Command Palette
Search for a command to run...
بناء وكيل لعبة الشطرنج باستخدام التعلم العميق Q
الملخص
Please provide the title and abstract you would like me to translate.
One-sentence Summary
The authors propose AOAD-MAT, a Transformer-based actor-critic architecture that explicitly incorporates agent decision ordering through a next-agent prediction subtask integrated into a Proximal Policy Optimization loss, demonstrating superior performance on the StarCraft Multi-Agent Challenge and Multi-Agent MuJoCo benchmarks.
Key Contributions
- Introduces AOAD-MAT, a Transformer-based multi-agent reinforcement learning architecture that explicitly learns and optimizes the sequence of agent actions during cooperative training.
- Integrates a next-agent prediction subtask into a Proximal Policy Optimization loss function to dynamically adjust action sequences and synergistically maximize the advantage function.
- Validates the framework through extensive experiments on the StarCraft Multi-Agent Challenge and Multi-Agent MuJoCo benchmarks, demonstrating consistent performance improvements over existing baselines.
Introduction
Multi-agent reinforcement learning (MARL) has become essential for coordinating complex cooperative systems like autonomous robotics and smart traffic networks, yet it struggles with environmental non-stationarity and rapidly expanding joint action spaces. Recent Transformer-based frameworks like MAT and ACE have advanced the field by treating agent coordination as a sequential generation task, but they fail to account for a critical operational factor: the actual sequence in which agents execute their decisions. Action ordering heavily influences both team stability and overall reward, particularly when agents possess asymmetric capabilities or operate under dynamic environmental constraints. To bridge this gap, the authors propose AOAD-MAT, a novel architecture that explicitly learns and optimizes the optimal action execution order. They accomplish this by integrating a dedicated next-agent prediction subtask into a Proximal Policy Optimization loss function, enabling the model to dynamically adjust decision sequences while synergistically maximizing cooperative advantage. Comprehensive evaluations on standard benchmarks demonstrate that this order-aware approach consistently surpasses existing MARL baselines.
Method
The authors leverage the centralized training with centralized execution (CTCE) framework to address scalability and coordination challenges in cooperative multi-agent reinforcement learning (MARL). This framework reinterprets multi-agent decision-making as a sequence modeling problem, enabling the use of Transformer-based architectures. The core of the proposed AOAD-MAT model is a dual-stream architecture that integrates both policy and value functions within a unified Transformer framework. The architecture consists of an encoder and a decoder, as shown in the framework diagram. The encoder, which acts as the critic network, processes the joint observations of all agents to produce a set of latent representations. These representations are then fed into the decoder, which functions as the actor network and generates actions for agents in an autoregressive manner.
The key innovation lies in the explicit modeling of the sequential decision-making process. The model predicts the order in which agents will act, treating this prediction as a discrete output. This action decision order prediction is integrated directly into the learning process. The decoder, which is responsible for generating actions, is augmented with a subtask that predicts the next agent to act. This prediction is made based on the current state of the system and the history of actions taken. The predicted agent order is then used to reorder the latent representations of the observations, ensuring that the decoder attends to the relevant information in the correct sequence. This reordering is achieved by applying a permutation function to the encoder's output, which aligns the observations with the predicted action sequence.
The model's learning process is guided by the Multi-Agent Advantage Decomposition Theorem, which provides a principled way to decompose the joint advantage signal into individual contributions from each agent. This decomposition allows the model to assign credit accurately and update policies in a way that reflects the sequential nature of the decision-making process. The advantage function is calculated incrementally, where the advantage of an agent's action depends on the actions of all preceding agents. This mechanism ensures that the policy updates are consistent with the predicted action order, leading to more stable and efficient learning. The framework diagram illustrates how the model predicts the next agent to act and generates the corresponding action, with the latent representations being dynamically reordered to reflect the evolving action sequence.
