ratios, or data processing steps are described.
- Cropping strategy, metadata construction, or other processing details: None are mentioned in the provided material.
Method
The vLLM-Hook framework is designed as a modular plugin system that enables both passive and active programming within the vLLM inference pipeline. At its core, the framework operates through two primary abstractions: the worker and the analyzer, which are orchestrated by a configuration file that defines the behavior of each component. The worker integrates directly into the vLLM runtime and is responsible for either capturing internal model states during inference (passive programming) or modifying the model's behavior in real time (active programming). This integration is achieved by subclassing the standard vLLM GPU worker and overriding the load_model method to install PyTorch forward hooks on selected model modules. These hooks are applied to specific attention layers and heads, as specified in the configuration, allowing for targeted observation or intervention during the forward pass.
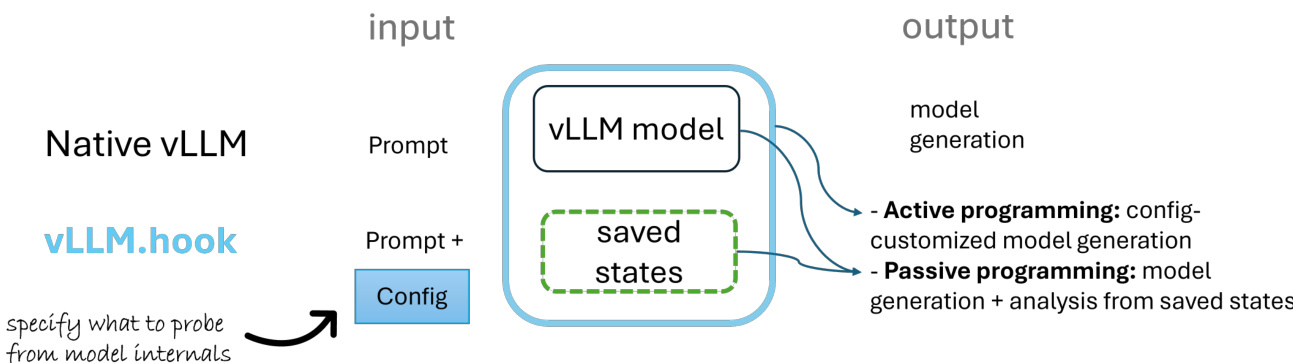
As shown in the figure below, the framework begins with a native vLLM system that receives an input prompt. The user specifies the components to probe via a configuration file, which is then used to guide the vLLM-Hook system. The system captures internal states during inference, which can be either saved for later analysis or used to enable active programming, such as model steering or customized generation. The configuration file defines the model identity, important layers and attention heads, and the mode of signal capture—such as whether to collect data for all tokens or only the last token. These configurations are managed through a lightweight registry and a HookLLM wrapper class that initializes the LLM instance and interfaces with the core vLLM engine.
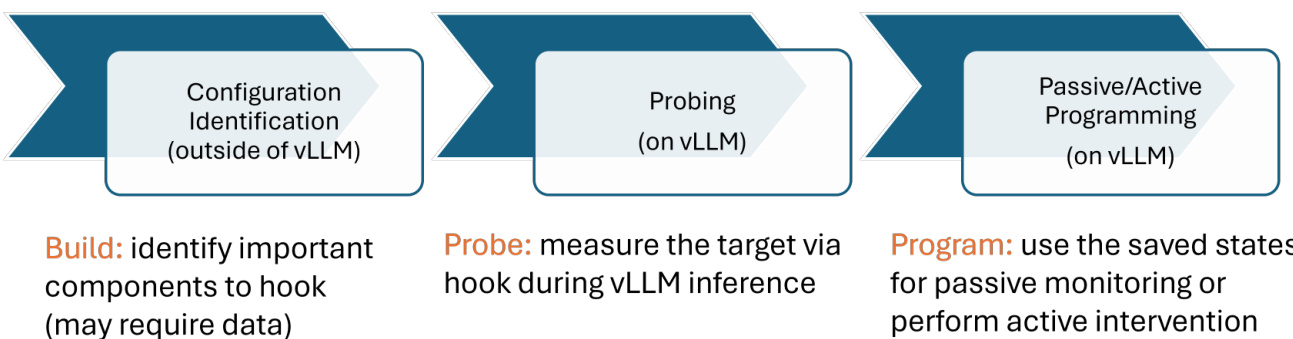
The workflow proceeds in three stages: configuration identification, probing, and programming. In the configuration stage, the user identifies the components to probe, potentially using external data. During probing, the worker measures targeted model internals via hooks during inference, capturing relevant activations or attention weights. The final stage involves programming, where the saved states are used either for passive monitoring—such as evaluating prompt injection risks—or for active intervention, such as steering model behavior. This process is illustrated in the framework diagram, where the vLLM-Hook plugin wraps the vLLM system and interacts with the LLMEngine, which manages input processing, scheduling, model execution, and output processing.
