Command Palette
Search for a command to run...
إعادة بناء الكائنات الديناميكية بكفاءة: دقة واحدة من D4RT في كل مرة
إعادة بناء الكائنات الديناميكية بكفاءة: دقة واحدة من D4RT في كل مرة
الملخص
تظل استيعاب وإعادة بناء الهندسة المعقدة والحركة في المشاهد الديناميكية من مقاطع الفيديو تحدياً كبيراً في مجال رؤية الكمبيوتر. تطرح هذه الورقة البحثية نموذجاً جديداً يدعى D4RT، وهو نموذج بسيط لكنه قوي وموجه للأمام (feedforward model)، مصمم لحل هذه المهمة بكفاءة. يستفيد D4RT من معمارية Transformer موحدة لاستنتاج العمق، والتطابق المكاني-الزمني، وجميع معلمات الكاميرا من مقطع فيديو واحد. تكمن الابتكار الأساسي للنموذج في آلية استعلام جديدة تتجنب الحسابات الكثيفة الناتجة عن فك التشفير الكثيف لكل إطار (per-frame decoding) والتعقيد المرتبط بإدارة عدة مفككات مخصصة لكل مهمة (task-specific decoders). تسمح واجهة فك التشفير في النموذج بالاستكشاف المستقل والمرن للمواقع ثلاثية الأبعاد لأي نقطة في المكان والزمان. النتيجة هي طريقة خفيفة الوزن وقابلة للتوسع بشكل كبير، مما يتيح تدريباً واستنتاجاً (inference) عاليي الكفاءة. أثبتت النتائج أن نهجنا يحقق أداءً قياسياً جديداً (state of the art)، متفوقاً على الطرق السابقة عبر مجموعة واسعة من مهام إعادة البناء رباعي الأبعاد (4D reconstruction). يمكن الاطلاع على النتائج المتحركة عبر صفحة المشروع.
One-sentence Summary
D4RT is a feedforward unified transformer model that efficiently reconstructs dynamic scenes from a single video by jointly inferring depth, spatio-temporal correspondence, and full camera parameters through a novel querying mechanism that sidesteps dense per-frame decoding to enable independent and flexible probing of any point in space and time while setting a new state of the art across a wide spectrum of 4D reconstruction tasks.
Key Contributions
- The paper introduces D4RT, a feedforward model that utilizes a unified transformer architecture to jointly infer depth, spatio-temporal correspondence, and camera parameters from a single video. This design unifies tasks that previously required separate heads or multi-stage pipelines within a single architecture.
- A novel querying mechanism enables the model to independently probe the 3D position of any point in space and time without relying on dense per-frame decoding. This flexible parametrization avoids computational bottlenecks and allows inference to scale linearly with the number of reconstructed points.
- Experiments demonstrate that the method sets a new state of the art by outperforming previous approaches across a wide spectrum of 4D reconstruction tasks including depth and point tracking. Visual comparisons indicate the model successfully reconstructs full 4D representations including all pixels where other methods exhibit failure cases or gaps.
Introduction
Understanding and reconstructing the geometry and motion of dynamic scenes from video is a critical challenge in computer vision. Existing methods often depend on fragmented pipelines or separate decoders that require expensive optimization and fail to handle dynamic regions effectively. The authors introduce D4RT, a unified feedforward model leveraging a transformer architecture to jointly infer depth, spatio-temporal correspondence, and camera parameters. Their core innovation is a querying mechanism that avoids dense per-frame decoding by allowing independent probing of any point in space and time. This design enables efficient training and inference while setting a new state of the art for 4D reconstruction tasks.
Method
The D4RT framework is built upon a streamlined encoder-decoder architecture inspired by Scene Representation Transformers. As shown in the figure below, the system processes an input video sequence through a powerful encoder to generate a compact Global Scene Representation. This representation captures dense correspondences across all frames and encodes the temporal flow of the scene. A lightweight decoder then queries this representation to predict 3D point positions for specific spatio-temporal coordinates.
