Command Palette
Search for a command to run...
عجلة البيانات التكيفية: تطبيق حلقات تحكم MAPE على تحسين وكلاء الذكاء الاصطناعي
عجلة البيانات التكيفية: تطبيق حلقات تحكم MAPE على تحسين وكلاء الذكاء الاصطناعي
بناء وكيل ذكاء اصطناعي يعتمد على OpenManus و QwQ-32B
الملخص
يجب على وكلاء الذكاء الاصطناعي المؤسسيين التكيف باستمرار للحفاظ على الدقة، وتقليل زمن الاستجابة (اللاتنسي)، والبقاء متوافقين مع احتياجات المستخدمين. نقدم تنفيذًا عمليًا لدوّامة البيانات في NVInfo AI، وهو مساعد المعرفة القائم على مزيج الخبراء (MoE) من شركة NVIDIA، والذي يخدم أكثر من 30,000 موظف. ومن خلال تشغيل دوّامة بيانات مدفوعة بإطار عمل MAPE، قمنا ببناء نظام حلقة مغلقة يعالج بشكل منهجي حالات الفشل في خطوط أنابيب التوليد المعزز بالاسترجاع (RAG)، ويمكّن من التعلم المستمر. خلال فترة ما بعد النشر الممتدة على 3 أشهر، راقبنا التعليقات وجمعنا 495 عينة سلبية. وكشفت التحليلات عن نمطين رئيسيين للفشل: أخطاء التوجيه (5.25%) وأخطاء إعادة صياغة الاستعلامات (3.2%). باستخدام خدمات NVIDIA NeMo المصغرة، نفذنا تحسينات مستهدفة من خلال الضبط الدقيق. بالنسبة للتوجيه، استبدلنا نموذج Llama 3.1 بحجم 70 مليار معلمة بمتغير مضبوط بدقة بحجم 8 مليارات معلمة، مما حقق دقة بنسبة 96%، وانخفاضًا بمقدار 10 أضعاف في حجم النموذج، وتحسينًا في زمن الاستجابة بنسبة 70%. أما بالنسبة لإعادة صياغة الاستعلامات، فقد أسفر الضبط الدقيق عن تحقيق مكسب في الدقة بنسبة 3.7%، وانخفاض في زمن الاستجابة بنسبة 40%. توضح منهجنا كيف يمكن لتعليقات الإنسان في الحلقة (HITL)، عند هيكلتها ضمن دوّامة البيانات، أن تحول وكلاء الذكاء الاصطناعي المؤسسيين إلى أنظمة ذاتية التحسين. وتشمل الدروس المستفادة الرئيسية أساليب ضمان متانة الوكلاء على الرغم من محدودية تعليقات المستخدمين، والتنقل ضمن قيود الخصوصية، وتنفيذ عمليات النشر التدريجية في بيئة الإنتاج. تقدم هذه الدراسة مخططًا قابلًا للتكرار لبناء وكلاء ذكاء اصطناعي مؤسسيين متينين وقادرين على التكيف، والذين يتعلمون من الاستخدام الواقعي على نطاق واسع.
One-sentence Summary
By operationalizing a MAPE-driven data flywheel with NVIDIA NeMo microservices, the authors fine-tuned routing and query rephrasal components for the NVInfo AI knowledge assistant, replacing a Llama 3.1 70B model with an 8B variant that achieved 96% accuracy, a 10× size reduction, and a 70% latency improvement while boosting query rephrasal accuracy by 3.7% and cutting its latency by 40% through structured human feedback collected over three months.
Key Contributions
- This work introduces a MAPE-driven data flywheel framework that operationalizes a closed-loop system for continuous learning in enterprise AI agents. The architecture systematically routes user feedback into the optimization pipeline to enable incremental system evolution.
