Command Palette
Search for a command to run...
من خلال عدسة التباين: الاستدلال البصري المحسّن ذاتيًا في نماذج اللغة البصرية (VLMs)
من خلال عدسة التباين: الاستدلال البصري المحسّن ذاتيًا في نماذج اللغة البصرية (VLMs)
Zhiyu Pan Yizheng Wu Jiashen Hua Junyi Feng Shaotian Yan Bing Deng Zhiguo Cao Jieping Ye
الملخص
أصبحت القدرة على الاستدلال (Reasoning) ميزة جوهرية للغة الكبيرة (LLMs). وفي المهام اللغوية، يمكن تعزيز هذه القدرة من خلال تقنيات التحسين الذاتي (self-improving techniques) التي تُحسِّن مسارات الاستدلال (reasoning paths) استعدادًا للضبط الدقيق (finetuning) اللاحق. ومع ذلك، فإن تعميم هذه النهج المعتمدة على اللغة والتي تعتمد على التحسين الذاتي إلى نماذج اللغات المرئية (VLMs) يطرح تحدياً فريداً يتمثل في عدم القدرة على التحقق الفعّال أو تصحيح الهلوسات البصرية (visual hallucinations) التي قد تظهر في مسارات الاستدلال.بدأت حلّتنا بملاحظة أساسية بشأن التباين البصري (visual contrast): فعند تقديم زوج استدلالي-سؤال تقابلي (contrastive VQA pair) – أي صورتين متشابهتين بصرياً مع أسئلة متساوية المعنى – فإن نماذج (VLMs) تحدد المؤشرات البصرية ذات الصلة بدقة أكبر. واستناداً إلى هذه الملاحظة، نقترح إطار عمل جديد للتحسين الذاتي يحمل اسم "المستدل الذاتي البصري التقابلي" (Visual Contrastive Self-Taught Reasoner) أو اختصاراً (VC-STaR). يستفيد هذا الإطار من التباين البصري للتخفيف من الهلوسات الموجودة في المبررات (rationales) التي يولدها النموذج.قمنا بجمع مجموعة متنوعة من مجموعات بيانات الاستدلالي-السؤال (VQA)، وقمنا بتنقيح أزواج تقابلية بناءً على التشابه متعدد الوسائط (multi-modal similarity)، ثم قمنا بتوليد المبررات باستخدام (VC-STaR). ونتيجة لذلك، حصلنا على مجموعة بيانات جديدة للاستدلال البصري تحمل اسم (VisCoR-55K)، والتي استُخدمت لاحقاً لتعزيز قدرات الاستدلال لدى نماذج (VLMs) المختلفة من خلال الضبط الدقيق الخاضع للإشراف (supervised finetuning).
One-sentence Summary
The authors propose Visual Contrastive Self-Taught Reasoner (VC-STaR), a self-improving framework that mitigates visual hallucinations in vision language models by leveraging contrastive VQA pairs to refine reasoning paths and curate the VisCoR-55K dataset, which is then used to boost the reasoning capability of various VLMs through supervised finetuning.
Key Contributions
- The Visual Contrastive Self-Taught Reasoner (VC-STaR) is proposed as a self-improving framework that leverages visual contrast to mitigate hallucinations in model-generated rationales. This approach capitalizes on the observation that vision language models identify relevant visual cues more precisely when presented with contrastive visual question answering pairs.
- A new visual reasoning dataset named VisCoR-55K is constructed by curating contrastive pairs from diverse VQA datasets and generating rationales using the proposed framework. This dataset serves as a resource for training models through supervised finetuning.
- Supervised finetuning with this dataset is shown to boost the reasoning capability of various vision language models. These results confirm that visual contrast effectively mitigates hallucinations in reasoning paths.
Introduction
Reasoning capabilities are essential for large models, yet applying self-improving techniques to Vision Language Models (VLMs) remains difficult because visual hallucinations cannot be easily verified. Existing approaches focus on textual coherence and often fail to correct errors where models prioritize text priors over actual visual evidence. The authors address this by introducing Visual Contrastive Self-Taught Reasoner (VC-STaR), a framework that uses contrastive VQA pairs to refine reasoning paths and mitigate hallucinations. This method generates the VisCoR-55K dataset, which significantly boosts reasoning capabilities across various benchmarks compared to existing baselines.
Dataset
-
Dataset Composition and Sources
- The authors aggregate 21 VQA datasets spanning five categories: reasoning, graph/chart, math, general, and OCR.
- This diverse collection ensures the generalization of the finetuned model across a wide spectrum of tasks.
-
Subset Details and Filtering
- An initial pool of 240k raw contrastive VQA pairs is curated using a greedy, first-match-exit search algorithm.
- Difficulty-based sampling retains only median samples where the model fails initially but succeeds with contrastive hints.
- The final VisCoR-55K dataset contains high-fidelity samples after quality-controlled rationale generation.
- Each contrastive pair features synonymous questions and visually similar images requiring fine-grained discrimination.
-
Model Usage and Processing
- The data supports supervised finetuning to enhance visual reasoning capabilities.
- Training inputs include the target image, question, answer, coarse rationale, and contrastive analysis.
- Visual embeddings rely on ID-based visual metric learning while text uses GTE embeddings.
- A text-matching-based post-processing step filters out rationales with erroneous reasoning patterns.
Method
The authors propose the Visual Contrastive Self-Taught Reasoner (VC-STaR), a framework designed to mitigate visual hallucinations in Visual Language Models (VLMs) through contrastive analysis. The core insight is that VLMs can perceive visual details more accurately when contrasting similar scenarios rather than analyzing images in isolation. Refer to the comparison between naive answering and contrasting.