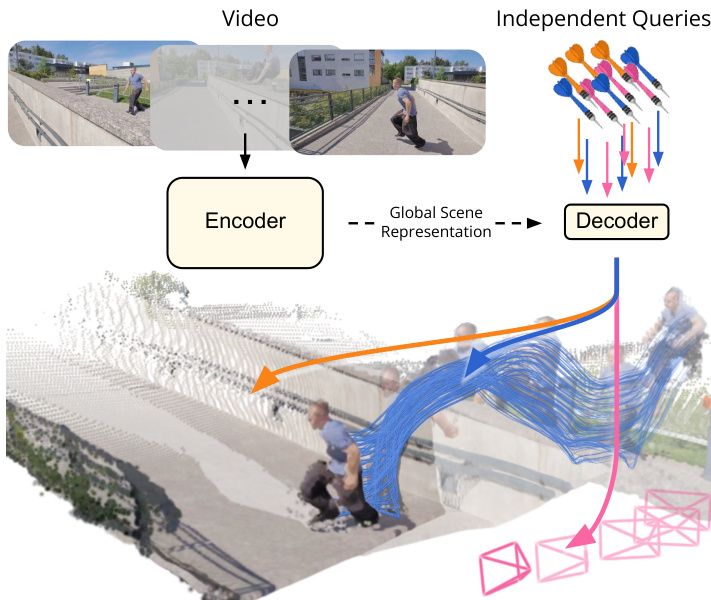
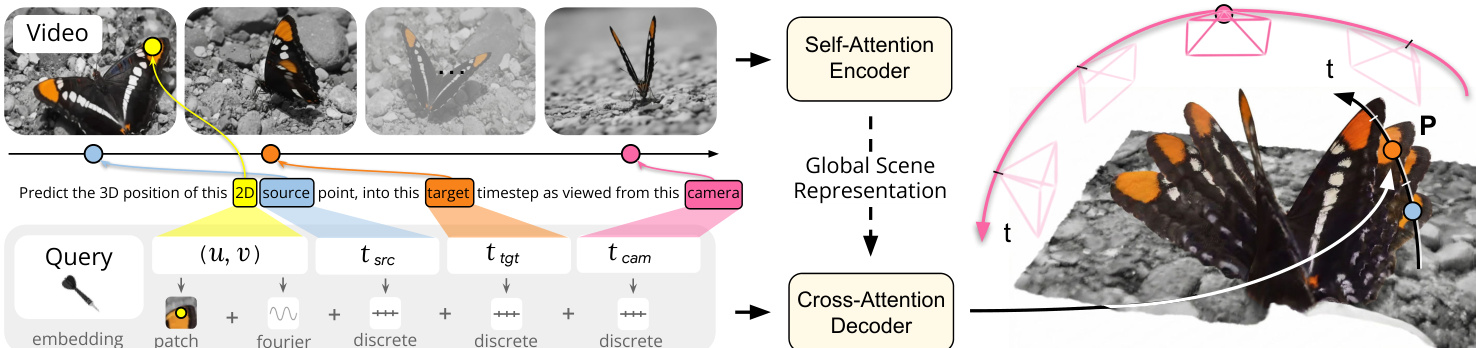
The core of the method relies on a flexible query interface that allows for the disentanglement of space and time. The authors define a query q=(u,v,tsrc,ttgt,tcam), where (u,v) represents the normalized 2D coordinates of a point in a source frame tsrc. The parameters ttgt and tcam denote the target timestep for the prediction and the reference camera coordinate system, respectively. This formulation enables the model to predict the 3D position of a point at any target time relative to any camera view. Refer to the diagram below for a visualization of how these query components map to the video frames and the resulting 3D reconstruction.
Regarding the specific model architecture, the encoder is based on a Vision Transformer with interleaved local frame-wise and global self-attention layers. To support arbitrary aspect ratios, input videos are resized to a fixed square resolution, with the original aspect ratio embedded as a separate token. The decoder operates as a small cross-attention transformer where each query is processed independently. A query token is constructed by combining Fourier feature embeddings of the 2D coordinates with learned discrete timestep embeddings and a local pixel patch embedding. The architecture details, including the N Encoder Blocks and M Decoder Blocks, are illustrated in the figure below.
