Command Palette
Search for a command to run...
تقييم وتعزيز متانة ختم الماء النصي لـ SynthID الخاص بشركة جوجل
تقييم وتعزيز متانة ختم الماء النصي لـ SynthID الخاص بشركة جوجل
Xia Han Qi Li Jianbing Ni Mohammad Zulkernine
نشر أداة ختم الذكاء الاصطناعي SynthID-Text بنقرة واحدة
الملخص
تقدم التطورات الحديثة في طرق وضع العلامات المائية للنماذج اللغوية الكبيرة، مثل SynthID-Text من Google DeepMind، حلولاً واعدة لتتبع أصل النصوص المولَّدة بواسطة الذكاء الاصطناعي. ومع ذلك، تكشف تقييماتنا للمتانة أن SynthID-Text عرضة لهجمات تحافظ على المعنى، مثل إعادة الصياغة، وتعديلات النسخ واللصق، والترجمة العكسية، والتي يمكن أن تقلل بشكل كبير من قابلية اكتشاف العلامة المائية. لمعالجة هذه القيود، نقترح SynGuard، وهو إطار عمل هجين يجمع بين قوة المحاذاة الدلالية لـ Semantic Invariant Robust (SIR) مع آلية وضع العلامات المائية الاحتمالية لـ SynthID-Text. يدمج نهجنا العلامات المائية بشكل مشترك على المستويين المعجمي والدلالي، مما يتيح تتبعاً متيناً للأصل مع الحفاظ على المعنى الأصلي. تُظهر النتائج التجريبية عبر سيناريوهات هجوم متعددة أن SynGuard يحسّن استعادة العلامة المائية بنسبة متوسطة تبلغ 11.1% في درجة F1 مقارنة بـ SynthID-Text. توضح هذه النتائج فعالية وضع العلامات المائية الواعي بالدلالة في مقاومة التلاعب الواقعي.
One-sentence Summary
The authors propose SynGuard, a hybrid framework that enhances Google’s SynthID-Text by integrating the semantic alignment of Semantic Invariant Robust (SIR) with probabilistic watermarking to embed markers across lexical and semantic levels, thereby improving watermark recovery by an average of 11.1% in F1 score compared to SynthID-Text under meaning-preserving attacks.
Key Contributions
- This work introduces SynGuard, a hybrid watermarking framework that enhances the robustness of LLM text provenance tracking against meaning-preserving adversarial edits.
- The method jointly embeds detection signals at lexical and semantic levels during token generation by integrating probabilistic logit modification with semantic alignment to preserve watermark detectability.
- Experimental evaluations across multiple attack scenarios demonstrate that SynGuard improves watermark recovery by an average of 11.1% in F1 score relative to SynthID-Text and identifies a previously unexamined correlation between back-translation vulnerability and machine translation quality.
Introduction
Text watermarking offers a lightweight mechanism for verifying the provenance of AI-generated content, which is essential for accountability in open-world environments where black-box models are prevalent. Generation-based methods such as Google's SynthID-Text have advanced this field by embedding imperceptible statistical signals during token sampling, yet they remain fragile against meaning-preserving transformations. Prior work struggles to balance robustness with efficiency, as lexical-only approaches degrade significantly under paraphrasing or back-translation, while purely semantic techniques often introduce high computational overhead or reduce output diversity. To resolve these limitations, the authors propose SynGuard, a hybrid framework that combines the semantic alignment capabilities of Semantic Invariant Robust (SIR) with SynthID's probabilistic token masking. By embedding provenance signals at both lexical and semantic levels, the authors enable robust detection of surface-altering attacks while preserving the randomness needed to resist keyless removal, achieving an average 11.1% improvement in F1 score across multiple attack scenarios.
Method
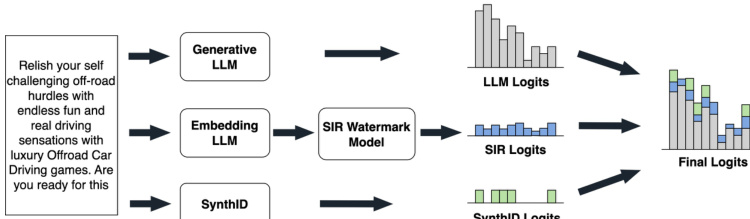
The authors leverage a hybrid watermarking framework, SynGuard, which integrates the strengths of both semantic-aware and pseudorandom watermarking approaches to enhance robustness against semantic-preserving transformations. The core design combines the SynthID-Text sampling mechanism with the Semantic Invariant Robust (SIR) algorithm. During watermark embedding, the process involves generating three distinct sets of logits at each token generation step: the base logits from the backbone language model (LLM), the SIR logits derived from a semantic watermarking model conditioned on the preceding text to encode semantic consistency, and the SynthID logits computed using a pseudorandom mechanism based on hash values of tokens, a secret key, and a random seed. These three components are linearly combined with a semantic weight δ to produce the final logits vector, which is then passed through a softmax function to yield the probability distribution over the vocabulary. This composite approach ensures that the watermark signal is embedded in both the semantic structure and the token-level randomness.
