Command Palette
Search for a command to run...
تيسيرا: التضمينات الزمنية للأطياف السطحية لتمثيل وتحليل الأرض
تيسيرا: التضمينات الزمنية للأطياف السطحية لتمثيل وتحليل الأرض
الملخص
غالبًا ما تتسم سلاسل الزمن الخاصة بملاحظات الأرض من الأقمار الصناعية في النطاقين الضوئي والميكروي من الطيف الكهرومغناطيسي بعدم الانتظام، وذلك بسبب أنماط المدارات والعوائق الناتجة عن الغيوم. وتعمل تقنيات التجميع (Compositing) على معالجة هذه المشكلات، لكنها تؤدي إلى فقدان معلومات تتعلق بدورة حياة النباتات (Vegetation phenology)، وهي عنصر حاسم للعديد من المهام اللاحقة. وبدلاً من ذلك، نقدم نموذج التأسيس TESSERA، وهو نموذج أساسي يعمل على مستوى كل بكسل (Pixel-wise) وسلاسل الزمن للملاحظات الأرضية متعددة الوسائط (Sentinel-1/2)، ويقوم بتعلم تضمينات (Embeddings) قوية وفعالة من حيث استخدام التسميات (Label-efficient).أثناء تدريب النموذج، يستخدم TESSERA أسلوب Barlow Twins مع أخذ العينات العشوائية الزمنية المتفرقة (Sparse random temporal sampling) لفرض الثبات تجاه اختيار المشاهدات الصالحة. كما نعتمد منتظمين رئيسيين: الخلط العالمي (Global shuffling) لفك ارتباط الجوار المكاني، والتنظيم القائم على الخلط (Mix-based regulation) لتعزيز الثبات تحت حالات التفرق الشديد. وقد وجدنا أن تضمينات TESSERA تقدم دقةً من الطراز الأحدث (State-of-the-art) في مهام متنوعة تشمل التصنيف، والتجزئة (Segmentation)، والانحدار (Regression)، وذلك بكفاءة عالية في استخدام التسميات، وغالباً ما يتطلب ذلك رأس مهام (Task head) صغيراً وحسابات ضئيلة.ولتعزيز إتاحة الوصول، والامتثال لمبادئ FAIR (إتاحة البيانات وإمكانية الوصول إليها وقابليتها للتشغيل المتبادل وقابلية إعادة الاستخدام)، وتسهيل الاستخدام، ننشر تضمينات بكسلية سنوية عالمية ودقة 10 أمتار وبصيغة int8، جنباً إلى جنب مع أوزان ومصادر مفتوحة الرأس ومهام تكيف خفيفة الوزن، مما يوفر أدوات عملية للاسترجاع والاستدلال (Inference) على نطاق واسع وبمقياس كوكبي. تتوفر جميع الأكواد والبيانات على الرابط التالي: https://github.com/ucam-eo/tessera.
One-sentence Summary
TESSERA, a pixel-wise foundation model for multi-modal Sentinel-1/2 Earth observation time series, employs Barlow Twins and sparse random temporal sampling to learn robust embeddings that preserve vegetation phenology unlike compositing methods, achieves state-of-the-art accuracy with high label efficiency across classification, segmentation, and regression tasks, and releases global annual 10m pixel-wise int8 embeddings with open weights and code for planetary-scale inference.
Key Contributions
- TESSERA is a pixel-wise foundation model for multi-modal Sentinel-1/2 Earth Observation time series that learns robust embeddings using Barlow Twins and sparse random temporal sampling.
- TESSERA embeddings deliver state-of-the-art accuracy across diverse classification, segmentation, and regression tasks with high label efficiency and minimal computation.
- Global, annual, 10m pixel-wise int8 embeddings are released alongside open weights and the GeoTessera library to enable analysis-ready use without backbone fine-tuning.
Introduction
Satellite Earth-observation time series are frequently irregular due to cloud cover and orbital constraints, yet existing foundation models typically rely on preprocessed composites that discard valuable phenological information. These prior approaches often bias representations toward idealized conditions and require compute-intensive fine-tuning, creating significant barriers for widespread adoption. To address this, the authors present TESSERA, a pixel-wise foundation model for multi-modal Sentinel-1 and 2 data that enforces invariance to temporal sampling variability using Barlow Twins and sparse random sampling. They introduce specific regularizers to handle spatial correlations and sparsity while releasing global, 10m pixel-wise embeddings with open weights to adhere to FAIR principles and enable high accuracy with minimal downstream computation and strong label efficiency.