As illustrated, a naive approach might lead to hallucinated details, whereas contrasting two similar images (e.g., different skateboarding tricks) allows the model to discriminate fine-grained features and generate a more faithful rationale.
The overall pipeline for constructing the training data involves three stages: data collection, contrastive pair hunting, and difficulty-based sampling. As shown in the figure below:
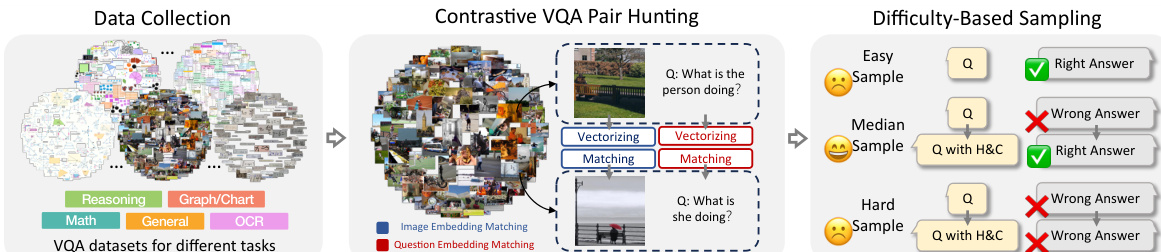
The process begins by aggregating diverse VQA datasets across various tasks. The system then performs contrastive pair hunting by vectorizing images and questions to identify pairs with synonymous questions and similar visual contexts. Finally, difficulty-based sampling is applied to curate samples of varying complexity, ensuring the model learns from both easy and challenging cases while filtering out incorrect reasoning patterns.
To refine the rationales, the method employs a three-step contrasting and rethinking procedure. As shown in the figure below:

First, in the Thinking step, the VLM generates a coarse rationale ri for the target sample (vi,qi,ai) using a thinking prompt. Second, in the Contrasting step, the VLM compares the target sample with a contrastive counterpart (v^i,q^i,a^i) to produce a contrastive analysis ci, identifying differences or common patterns. Third, in the Rethinking step, a Large Language Model (LLM) ψ utilizes the contrastive analysis ci to rectify the coarse rationale ri, producing a refined rationale r~i that is more logically sound and visually accurate.
This procedure results in the Visual Contrastive Reasoning dataset, VisCoR-55K. The distribution and examples of this dataset are illustrated below.

