Command Palette
Search for a command to run...
نشر Mistral Large 2407 123B عبر Open WebUI بنقرة واحدة
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
The authors empirically evaluate the instruction-tuned Mistral-Small 3 24B and reasoning-augmented Qwen 2.5 32B for biomedical text simplification, utilizing a 21-metric correlation framework to reveal divergent readability-accuracy strategies wherein Mistral employs tempered lexical simplification to consistently enhance readability while preserving human-comparable discourse fidelity (BERTScore: 0.91), whereas Qwen achieves improved readability but exhibits a BERTScore of 0.89 and a clear disconnect between readability and accuracy.
Key Contributions
- Empirical evaluation of prompt-only simplification strategies on the instruction-tuned Mistral-Small 3 24B and reasoning-augmented Qwen 2.5 32B models establishes updated practical baselines for biomedical text simplification. The assessment identifies lexical simplification rather than syntactic restructuring as the primary hurdle in maintaining semantic equivalence across complex abstracts.
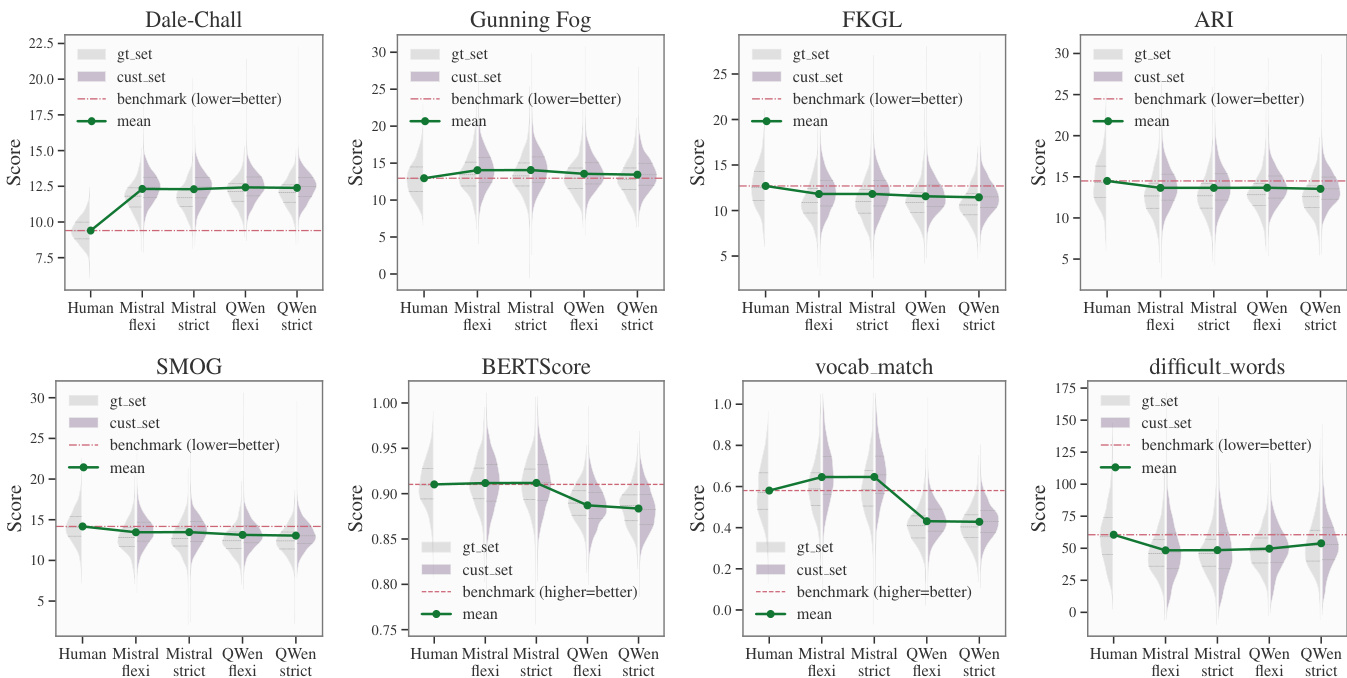
- The instruction-tuned Mistral-Small 3 24B model demonstrates superior readability gains while preserving discourse fidelity with a BERTScore of 0.91, which remains statistically comparable to human performance. This output maintains robustness across varying temperature configurations, contrasting with the reasoning-augmented Qwen 2.5 32B model that struggles to balance readability improvements with factual accuracy.