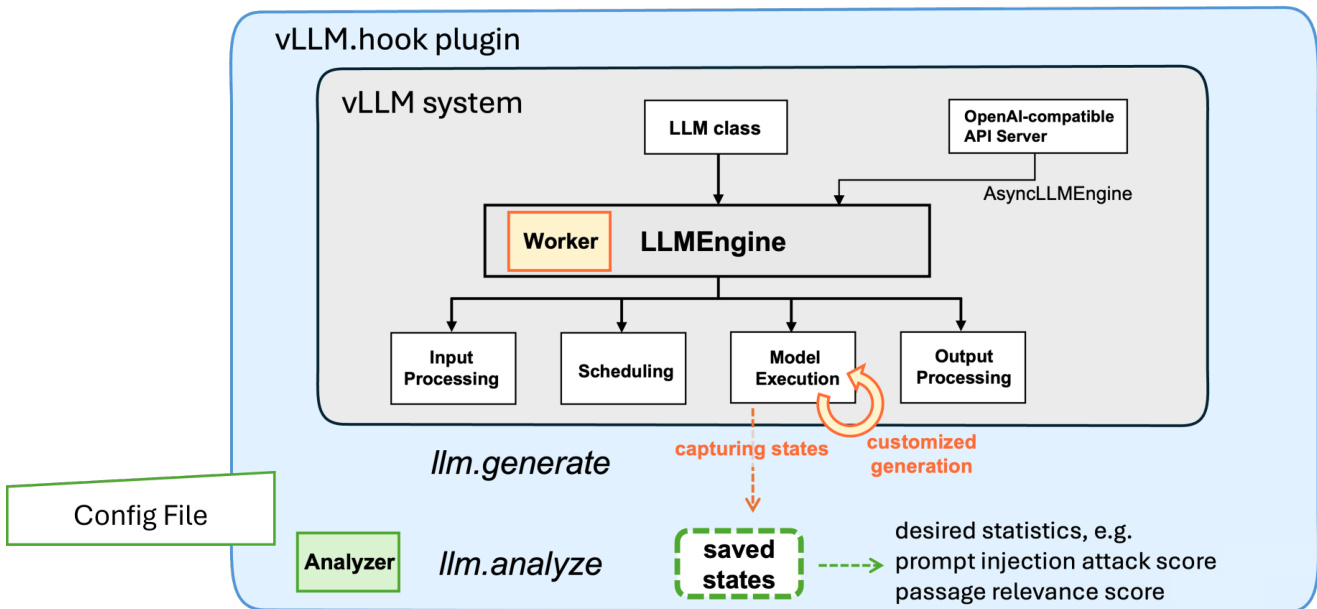
The analyzer component operates on the saved states after inference completion. It retrieves the cached data using a unique run identifier and reassembles the desired statistics, such as attention weights, to compute metrics like prompt injection attack scores or document relevance scores. This is achieved through a modular analyzer class that takes the hook directory and layer-to-head mappings as inputs and processes the cached data to compute specific metrics. The analyzer is triggered via the llm.analyze method, which allows users to perform post-inference analysis without modifying the core model or runtime. This modular design enables the framework to support a wide range of applications, including safety monitoring, model steering, and selective retrieval, by combining different workers and analyzers within the same orchestration system.