The dataset comprises 55K samples spanning five categories: General, Reasoning, Math, Graph/Chart, and OCR. These high-quality samples are used to finetune the VLM, enhancing its reasoning capabilities across multiple benchmarks.
Experiment
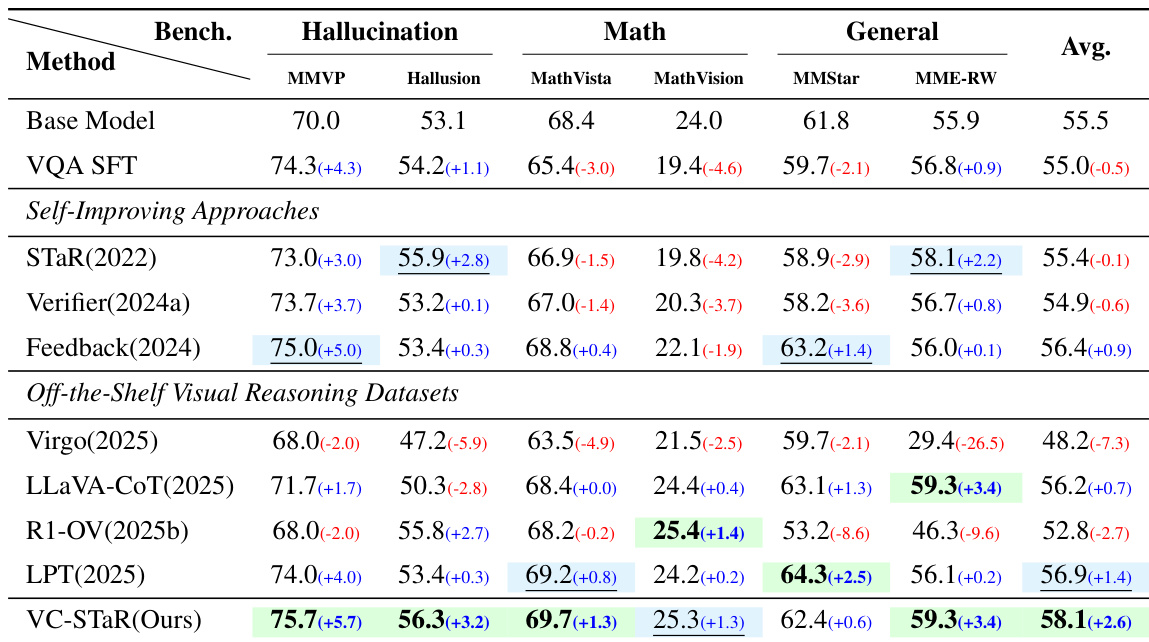
The experimental evaluation utilizes six benchmarks to assess hallucination, mathematical reasoning, and general capabilities, comparing the proposed method against self-improving baselines and models trained on external visual reasoning datasets. Results indicate that VC-STaR achieves consistent performance gains across all categories by effectively grounding textual rationales in visual evidence, whereas existing methods frequently trade off math and general capabilities for hallucination reduction. Additional analysis confirms the method generalizes across different base models and derives optimal performance from negative contrastive pairs, while demonstrating that including easy samples or relying on purely textual rationales is detrimental to reasoning quality.
The the the table presents an ablation study comparing the effects of positive and negative contrastive VQA pairs on model performance. While both types of pairs lead to improvements over the base model, the use of negative counterparts alone generates substantially higher gains. The optimal performance is achieved when both positive and negative pairs are combined, confirming their complementary roles in visual reasoning tasks. Negative contrastive pairs alone yield significantly higher performance gains compared to positive pairs alone. Combining both positive and negative counterparts results in the highest overall scores across the evaluated benchmarks. Tasks involving attribute comparison and object selection show the most substantial improvement when using negative contrastive pairs.

The authors evaluate their proposed method, VC-STaR, against base models, self-improving baselines, and models trained on off-the-shelf visual reasoning datasets across hallucination, math, and general benchmarks. Results show that VC-STaR achieves consistent performance improvements across all categories, particularly excelling in mitigating hallucinations and enhancing mathematical reasoning compared to other approaches. Unlike other self-improving methods that often trade off math or general capabilities for hallucination reduction, VC-STaR maintains balanced gains without significant degradation in other areas. VC-STaR outperforms existing self-improving baselines by avoiding the common trade-off where gains in hallucination resistance come at the cost of mathematical or general reasoning abilities. Models trained on off-the-shelf datasets show mixed results, with purely textual rationale approaches proving ineffective compared to the visually-native strategy employed by VC-STaR. The proposed method demonstrates superior average performance and significant improvements in hallucination benchmarks compared to the base model and other competing techniques.
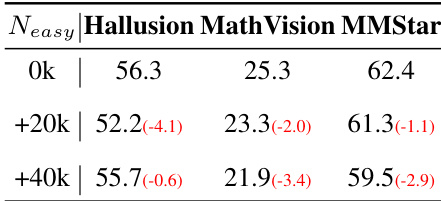
The authors investigate the impact of incorporating easy samples into the training dataset on the model's visual reasoning performance. The results demonstrate that adding these samples is generally detrimental, leading to performance declines across hallucination, mathematical, and general benchmarks compared to the baseline. Consequently, the method excludes easy samples to avoid potential overthinking and maintain optimal capabilities. The inclusion of easy samples results in performance drops across hallucination, math, and general benchmarks compared to the baseline. Mathematical reasoning and general perceptual abilities show consistent degradation as the quantity of easy samples increases. The authors determine that easy samples are harmful to the model's reasoning capabilities and exclude them from the final setup.
The authors evaluate the generalization capabilities of the VC-STaR method by applying it to different base models, specifically Qwen2.5VL-3B and InternVL2.5-8B. Results indicate that enabling the method consistently boosts performance across hallucination, mathematical reasoning, and general capability benchmarks for both architectures. Applying the method to the Qwen2.5VL-3B model results in measurable improvements across all tested benchmarks. The InternVL2.5-8B model also exhibits consistent performance gains when the approach is utilized. These findings validate the model-agnostic nature of the technique, showing it works effectively across different visual language model sizes and families.

Experiments validate the VC-STaR method through ablation studies and comparisons against various baselines to assess its impact on visual reasoning tasks. The ablation study reveals that combining positive and negative contrastive pairs achieves optimal performance, while adding easy samples is found to be detrimental to model capabilities. Overall, VC-STaR outperforms existing self-improving techniques by balancing hallucination reduction with mathematical and general reasoning gains, demonstrating consistent improvements across different model architectures.