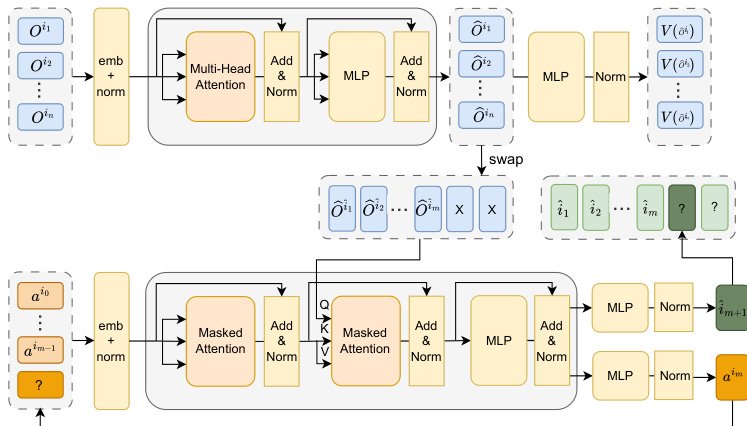
Experiment
The evaluation compares the proposed AOAD-MAT model against traditional and adjusted baselines across discrete StarCraft II and continuous MuJoCo multi-agent environments to assess learning stability and exploration efficiency. Results demonstrate that AOAD-MAT consistently achieves superior performance by dynamically optimizing agent action ordering, which proves more effective than fixed sequences, random shuffling, or simple hyperparameter adjustments. The adaptive ordering mechanism facilitates more flexible advantage assessment and efficient exploration, with performance gains directly linked to the convergence of order prediction entropy. Ultimately, the experiments validate that integrating synergistic loss functions and strategic lead agent selection further enhances cooperative learning, confirming the model's robustness in complex multi-agent scenarios.
{"summary": "The authors compare the proposed AOAD-MAT model with baseline methods on SMAC and MA-MuJoCo tasks, focusing on performance differences in top percentiles of training steps. Results show that AOAD-MAT consistently outperforms baselines across tasks, particularly in heterogeneous scenarios, indicating that its action-order-aware design leads to more stable and effective policy updates.", "highlights": ["AOAD-MAT achieves higher performance than baselines across all SMAC tasks, especially in heterogeneous scenarios like MMM2.", "The proposed model shows improved learning stability and peak performance in continuous control tasks, as demonstrated by higher rewards and confidence intervals in MA-MuJoCo.", "AOAD-MAT's adaptive action ordering strategy contributes to better policy updates, with performance gains becoming more apparent after extended training periods."]
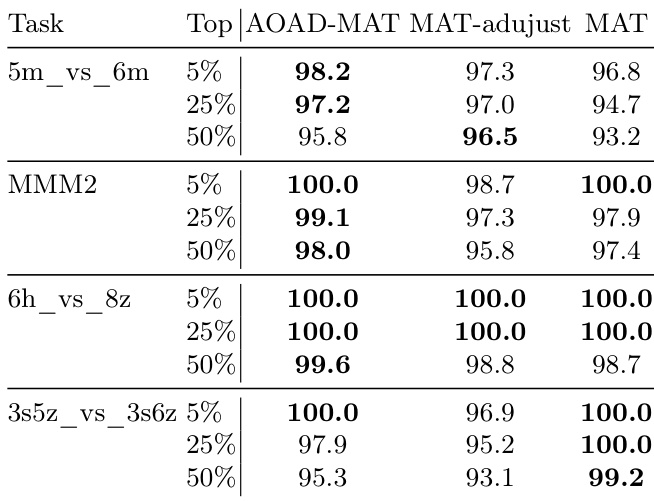
The authors evaluate the proposed AOAD-MAT model against baseline methods on SMAC and MA-MuJoCo benchmarks, focusing on performance in challenging multi-agent scenarios. Results show that AOAD-MAT achieves high win rates and reward improvements, with consistent outperformance across tasks, particularly in heterogeneous and complex environments, suggesting that its action-order-aware design enhances policy stability and exploration. AOAD-MAT achieves the highest performance across all SMAC and MA-MuJoCo tasks, outperforming baselines in both win rates and rewards. The proposed method demonstrates improved learning stability and peak performance, particularly in later training stages, due to its adaptive action ordering strategy. AOAD-MAT's action-order-aware design provides benefits beyond PPO clip adjustments, especially in complex heterogeneous tasks where fixed or random ordering strategies are less effective.