Dataset
Dataset Composition and Sources
- The authors pre-train the model using approximately 800 million d-pixels drawn from 3,012 globally distributed Military Grid Reference System tiles from 2017 to 2024.
- Imagery is sourced from Sentinel-1 (VV and VH polarizations) and Sentinel-2 (10 spectral bands).
- Evaluation spans six benchmarks including TreeSatAI-TS, PASTIS-R, Biomassters, and Borneo Canopy Height.
- Two new benchmarks were introduced to address data scarcity: Austrian Crop for parcel-level mapping and Borneo Canopy Height for forest structure.
Key Details for Each Subset
- Pre-training data is spatially downsampled by a factor of 400 by systematically taking every 20th pixel.
- The Austrian Crop dataset consolidates 154 crop types into 17 broader classes based on phenological similarity.
- BioMassters includes nearly 11,500 forest patches in Finland with 10 meter resolution and Above-Ground Biomass values derived from LiDAR.
- Downstream tasks are evaluated at 1%, 30%, and 100% label ratios to study label efficiency.
Training Splits and Processing
- Pre-training runs for a single epoch using a global shuffling strategy to prevent geographic bias in training batches.
- Temporal sequences are fixed at 40 timesteps per d-pixel through sparse temporal sampling.
- Replacement sampling is applied if fewer than 40 cloud-free dates are available for a specific location.
- Normalized Day-of-Year values are encoded as sine and cosine features and concatenated with spectral measurements.
- Global statistics are used to standardize values for training stability.
Cropping and Metadata Construction
- Binary masks are generated for each tile to flag cloud cover or missing data at specific spatial coordinates.
- For Austrian Crop segmentation, the region is divided vertically into five parts to extract 1,000 test patches, 1,000 validation patches, and 3,000 training patches.
- Pixel-level classification splits allocate fields by area percentage to ensure all crop classes appear in each split.
- A custom pipeline manages the high I/O demands of shuffling and augmenting over 2 TB of initial d-pixel data.
Method
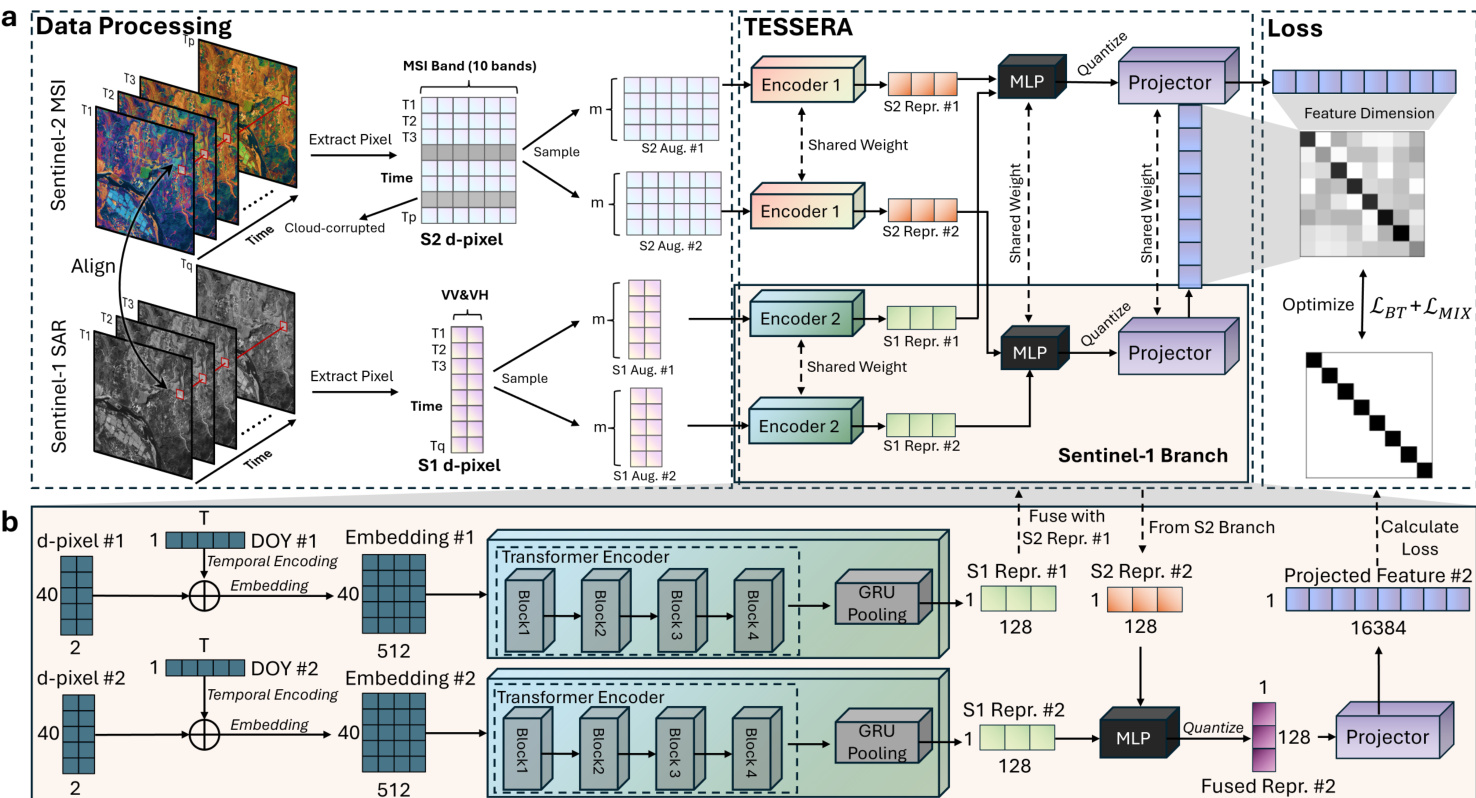
The TESSERA framework employs a dual-branch encoder architecture designed to process optical and radar modalities independently before fusing them into a unified representation. This design allows the model to capture the distinct physical properties of Sentinel-2 multispectral imagery and Sentinel-1 synthetic aperture radar (SAR) data.