- A comprehensive correlation analysis of 21 readability and accuracy metrics clarifies their functional relationships and identifies strong redundancies within automated simplification evaluations. This assessment quantifies the inherent tension between readability gains and content preservation to inform specific adaptation requirements for biomedical language processing systems.
Introduction
The authors address the urgent need to make complex biomedical content accessible to the public, since poor readability in patient materials and digital health information fuels misinformation and undermines informed decision-making. While large language models present a scalable solution for automated text simplification, prior research consistently highlights a critical trade-off between readability gains and factual accuracy, with domain-adapted methods yielding conflicting results and often failing to surpass general-purpose alternatives. To evaluate this balance without relying on inaccessible fine-tuning, the authors benchmark two medium-sized general-purpose LLMs against human experts using biomedical abstracts. They identify lexical simplification as the primary technical hurdle, demonstrate that instruction-tuned models can achieve human-level discourse fidelity while maximizing readability, and deliver a rigorous analysis of how readability and accuracy metrics correlate in automated simplification workflows.
Dataset

- Dataset Composition and Sources: The authors use a two-part dataset combining a public benchmark with a custom domain collection. The primary benchmark consists of 750 biomedical abstracts paired with expert human simplifications from Attal et al. (2023). The custom subset contains randomly sampled abstracts focused on Traditional Chinese Medicine and Oncology.
- Key Subset Details: The benchmark abstracts are curated to span 75 medical topics and serve as a control cohort, while the paired human texts function as the reference target. The custom subset is uncurated and specifically targets high terminology density areas with strong clinical relevance for public health applications.
- Data Usage and Processing: The paired abstracts and human simplifications drive the evaluation of model readability and accuracy. The authors leverage the control set as a baseline and the human texts as ground truth to compare how different language models approach simplification across general and specialized domains.
- Metadata and Structured Processing: Simplification outputs are standardized using a Pydantic schema that captures the original phrase, the transformed phrase, a categorized change type (including jargon swapping, explanation, abstraction, omission, or no change), and a concise rationale limited to under 30 words. This structured metadata enables systematic tracking and analysis of model simplification strategies.
Method
The authors leverage two distinct large language model (LLM) architectures for text simplification: Mistral-Small 3 24B and Qwen 2.5 32B. The Mistral-Small 3 24B model is instruction-tuned to prioritize task fidelity, ensuring precise execution of the simplification task. In contrast, the Qwen 2.5 32B model is designed with reasoning augmentation to handle complex problem-solving scenarios, making it suitable for nuanced simplification tasks. To evaluate robustness, each model is configured with two temperature settings: a strict configuration with T=0.2, which produces more deterministic outputs, and a flexible configuration with T=0.4, which introduces higher stochasticity. These configurations yield four LLM-based simplification processes, complemented by a human-expert simplification process, forming five plain-text adaptation systems in the study.
Experiment
This study evaluates the zero-shot biomedical text simplification capabilities of instruction-tuned Mistral-Small 3 24B and reasoning-augmented Qwen 2.5 32B by benchmarking their system goodness, readability, semantic fidelity, and safety against human experts. The experiments validate how each model navigates the trade-off between lexical simplification and meaning preservation, revealing that both successfully master syntactic restructuring but differ fundamentally in lexical handling. Mistral employs a conservative strategy that selectively retains specialized terminology, enabling it to maintain human-level semantic fidelity while effectively balancing readability and accuracy. Conversely, Qwen pursues a more exploratory approach through aggressive substitution and conceptual expansion, which boosts readability but introduces a measurable risk of semantic degradation, ultimately highlighting lexical control as the central hurdle in automated simplification.
