Command Palette
Search for a command to run...
اختبارات نواة التباعد المحدد بالتحكم (Regularized f-Divergence)
اختبارات نواة التباعد المحدد بالتحكم (Regularized f-Divergence)
Mónica Ribero Antonin Schrab Arthur Gretton
الملخص
نقترح إطار عمل لبناء اختبارات عملية للمجموعتين (two-sample tests) القائمة على النواة (kernel-based) ضمن عائلة تباعدات f-divergences. يتم حساب إحصاءة الاختبار من دالة الشاهد (witness function) لتمثيل متغيري منتظم (regularized variational representation) للتباعد، والتي نقدرها باستخدام طرق النواة. يتميز الاختبار المقترح بتكيفه مع المعلمات الفائقة، مثل عرض النواة (kernel bandwidth) ومعامل الانتظام (regularation parameter). نقدم ضمانات نظرية لقوة الاختبار الإحصائي عبر مجموعة تقديرات تباعدات f-divergences المختلفة. وبينما يغطي اختباراتنا طيفاً واسعاً من تباعدات f-divergences، نركز بشكل خاص على تباعد Hockey-Stick، بدافع تطبيقاته في تدقيق الخصوصية التفاضلية (differential privacy auditing) وتقييم عدم التعلم الآلي (machine unlearning evaluation). وفي سياق اختبار المجموعتين، تُظهر التجارب أن تباعدات f-divergences المختلفة حساسة للفروق المحلية المتنوعة، مما يوضح أهمية الاستفادة من إحصائيات متنوعة. وفي مجال عدم التعلم الآلي، نقترح اختباراً نسبياً للتمييز بين حالات فشل عدم التعلم الحقيقية والتغيرات الآمنة في التوزيعات.
One-sentence Summary
The authors propose a framework for constructing practical kernel-based two-sample tests from f-divergences by estimating the witness function of a regularized variational representation using kernel methods, yielding tests that adapt to hyperparameters and offer theoretical guarantees on power, with a focus on the Hockey-Stick divergence for differential privacy auditing and machine unlearning evaluation, where a relative test distinguishes true unlearning failures from safe distributional variations.
Key Contributions
- This work introduces a framework to construct practical kernel-based two-sample tests from the family of f-divergences using a regularized variational representation. The test statistic is computed from the witness function estimated via kernel methods and is adaptive over hyperparameters such as kernel bandwidth and regularization parameters.
- The paper provides theoretical guarantees for statistical test power across the family of f-divergence estimates. Asymptotic and non-asymptotic power guarantees are established for the permutation tests based on these consistent divergence estimates.
- A relative distance test is proposed for machine unlearning to distinguish true unlearning failures from safe distributional variations. Experiments demonstrate that different f-divergences are sensitive to different localized differences, illustrating the importance of leveraging diverse statistics.
Introduction
Two-sample testing is essential for validating machine learning models in contexts like privacy auditing and machine unlearning. However, no single distance metric works for all scenarios since some applications require sensitivity to localized differences while others need smooth variations. Existing methods struggle because the witness function required for f-divergence estimation is often non-smooth and computationally difficult to learn. The authors introduce a unified framework for constructing two-sample tests from the family of f-divergences using kernel-based likelihood ratio estimation and ℓ2-regularization. They prove theoretical convergence guarantees and propose an aggregation method to detect a wide range of distributional changes. Additionally, they apply this framework to improve machine unlearning evaluation by introducing a relative distance test based on the Hockey-Stick divergence.
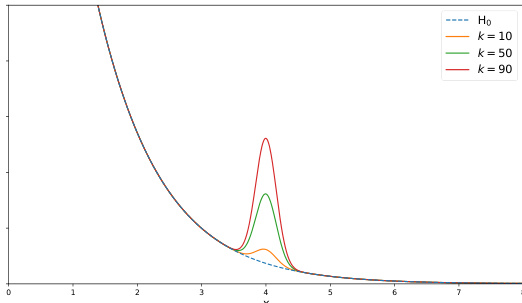
Method
The proposed framework constructs practical kernel-based two-sample tests from the family of f-divergences. The test statistic is computed from the witness function of a regularized variational representation of the divergence, which is estimated using kernel methods. This design enables the test to be adaptive over hyperparameters such as the kernel bandwidth and the regularization parameter while providing theoretical guarantees for statistical test power.
The method begins with the variational representation of the f-divergence. For probability distributions P and Q on a space Z, the divergence is defined using a convex function f. The variational form expresses the divergence as the supremum over functions of the difference between expectations under P and Q. The witness function is the function at which this supremum is attained. To estimate this, the authors focus on estimating the Radon-Nikodym derivative dQdP rather than the divergence directly. A λ-regularized version of this derivative is defined in a Reproducing Kernel Hilbert Space using a kernel k. This estimator admits a closed-form expression involving kernel matrices constructed from the samples and the regularization parameter.
Using the estimated density ratio, the authors construct an estimator for any f-divergence by substituting the estimate into the variational definition. The samples are split into two sets, where one set is used to construct the density ratio estimator and the other is used to estimate the expectations required for the divergence calculation. This separation ensures consistency, allowing the estimator to converge to the true f-divergence as the sample sizes tend to infinity.
For the hypothesis testing procedure, a permutation test is employed to control the probability of Type I error. The test rejects the null hypothesis when the estimated divergence exceeds a permutation quantile derived from the data. The authors prove that this test is consistent, meaning the probability of Type II error converges to zero as the sample sizes increase. To handle the inherent symmetry of the two-sample problem and the asymmetry of f-divergences, the method can utilize the average or maximum of the divergence in both directions.