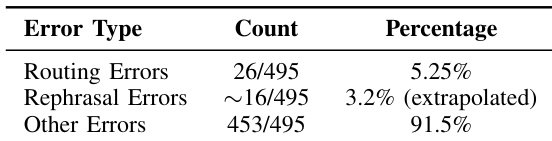
- An empirical analysis of 495 post-deployment feedback samples identifies routing errors (5.25%) and query rephrasing inaccuracies (3.2%) as the primary failure modes. These findings establish a data-driven baseline for prioritizing targeted component optimizations.
- A modular implementation blueprint leveraging NVIDIA NeMo microservices executes parameter-efficient fine-tuning to resolve the identified pipeline failures. Targeted optimizations replace a Llama 3.1 70B model with an 8B variant to achieve 96% routing accuracy with a 10× size reduction and 70% latency decrease, while query rephrasing accuracy improves by 3.7% with a 40% latency reduction.
Introduction
The authors address the critical need for enterprise AI agents to maintain accuracy and efficiency as user intent and domain data evolve post-deployment. Existing production systems typically rely on static architectures that isolate feedback from model improvement, leading to performance degradation and high latency without enabling cost-effective continuous learning. The authors introduce a MAPE-driven data flywheel framework that operationalizes a closed-loop pipeline within NVIDIA's NVInfo AI assistant to systematically identify failure modes and apply targeted parameter-efficient fine-tuning. By integrating human feedback with automated monitoring and execution, this approach allows the system to self-correct routing and query rephrasing errors, delivering a scalable blueprint for building robust, adaptive agents that improve incrementally based on real-world usage.
Dataset
-
Dataset Composition and Sources: The authors build the training corpus by combining production user feedback, subject matter expert corrections, and internal enterprise documentation. Primary sources include a thumbs-down feedback loop, SharePoint expert system logs, and corporate knowledge bases covering benefits, IT policies, and organizational information.
-
Subset Details:
- Routing Error Remediation: The final collection contains 685 deduplicated samples derived from 729 original entries and 32 SME-verified corrections. An LLM-as-a-Judge pipeline initially flagged 140 potential issues, which were manually validated down to 32 high-confidence errors.
- Rephrasal Error Remediation: This subset comprises 5,000 synthetic samples generated from 250 manually reviewed feedback instances. The authors distilled 10 problematic queries down to 4 representative few-shot examples, which guided the synthetic expansion process.
- Regression Evaluation Set: A curated collection of approximately 300 queries spanning corporate policies, benefits, holidays, and IT support. Each entry includes ground truth answers and expected citation metadata.
-
Data Usage and Splits: The routing dataset is allocated using a 60/40 train/test split, while the rephrasal dataset follows an 80/10/10 train/validation/test split. The regression set remains held out for periodic LLM-as-a-Judge evaluation focusing on correctness, helpfulness, and conscientiousness. The authors leverage these subsets to fine-tune routing logic and query rephrasing capabilities within their enterprise agent.
-
Processing and Metadata Construction: Data cleaning and normalization are handled by NeMo Curator, with strict PII removal and GDPR/CCPA compliance applied to all query-response pairs. The synthetic generation pipeline uses Llama 3.1 405B as a generator, injecting SharePoint document context and a structured prompt template to produce aligned question, answer, and rephrased query pairs. The final output format includes structured metadata fields such as Thought, Process, Action, and Action Input to guide downstream tool-use fine-tuning.
Method
The authors leverage a modular, Mixture of Experts (MoE) architecture as the foundation for the NVInfo AI system, which serves as NVIDIA's internal enterprise chatbot. This architecture is designed to handle diverse enterprise information requests by routing user queries to specialized expert models. The core of the system is a router module that employs a large language model (Llama 3.1 70B) to classify incoming user queries and direct them to one of seven domain-specific experts: Financial Info, IT Help & HR Benefits, SharePoint, Holidays, Cafe Menu, People, or NVIDIA Policies. This modular design enables task-specific alignment and enhances efficiency by offloading complex queries to the most appropriate model. The query processing pipeline, which operates after routing, includes several critical stages: conversation rephrasing to incorporate context from prior turns, generating multiple query variations to improve retrieval coverage, a semantic retriever that searches across document collections, re-ranking and de-duplication to prioritize relevant results, answer generation, citation generation for source verification, and suggested follow-up question generation to enhance user interaction.