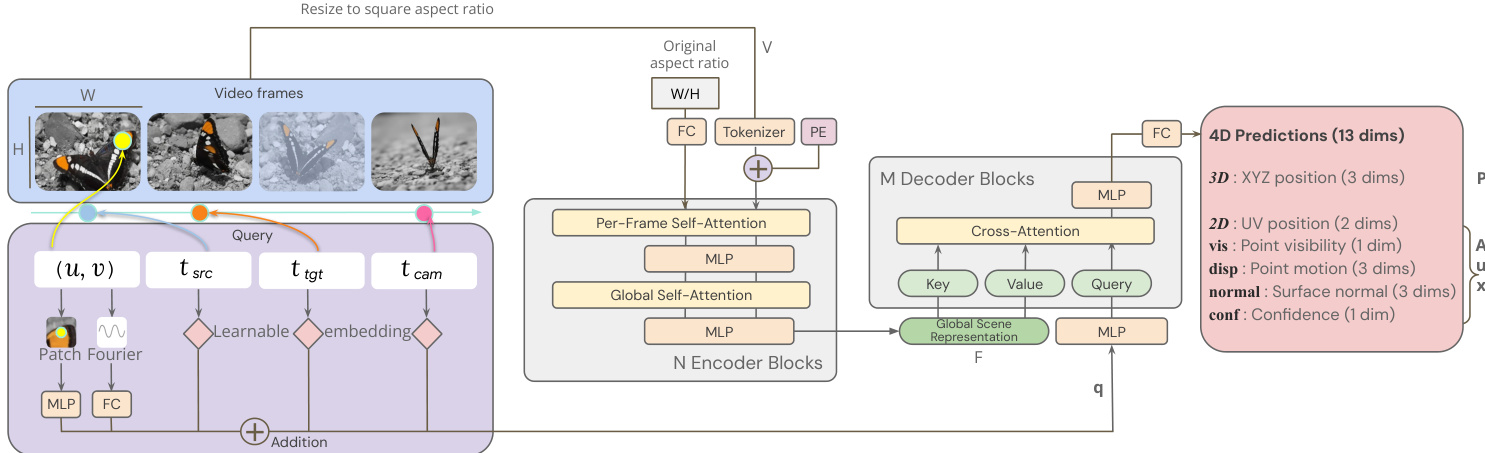
The output of the decoder is a 4D prediction vector containing 13 dimensions. This includes the 3D XYZ position, 2D UV position, point visibility, point motion vector, surface normal, and a confidence score. The model is trained end-to-end by minimizing a composite loss function L, which is a weighted sum of task-specific losses computed over a batch of sampled queries. The primary supervision comes from an L1 loss on the normalized 3D point position, alongside auxiliary losses for 2D coordinates, surface normals, visibility, and motion. To efficiently compute dense correspondences for all pixels, the authors employ an algorithm that exploits spatio-temporal redundancy using an occupancy grid. This approach avoids the computational cost of naive O(T2HW) queries by only initiating new tracks from unvisited pixels.
Experiment
The evaluation benchmarks D4RT against recent advanced methods across 4D reconstruction, tracking, and pure reconstruction tasks using diverse real world and synthetic datasets. Qualitative and quantitative comparisons demonstrate that D4RT achieves robust 4D representations by tracking all dynamic pixels within a unified reference frame while delivering superior accuracy in depth estimation and camera pose tasks with significantly higher throughput than prior approaches. Additionally, ablation studies confirm that architectural components like local RGB patches and pretrained encoders are essential for preserving detailed features and scaling performance.
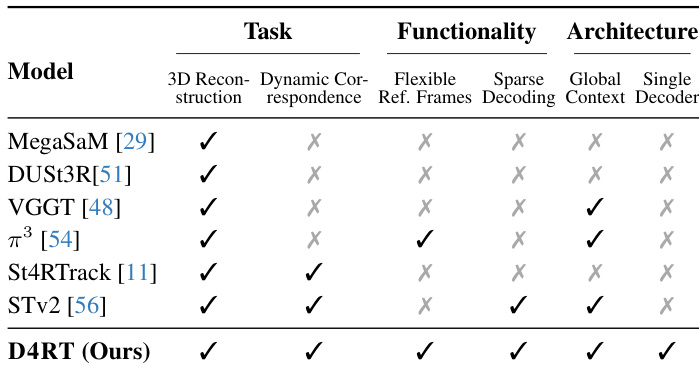
The authors compare D4RT against recent state-of-the-art methods across various tasks and architectural features. While other models excel in specific areas like 3D reconstruction or dynamic correspondence, D4RT is the only method that combines all listed capabilities. This includes support for flexible reference frames, sparse decoding, and global context within a single decoder architecture. D4RT is the only model to feature a single decoder architecture while maintaining global context awareness. The proposed method uniquely combines flexible reference frames with sparse decoding capabilities. D4RT is the only approach listed that satisfies every capability criterion across tasks, functionality, and architecture columns.