The authors compare two large language models for biomedical text simplification, focusing on readability and accuracy. Mistral consistently outperforms QWen in system goodness and achieves human-level discourse fidelity, while QWen shows higher readability on some metrics but with weaker semantic preservation. The analysis reveals distinct operational strategies, with Mistral adopting a conservative approach that balances simplification and meaning retention, whereas QWen uses a more exploratory method that prioritizes readability at the cost of semantic integrity. Mistral achieves superior system goodness and human-level discourse fidelity compared to QWen. QWen attains higher readability on several metrics but shows weaker semantic preservation and a disconnect between readability and accuracy. Mistral employs a conservative strategy that selectively simplifies text while retaining specialized vocabulary, whereas QWen uses conceptual expansion, risking semantic degradation.
The authors compare two large language models for biomedical text simplification, evaluating their performance across readability, accuracy, and content safety. Results show that the instruction-tuned model achieves stronger alignment between readability and semantic fidelity, while the reasoning-augmented model produces more readable text but with greater risk to meaning preservation. Both models demonstrate superior readability on most metrics compared to human benchmarks, though they differ in their handling of lexical complexity and syntactic structure. The instruction-tuned model achieves better alignment between readability and semantic accuracy, with performance comparable to human benchmarks. The reasoning-augmented model produces more readable outputs but shows a disconnect between readability gains and semantic preservation. Both models improve readability on most metrics, with significant differences observed in their treatment of difficult words and vocabulary retention.