Model Architecture
The core of TESSERA consists of two parallel transformer-based encoder branches. Each branch receives a masked time series of observations. Valid observations are first embedded via a linear projection ϕ:RC→Rd. To preserve temporal context, learnable Day-of-Year (DoY) positional encodings ψ(⋅) are added to these embeddings:
et=ϕ(Pi.i(t))+ψ(DoY(t))The resulting sequence is padded to a fixed length of L=40 via sampling with replacement if necessary. This sequence is then processed by a 4-layer Transformer encoder utilizing multi-head self-attention to learn temporal patterns. A GRU-based pooling layer subsequently aggregates the temporal sequence into a fixed-size vector zmod∈R128.
The optical embeddings (zS2) and radar embeddings (zS1) are concatenated and passed through a 2-layer MLP to produce the final fused 128-dimensional embedding z. To optimize storage, Quantization-Aware Training (QAT) is applied to compress z into 8-bit integers, achieving a storage reduction of approximately 4× with negligible performance loss. During the training phase, this fused embedding is expanded to 16,384 dimensions using a deep projector MLP for loss computation, but this projector is discarded during inference.
Refer to the framework diagram below for a detailed overview of the TESSERA processing pipeline, including the data processing, dual-branch encoding, and loss calculation stages.
Pretraining and Training Strategy
TESSERA is pretrained on approximately 800 million d-pixels sampled from 3,012 global MGRS tiles spanning the years 2017 to 2024. The model utilizes a self-supervised learning approach based on the Barlow Twins objective. For each d-pixel, two augmented views (YA, YB) are generated by independently sampling 40 valid time steps from the Sentinel-1 and Sentinel-2 time series.
The network processes these views to produce batch-normalized embeddings ZA and ZB. The standard Barlow Twins loss function LBT minimizes the cross-correlation between redundant dimensions while maximizing the correlation of invariant features:
LBT=i∑(1−Cii)2+λBTi∑j=i∑Cij2Here, C represents the cross-correlation matrix between ZA and ZB. To further enhance robustness and mitigate overfitting, an additional mix-up regularization term LMIX is incorporated. This involves creating mixed views by linearly interpolating between augmented batches and penalizing deviations from the assumption that linear interpolation in input space corresponds to linear interpolation in embedding space.