The authors compare the proposed AOAD-MAT model with baseline methods on SMAC and MA-MuJoCo environments, focusing on performance in terms of win rates and average rewards. Results show that AOAD-MAT achieves higher median win rates and more stable learning across all tasks, particularly excelling in complex heterogeneous scenarios and continuous control environments. The adaptive action ordering strategy contributes to improved policy updates and exploration efficiency, leading to superior performance after extended training. AOAD-MAT consistently achieves higher median win rates across all SMAC tasks compared to baseline methods, particularly in complex heterogeneous scenarios. AOAD-MAT demonstrates more stable learning and higher peak performance in MA-MuJoCo, with a significant improvement in median rewards and tighter confidence intervals. The adaptive action ordering strategy in AOAD-MAT leads to better exploration and policy stability, especially in later stages of training, indicating its effectiveness beyond simple training duration.
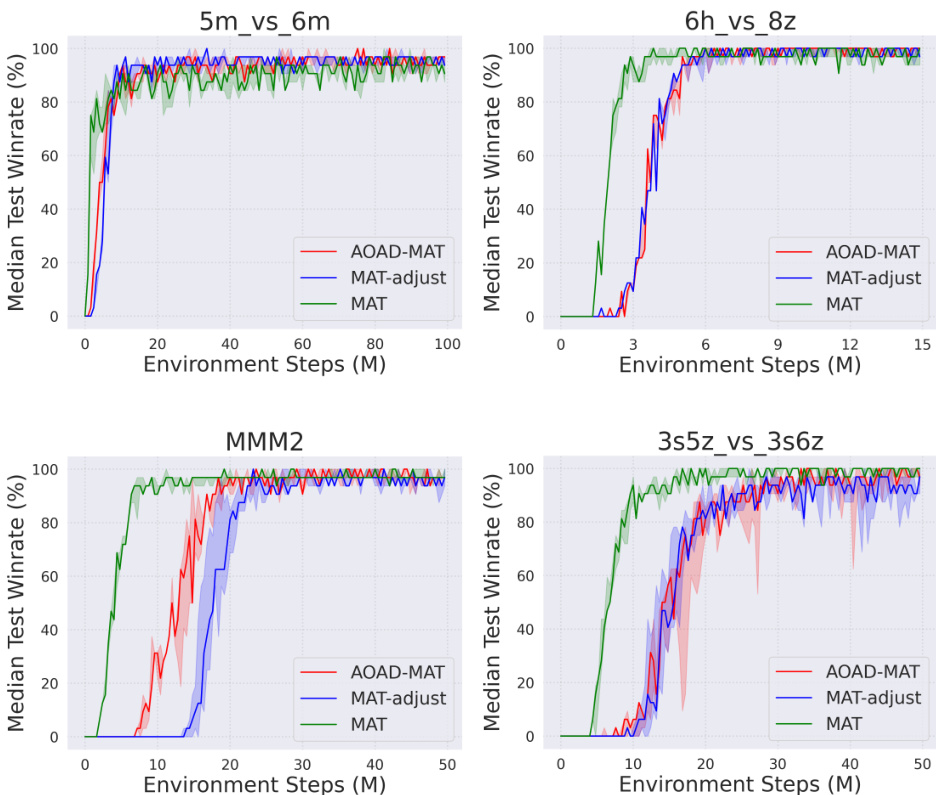
The authors evaluate the proposed AOAD-MAT model against baseline methods on the SMAC and MA-MuJoCo benchmarks to validate its effectiveness in multi-agent combat and continuous control environments. Experimental results demonstrate that the model consistently outperforms existing approaches, particularly in complex and heterogeneous scenarios, by delivering more stable learning trajectories and higher peak performance. These qualitative improvements are driven by its adaptive action ordering strategy, which enhances exploration efficiency and policy update stability, especially during extended training phases. Overall, the findings confirm that the action-order-aware design provides substantial advantages over fixed or random ordering mechanisms in dynamic multi-agent settings.