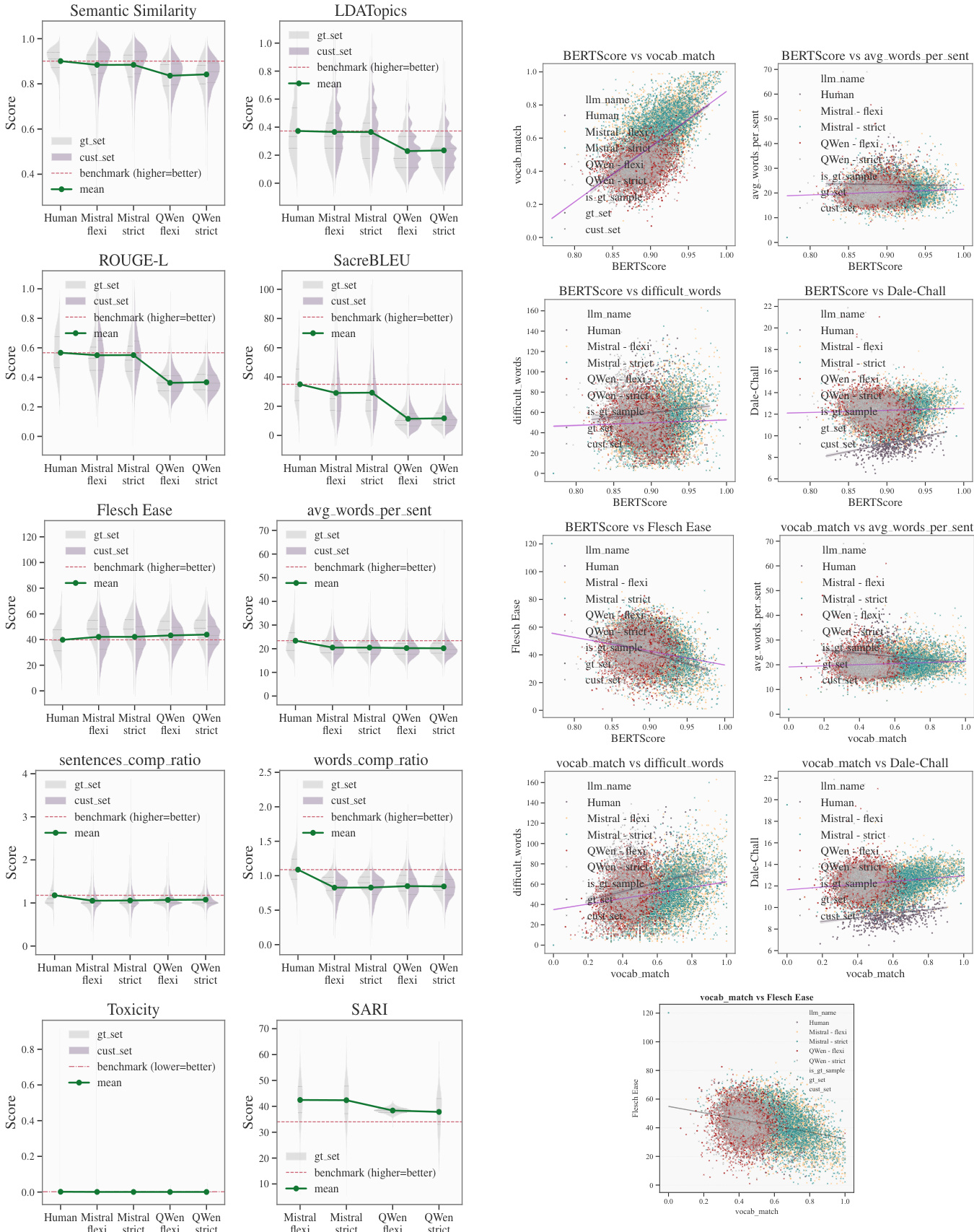
The authors compare two large language models, Mistral and Qwen, in biomedical text simplification, focusing on readability and accuracy. Mistral demonstrates more consistent performance across metrics, achieving results comparable to human benchmarks in semantic fidelity and maintaining better balance between readability and accuracy. Qwen achieves higher readability scores on several metrics but shows weaker correlations between readability and accuracy, suggesting a trade-off in semantic preservation. Both models reduce difficult words compared to human experts, but Mistral retains more specialized vocabulary, indicating a more conservative approach. Mistral achieves human-level semantic fidelity and maintains better balance between readability and accuracy compared to Qwen. Qwen achieves higher readability scores on multiple metrics but shows weaker correlations between readability and accuracy, indicating potential semantic degradation. Both models reduce difficult words compared to human experts, but Mistral retains more specialized vocabulary, suggesting a more conservative simplification strategy.
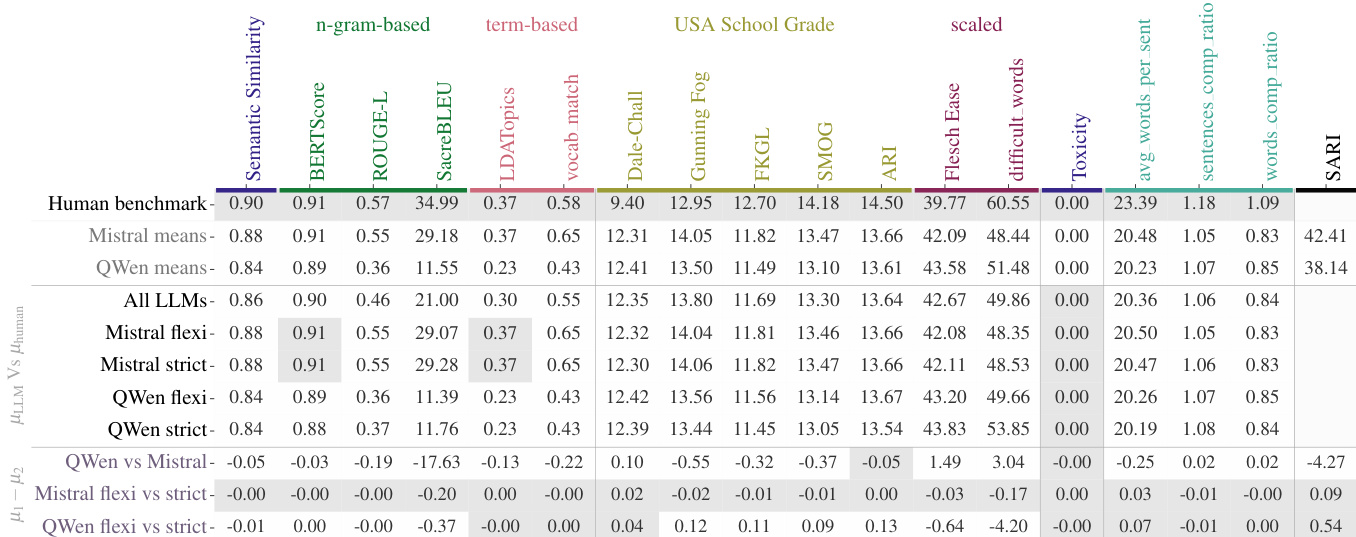
The authors compare two large language models, Mistral and Qwen, for biomedical text simplification, evaluating their performance across readability, accuracy, and content safety. Mistral demonstrates more consistent and human-like simplification, achieving higher system goodness and better alignment between readability and semantic fidelity, while Qwen produces more readable text but with greater risk of semantic degradation. Both models show robust performance on most readability metrics, though they differ in their handling of lexical complexity and vocabulary retention. Mistral achieves higher system goodness and better alignment between readability and accuracy compared to Qwen. Qwen produces more readable text but shows greater risk of semantic degradation, particularly in vocabulary retention and BERTScore. Both models demonstrate robust performance on readability metrics, with Mistral showing more consistent results across different temperature settings.