Watermark extraction in SynGuard is performed by computing a composite score s that evaluates both the semantic similarity of the text to its context and the statistical watermark signal. The score is a weighted sum of two components: a normalized semantic similarity score ssemantic, which measures how well each token aligns with the preceding context according to the SIR model, and a g-value score sg-value, which quantifies the average output of the SynthID-Text watermarking functions across all tokens. The overall score s is computed as s=δ⋅2ssemantic+1+(1−δ)⋅sg-value, where δ is a hyperparameter controlling the relative importance of semantic alignment versus the pseudorandom watermark signal. This design ensures that the detection score remains robust even when the text undergoes transformations that preserve meaning, as the semantic component remains high while the g-value component is resilient to removal attempts. The framework's robustness is further supported by theoretical analysis, which demonstrates that the detection score for a genuine watermarked text remains above a threshold, while the probability of a non-watermarked text falsely exceeding this threshold decays exponentially with text length.
Experiment
The experiments evaluate the robustness of the SynthID-Text watermarking algorithm and the proposed SynGuard method against four distinct text manipulation attacks using a standardized language model and dataset. Each scenario validates detector resilience to specific tampering strategies, ranging from minor lexical substitutions and content dilution to complex structural paraphrasing and cross-lingual re-translation. Qualitatively, the baseline method remains effective against simple lexical changes but suffers significant performance degradation when faced with semantic-preserving transformations that alter text structure or context. Conversely, SynGuard consistently outperforms the baseline across all attack vectors by effectively integrating semantic alignment with probabilistic sampling, ultimately establishing a more resilient watermarking framework that preserves both detection accuracy and text fluency.
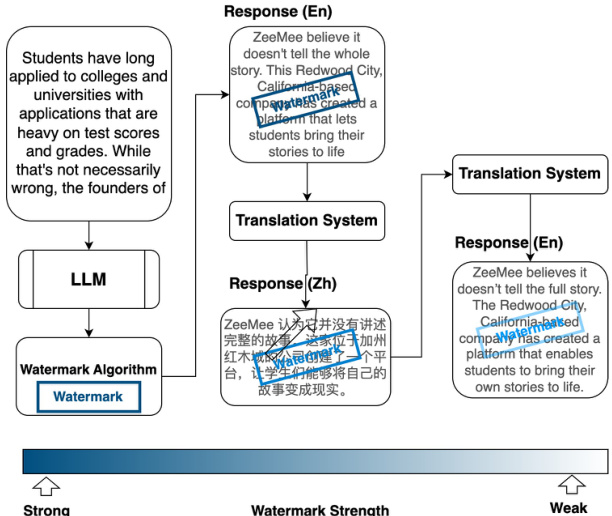
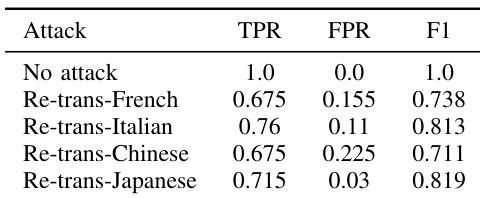
The authors evaluate the robustness of SynthID-Text and SynGuard under various text editing attacks, including re-translation using different pivot languages. Results show that SynthID-Text's detection performance degrades significantly under re-translation, particularly when using Chinese as the pivot language, while SynGuard maintains higher detection accuracy across all attacks. The choice of pivot language influences the effectiveness of re-translation attacks, with Japanese yielding the highest detection performance and Chinese the lowest. SynthID-Text's detection accuracy drops significantly under re-translation attacks, especially when using Chinese as the pivot language. SynGuard outperforms SynthID-Text in detection accuracy across all re-translation attack scenarios, demonstrating improved robustness. The choice of pivot language affects re-translation attack effectiveness, with Japanese resulting in higher detection accuracy than Chinese and other languages.
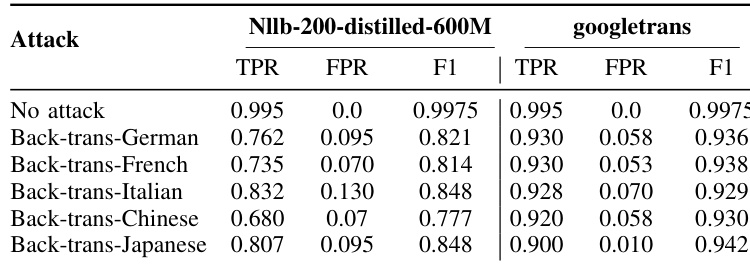
The authors evaluate the robustness of SynGuard against back-translation attacks using two translation tools, NLLB-200-distilled-600M and Google Translate. Results show that SynGuard maintains high detection accuracy across different pivot languages, with the highest F1 score achieved when using Google Translate with Japanese as the pivot language. The performance varies depending on the translation tool and the pivot language, with NLLB-200-distilled-600M generally yielding lower F1 scores compared to Google Translate. SynGuard achieves high F1 scores across all back-translation attacks, with the best performance observed when using Google Translate and Japanese as the pivot language. The choice of translation tool significantly affects detection accuracy, with Google Translate consistently outperforming NLLB-200-distilled-600M in all tested scenarios. SynGuard maintains strong detection performance even with challenging pivot languages like Chinese, indicating resilience against severe semantic-preserving transformations.