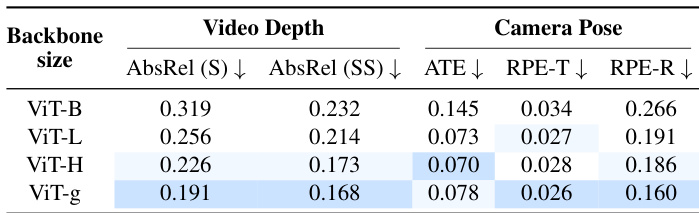
The authors investigate the impact of scaling the ViT encoder backbone size on video depth and camera pose estimation performance. Results demonstrate a consistent trend where larger backbones yield superior accuracy, with the largest model variant achieving the lowest error rates across all metrics. Increasing backbone size consistently lowers error rates for video depth estimation. Camera pose accuracy improves with larger backbones, showing reduced translation and rotation errors. The largest backbone variant achieves the best performance across all reported metrics.
The authors benchmark their model against recent state-of-the-art methods on point cloud reconstruction and video depth estimation tasks. The results demonstrate that their approach consistently achieves the lowest error rates across multiple datasets, including Sintel, ScanNet, and KITTI. This indicates superior performance in both reconstructing 3D geometry and estimating depth in dynamic scenes. The proposed method achieves the best accuracy for point cloud reconstruction on both the Sintel and ScanNet benchmarks compared to competing models. In video depth estimation tasks, the model outperforms all baselines on the challenging Sintel dataset under both scale-only and scale-and-shift alignment settings. Performance remains robust across diverse datasets such as ScanNet and KITTI, where the method consistently records lower error metrics than previous state-of-the-art approaches.

The authors investigate how query density and patch fidelity affect high-resolution decoding capabilities. They compare configurations that vary the output resolution and the resolution of the local RGB patches used during decoding. The results demonstrate that extracting high-resolution local patches yields the sharpest boundaries and best overall accuracy compared to baseline or naive high-resolution querying. Using high-resolution local RGB patches achieves the lowest boundary error rates under both scale and scale-and-shift alignments. Incorporating local appearance information significantly improves performance over the baseline configuration without patches. Naive dense querying at original resolution performs worse than using high-fidelity patches at the same resolution for boundary accuracy.

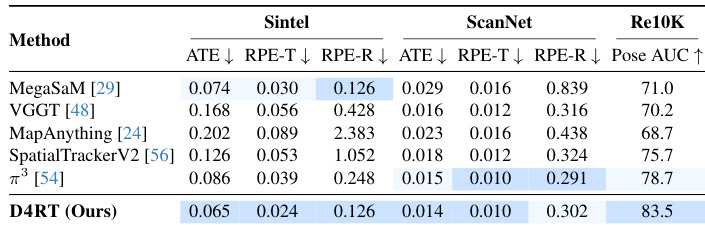
This experiment benchmarks camera pose estimation performance on static indoor scenes and dynamic outdoor scenes against recent state-of-the-art methods. The results indicate that the proposed model consistently achieves superior accuracy, particularly in minimizing translation errors and maximizing pose consistency across different environments. The proposed method achieves the lowest absolute translation error on both the Sintel and ScanNet datasets. Relative translation accuracy is superior to all competing baselines on the ScanNet dataset. The model secures the highest pose accuracy score on the Re10K benchmark.
The authors benchmark the proposed method against recent state-of-the-art approaches across tasks including point cloud reconstruction, video depth estimation, and camera pose estimation. Investigations into model scaling and decoding configurations demonstrate that larger backbones and high-resolution local patches consistently yield improved accuracy and sharper boundaries. Notably, the method uniquely combines flexible reference frames with sparse decoding to achieve superior performance across diverse static and dynamic environments.