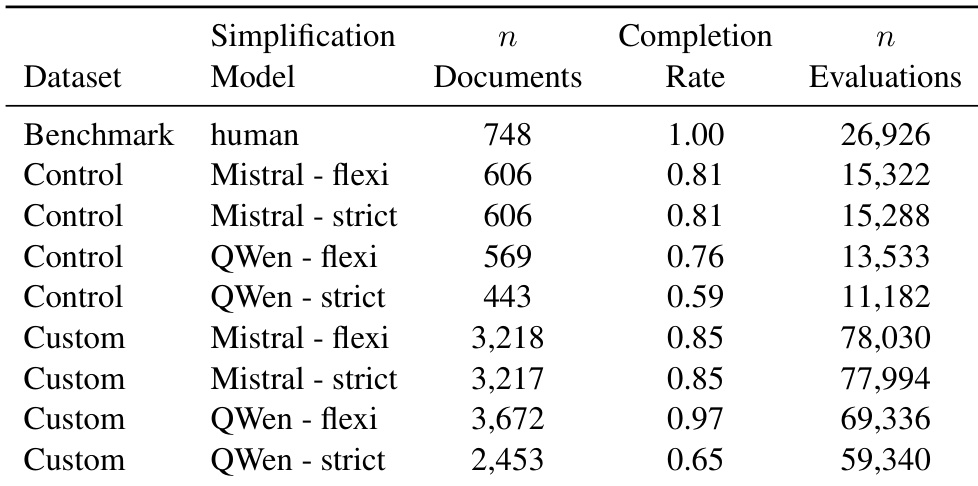
The authors compare two large language models for biomedical text simplification, analyzing their performance across readability and accuracy metrics. Mistral demonstrates a conservative approach that balances lexical simplification with semantic fidelity, achieving performance comparable to human experts. In contrast, QWen adopts a more exploratory strategy that improves readability but shows weaker alignment between readability and accuracy metrics. Mistral achieves human-level performance on BERTScore and vocabulary matching, indicating strong semantic preservation. QWen shows superior readability on most metrics but has weaker correlations between readability and accuracy, suggesting a disconnect in optimization strategies. Mistral's approach is more consistent across temperature settings, while QWen is sensitive to configuration changes, affecting its performance stability.
The experiments evaluate two large language models, Mistral and Qwen, for biomedical text simplification by assessing their readability, semantic accuracy, and overall system performance. Qualitative analysis reveals that Mistral employs a conservative strategy that effectively balances lexical simplification with meaning retention, achieving human-level discourse fidelity and consistent results across settings. Conversely, Qwen adopts a more exploratory approach that enhances surface readability but compromises semantic integrity and performance stability. Ultimately, the findings validate that maintaining a careful balance between fluency and semantic preservation is essential for reliable biomedical text simplification.