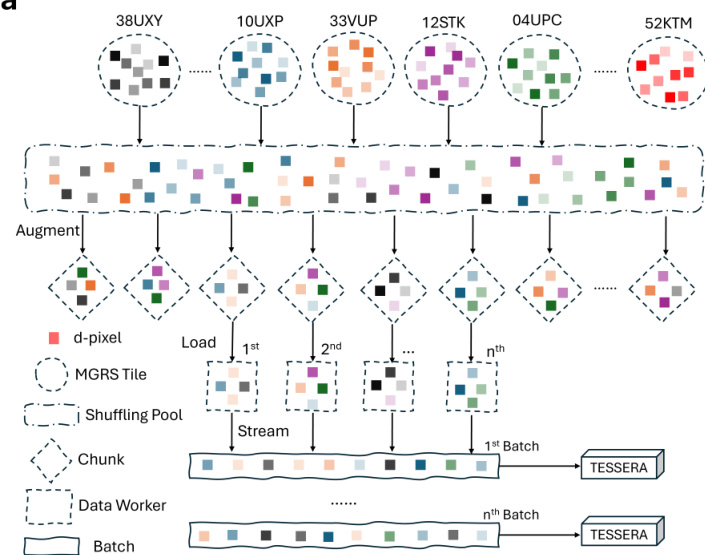
A critical component of the training pipeline is the global shuffling strategy. Before batching, d-pixels from all geographic tiles are randomized globally. This prevents spatial auto-correlation and ensures that the model learns from diverse geographical and environmental conditions within each batch.
As illustrated in the data shuffling schematic, d-pixels from thousands of MGRS tiles are aggregated into a global pool, shuffled, and then streamed into well-diversified training batches.
Inference and Embeddings-as-Data
Following pretraining, the TESSERA dual encoder (with frozen weights) is used to generate annual 128-dimensional embeddings for every 10m pixel globally. This "Embeddings-as-Data" paradigm allows the model to serve as a foundational feature extractor rather than just a task-specific predictor. The primary output is a set of analysis-ready, gap-free embedding maps.
For downstream tasks, users can access these embeddings directly through the GeoTessera Python library. The workflow involves downloading the precomputed embeddings for a region of interest and training a lightweight, task-specific head. For pixel-wise classification or regression, a shallow Multi-Layer Perceptron (MLP) is typically sufficient. For tasks requiring spatial context, such as semantic segmentation, a convolutional architecture like a UNet can process patches of the embeddings.
The overall ecosystem, from data request to downstream model application, is depicted in the figure below, highlighting the separation between the frozen TESSERA embedding generation and the flexible model zoo for various tasks.

Experiment
Experiments evaluated the model across classification, segmentation, and regression tasks on benchmarks including TreeSatAI-TS and Austrian Crop to assess performance under varying data regimes. TESSERA consistently outperforms existing foundation models by leveraging pixel-level temporal modeling to capture phenological variations, demonstrating particular strength in low-label scenarios. Ablation studies confirm the embeddings are robust to cloudiness and geographic shifts, validating that a single global model suffices for diverse regions without regional retraining. Furthermore, the framework adheres to predictable scaling laws and supports efficient quantization, enabling high-resolution global analysis with minimal computational and storage costs.
The authors evaluate the impact of spatial context by comparing their standard pixel-wise model against variants that incorporate fixed spatial patches of varying sizes. The results demonstrate that the current pixel-wise approach generally yields superior classification and regression performance compared to the spatial variants. This finding validates the design choice to maintain pixel-wise independence and avoid embedding fixed spatial priors during pre-training. The baseline pixel-wise model achieves the highest F1 score and lowest regression error among the tested configurations. Introducing larger spatial patches improves segmentation metrics slightly but leads to a significant degradation in regression performance. The intermediate spatial variant with 3x3 patches underperforms the baseline across all reported metrics.

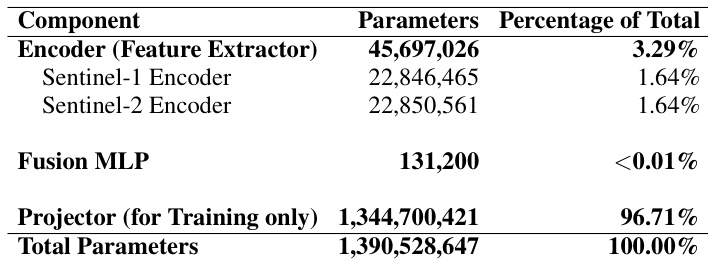
The the the table details the parameter distribution of the model, revealing that the projector network used for training dominates the architecture, comprising the overwhelming majority of parameters. In contrast, the actual feature extraction encoders for the satellite data are highly compact, representing only a small fraction of the total model size. The fusion mechanism connecting the different satellite modalities is extremely lightweight, contributing a negligible amount to the overall parameter count. The training-time projector accounts for the vast majority of the model's total parameters. The feature extraction encoders are highly efficient, making up only a small portion of the total parameters. The fusion MLP is negligible in size, indicating a very lightweight integration of multi-modal data.