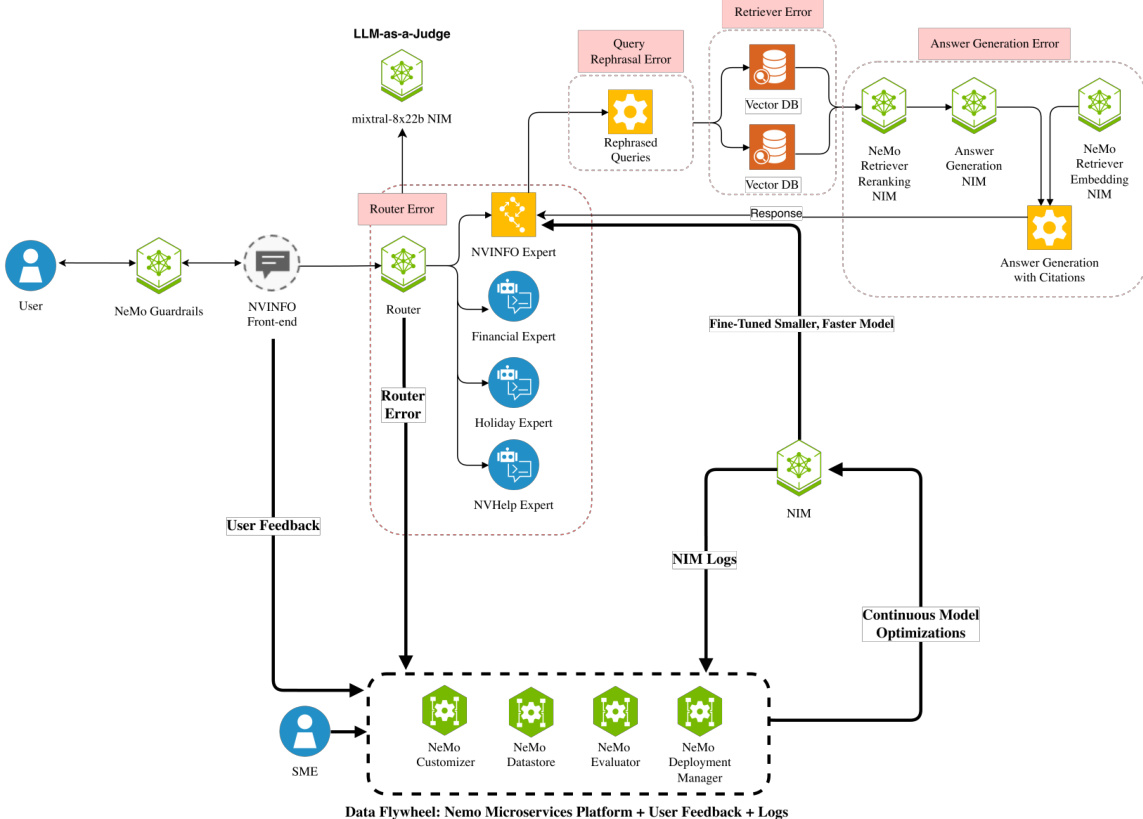
The system's continuous improvement is governed by an Adaptive Data Flywheel, which implements the MAPE-K control loop (Monitor, Analyze, Plan, Execute) to create a self-improving feedback cycle. The monitoring phase collects both direct user feedback, such as thumbs up/down ratings, and implicit signals like re-queries and session abandonment to identify system failures. This data is then fed into the analysis phase, where systematic error attribution techniques, combining manual analysis with automated classification, are used to pinpoint the root cause of failures within the pipeline, such as routing errors or query rephrasing mistakes. The planning phase leverages NVIDIA's NeMo microservices to develop targeted data curation and fine-tuning strategies. Specifically, the authors employ Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning of the router and query rephrasal components using curated failure samples, enabling significant model size reduction and latency improvements without sacrificing accuracy. The execution phase involves deploying these fine-tuned models back into the system, completing the flywheel cycle and enabling continuous optimization.