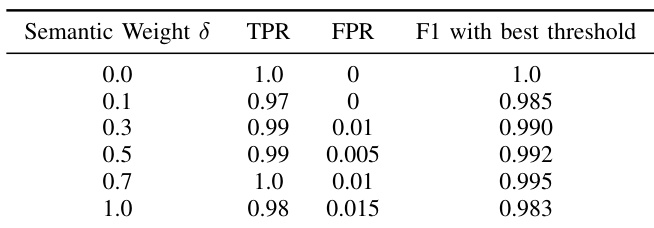
The authors investigate the impact of the semantic weight parameter on the watermarking algorithm's performance, using metrics such as True Positive Rate, False Positive Rate, and F1 score. Results show that increasing the semantic weight leads to improvements in detection performance, with the highest F1 score achieved at a weight of 0.7, despite a slight increase in false positives. The optimal setting of 0.7 is selected for subsequent evaluations due to its strong balance between detection accuracy and false positive rate. Increasing the semantic weight improves detection performance, with the highest F1 score achieved at 0.7. The False Positive Rate increases slightly with higher semantic weight but remains low across all settings. The optimal semantic weight of 0.7 is chosen for subsequent evaluations due to its strong balance between accuracy and false positives.
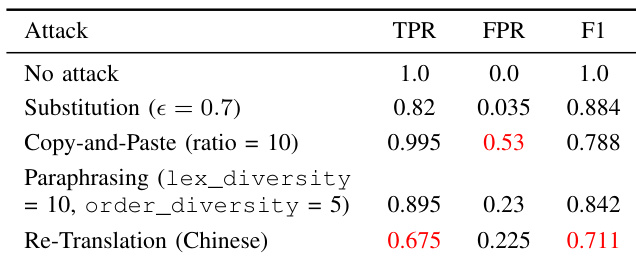
The the the table presents detection performance metrics for SynthID-Text under various attack scenarios, showing a significant decline in F1 score and TPR across different attack types. The performance degradation is most severe under re-translation attacks, where the F1 score drops substantially and the TPR falls to a low level. The copy-and-paste attack with a high ratio results in a notably high false positive rate, while synonym substitution and paraphrasing attacks also reduce detection accuracy, though to a lesser extent. F1 score drops significantly under re-translation attacks, indicating severe vulnerability to semantic-preserving transformations. Copy-and-paste attacks with a high ratio lead to a high false positive rate, compromising detection reliability. Performance degrades under paraphrasing attacks, with notable reductions in both TPR and F1 score.
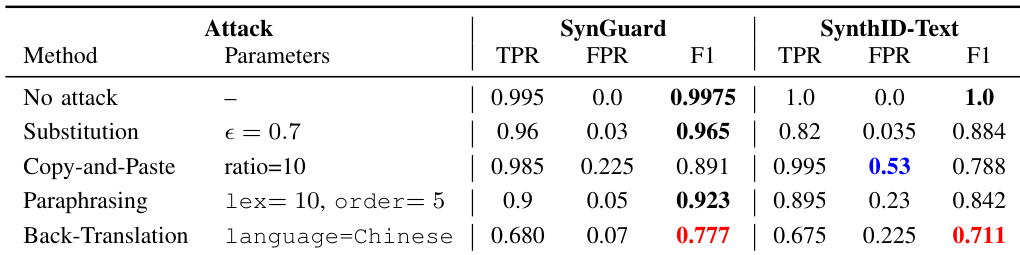
The the the table compares the performance of SynGuard and SynthID-Text under various attack scenarios, including no attack, synonym substitution, copy-and-paste, paraphrasing, and back-translation. SynGuard achieves higher F1 scores than SynthID-Text across all attack types, particularly under back-translation, where it maintains significantly better detection accuracy. SynthID-Text shows strong performance under no attack but degrades notably under complex semantic-preserving attacks, especially when the copy-and-paste ratio is high or the back-translation uses Chinese. SynGuard outperforms SynthID-Text in detection accuracy across all attack types, especially under back-translation and paraphrasing. SynthID-Text's performance degrades significantly under copy-and-paste attacks, with a high false positive rate and low F1 score. SynGuard maintains robust detection under back-translation, achieving a higher F1 score compared to SynthID-Text, which shows substantial performance drop.
The experiments evaluate the robustness of SynthID-Text and SynGuard against various text editing and back-translation attacks while also assessing the impact of a semantic weight parameter on detection performance. Qualitative analysis reveals that SynGuard consistently maintains high detection accuracy across all adversarial scenarios, whereas SynthID-Text suffers significant degradation, particularly under re-translation and high-ratio copy-paste operations. The effectiveness of these attacks is notably influenced by the choice of pivot language and translation model, with Japanese and Google Translate yielding the most favorable detection outcomes. Ultimately, SynGuard demonstrates superior resilience to semantic-preserving transformations, establishing it as a more reliable watermarking solution under complex editing conditions.