Hyperparameter selection is addressed through an adaptive permutation test. This approach adaptively combines results from multiple hyperparameter configurations to avoid manual tuning. Additionally, an aggregated test called f-Agg is constructed to aggregate these adaptive permutation tests over a collection of f-divergences. This aggregation enhances the power of the test against a wide range of alternatives by leveraging diverse statistics sensitive to different localized differences.
A specific focus is placed on the Hockey-Stick divergence, motivated by its applications in differential privacy auditing and machine unlearning. The Hockey-Stick divergence corresponds to a specific convex function where the witness function is an indicator function based on a threshold. The authors derive a specific estimator for this divergence using the regularized density ratio. While direct optimization of the regularized Hockey-Stick witness function is possible via semidefinite programming, empirical results suggest that the plug-in estimator approach yields better performance. This is because the Reproducing Kernel Hilbert Space function class used in direct optimization may not be well-suited for representing the discontinuous nature of the true witness function.
The framework provides non-asymptotic power guarantees, characterizing the set of alternatives that can be detected with high probability at any fixed sample size. Theoretical analysis demonstrates that any distributions for which the f-divergence is greater than a rate decreasing with sample sizes can be correctly detected with high accuracy. These guarantees hold for the proposed permutation tests as well as for tests based on regularized χ2-divergence. The method effectively balances the accuracy of estimating the likelihood ratio with the efficiency in terms of the number of samples required.
Experiment
This work evaluates proposed f-divergence tests against state-of-the-art baselines on synthetic benchmarks and practical applications such as differential privacy auditing and machine unlearning. Experiments demonstrate that deregularized MMD and KALE achieve superior statistical power over standard MMD in detecting outliers, particularly for small perturbations where traditional methods struggle. Additionally, the study identifies limitations in using two-sample tests for machine unlearning evaluation due to sensitivity to training noise, proposing a three-sample test that more accurately distinguishes successful unlearning from inherent model variability.
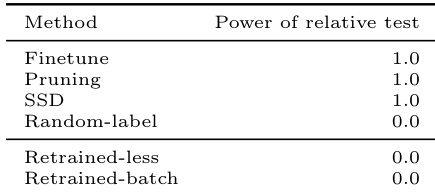
The the the table presents the results of a three-sample relative similarity test used to evaluate the effectiveness of various machine unlearning methods. It demonstrates that approximate unlearning techniques such as Finetuning, Pruning, and SSD are consistently identified as ineffective, while the Random-label technique and retraining variants are correctly classified as safe. Approximate methods like Finetuning, Pruning, and SSD exhibit high test power, indicating they fail to remove the influence of the forget set. The Random-label method and retraining variations show no test power, confirming they produce models statistically indistinguishable from a retrained baseline. The test successfully distinguishes between ineffective approximate unlearning strategies and successful unlearning procedures.
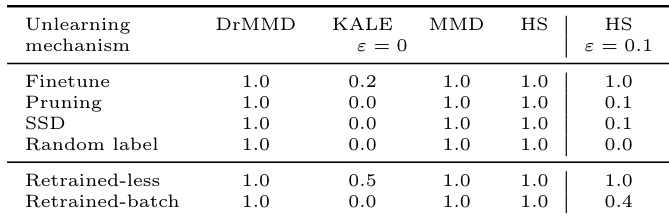
The authors evaluate machine unlearning mechanisms by testing the statistical indistinguishability between unlearned models and retrained baselines. Results indicate that strict two-sample tests like MMD and DrMMD detect distributional differences even in valid retraining scenarios with varying hyperparameters, limiting their utility for verification. However, using the Hockey-Stick divergence with a relaxed parameter allows for better differentiation between approximate unlearning methods and the retrained baseline. MMD and DrMMD tests consistently reject the null hypothesis for all unlearning and retraining variations, indicating they are too sensitive to training noise. Approximate unlearning methods like Pruning and SSD show lower detection rates under the relaxed Hockey-Stick test compared to Finetuning. The KALE test exhibits generally lower statistical power compared to other divergence-based tests across the evaluated unlearning mechanisms.
The the the table compares the statistical power of various two-sample tests on the Expo-1D benchmark across different distribution parameters. Results indicate that the KALE estimator generally achieves higher power than MMD and DrMMD in settings with moderate perturbation multipliers, while MMD becomes the superior method when the perturbation multiplier is large. The proposed methods consistently achieve higher detection rates than the baseline from prior work in most configurations. KALE demonstrates superior performance compared to MMD and DrMMD in the majority of parameter configurations. MMD achieves the highest detection rate when the perturbation multiplier is large. The proposed tests generally outperform the baseline method from prior work across most tested settings.

The authors evaluate the Hockey-Stick (HS) test against the DP-Auditorium library for detecting privacy violations in non-private mechanisms using sample sizes of 500 and 5000. The results indicate that the HS test is highly effective at identifying violations across all tested mechanisms, whereas the DP-Auditorium baseline struggles to detect deviations in most cases. The HS test consistently identifies privacy violations across all tested non-private mechanisms, whereas the DP-Auditorium baseline fails to detect violations in most SVT variants. For mean-based mechanisms, the HS test achieves high detection rates even with smaller sample sizes, while the baseline shows significantly lower sensitivity. Increasing the sample size improves the detection capability of both methods, but the HS test maintains a clear advantage in statistical power over the DP-Auditorium library.

The experiments evaluate machine unlearning effectiveness and statistical test performance to distinguish between successful and approximate removal techniques. Results indicate that approximate methods like Finetuning and Pruning fail to remove data influence, while the Hockey-Stick divergence test provides better differentiation than stricter metrics like MMD that are overly sensitive to training noise. Furthermore, the proposed statistical tests consistently demonstrate higher power than baseline libraries in detecting privacy violations and distributional differences across varying parameter configurations.