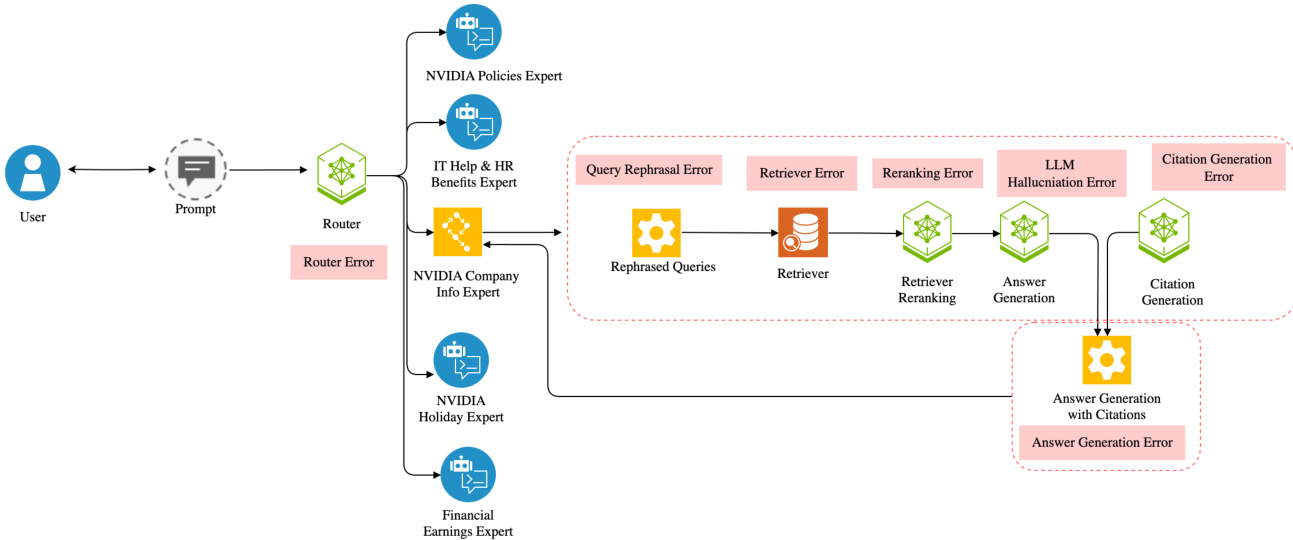
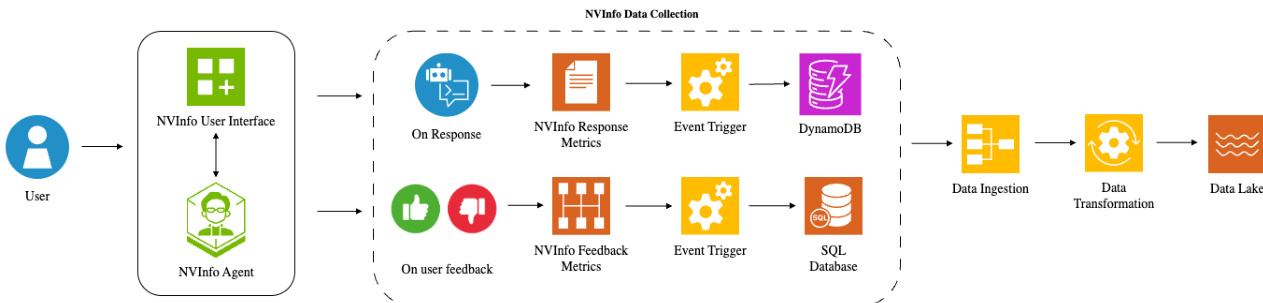
The data collection process is a critical component of this architecture, capturing both response metrics and user feedback through a unified pipeline. Response metrics, including the original query, generated response, expert selection, and system latency, are stored in a DynamoDB database for observability. User feedback, recorded as thumbs up/down with optional contextual reasons, is stored in a SQL database. These two data streams are ingested into a central Data Lake via a data transformation pipeline, which standardizes the schema and enables comprehensive analysis. This collected data is then used to train the LLM-as-a-Judge model, which is employed to classify and validate routing errors, as seen in the provided prompt example. The system's ability to collect, analyze, and act on this data forms the basis of its adaptive capabilities, allowing it to identify and correct failure modes such as incorrect expert routing, query rephrasing errors, and hallucinations, thereby improving the overall reliability and performance of the enterprise AI system.
Experiment
Evaluated on NVIDIA’s NVInfo bot using production user feedback, the router and rephrasal experiments validated that fine-tuning smaller models can match larger baselines in accuracy while drastically improving response times. Qualitative analysis of user interactions further demonstrated that a continuous data flywheel effectively corrects routing and query expansion failures without requiring extensive retraining. The deployment process highlighted that staged rollouts, robust monitoring, and cross-team coordination are critical for maintaining system stability at scale. Ultimately, the findings confirm that adaptive, feedback-driven AI agents can continuously evolve to deliver reliable enterprise solutions while significantly reducing computational overhead.
The authors compare a fine-tuned Llama 3.1 8B model against a baseline Llama 3.1 70B model for query rephrasal, showing improved accuracy and reduced latency. The results demonstrate that a smaller model can achieve better performance than the larger baseline in this specific task. The fine-tuned Llama 3.1 8B model achieved higher accuracy than the Llama 3.1 70B baseline model. The fine-tuned Llama 3.1 8B model showed reduced latency compared to the Llama 3.1 70B baseline model. A smaller model achieved better performance than the larger baseline model in the query rephrasal task.

The authors analyze user feedback to identify system errors and improve model performance. Results show that routing and rephrasal errors constitute a small fraction of total failures, indicating that targeted refinement of these areas can lead to significant improvements in system accuracy and efficiency. Routing and rephrasal errors combined make up a small percentage of total system failures. The majority of errors are categorized as other, suggesting that non-routing and non-rephrasal issues dominate system failures. The analysis supports focused improvements on routing and rephrasal to enhance overall system performance.
{"summary": "The authors evaluate a data flywheel system for an enterprise AI assistant, focusing on model optimization and error correction through user feedback. Results show significant improvements in model efficiency and accuracy while maintaining high performance across different domains.", "highlights": ["Model size was reduced by 10 times while maintaining high routing accuracy and reducing latency significantly.", "Query rephrasal accuracy improved with a notable reduction in latency, enhancing user experience.", "Analysis of user feedback revealed that routing and rephrasal errors combined made up a small fraction of total failures, indicating targeted improvements were effective."]

The authors evaluate the performance of various fine-tuned models compared to a baseline Llama 3.1 70B model, focusing on accuracy and latency improvements. Results show that smaller models achieve comparable or near-comparable accuracy with significantly reduced latency, demonstrating the effectiveness of fine-tuning for efficiency gains. The experiments highlight a trade-off between model size and performance, with fine-tuned smaller models achieving high accuracy and much lower latency than the large baseline. Smaller fine-tuned models achieve comparable accuracy to the large baseline model while significantly reducing latency. Fine-tuning enables substantial performance improvements in accuracy and speed for smaller models compared to no-tuning. The results demonstrate that optimized smaller models can outperform larger models in terms of efficiency without sacrificing accuracy.

The experiments compare fine-tuned smaller language models against a larger baseline for query rephrasal and routing tasks, while also analyzing user feedback to categorize system errors. These evaluations validate that targeted optimization allows smaller architectures to match or exceed baseline accuracy while substantially improving response speed. Additionally, the error analysis confirms that routing and rephrasal failures represent only a minor portion of total system issues, demonstrating that focused refinements effectively enhance overall reliability. Collectively, the findings establish that efficient model scaling through fine-tuning successfully balances performance with computational demands.