The authors evaluate crop classification performance on the Austrian Crop dataset across varying label ratios. TESSERA consistently outperforms baseline models like Presto and AlphaEarth across all supervision levels. The results demonstrate superior robustness in low-data regimes where the proposed model maintains high accuracy while competitors show significantly lower performance. TESSERA achieves the highest performance scores across all tested label ratios. The model exhibits a substantial performance gap over competitors in few-shot learning settings. Accuracy improves steadily with increased supervision, with the proposed method leading at all data levels.

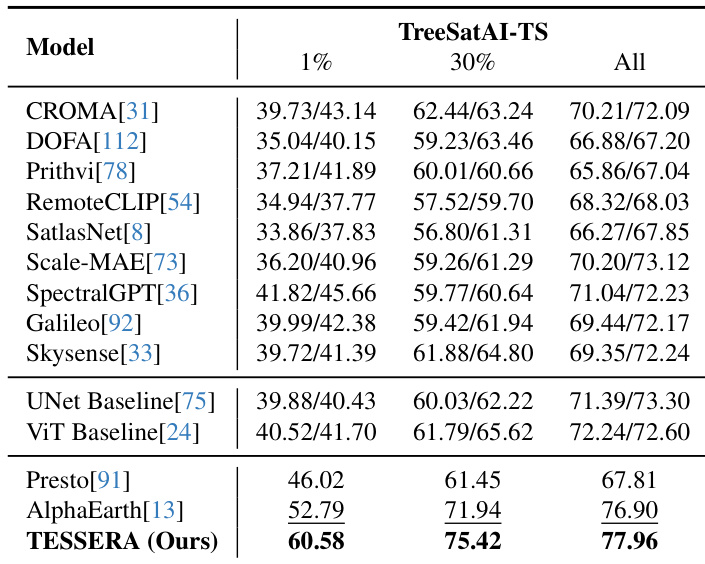
The authors present classification results on the TreeSatAI-TS benchmark, comparing their model against various foundation models and baselines. The results demonstrate that the proposed method consistently achieves the highest performance across all data regimes, from few-shot to full supervision. This indicates superior capability in capturing phenological variations and class separability compared to existing approaches. The model secures the top ranking in the full supervision setting, outperforming the next best competitor. Significant performance gains are observed in the few-shot setting, where the model leads by a large margin over other methods. Consistent outperformance is maintained across the 30% label regime against a wide range of established baselines.
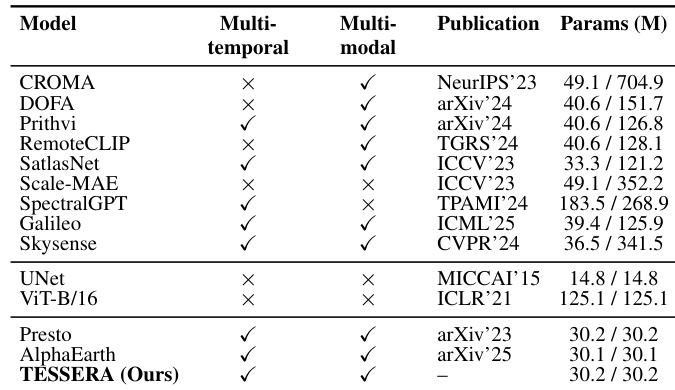
The authors introduce TESSERA as a model capable of processing both multi-temporal and multi-modal data. It features a parameter count comparable to other efficient models like AlphaEarth and Presto, while being significantly smaller than larger architectures such as SpectralGPT. This design allows for efficient processing while maintaining competitive performance across various tasks. TESSERA supports both multi-temporal and multi-modal inputs, unlike several baselines that lack one or both capabilities. The model maintains a compact parameter size similar to AlphaEarth and Presto. It is notably smaller than larger architectures like SpectralGPT and ViT-B/16.
Experiments evaluating spatial context and parameter distribution confirm that the pixel-wise approach and compact encoder design yield superior performance and efficiency. TESSERA consistently outperforms baseline methods on the Austrian Crop and TreeSatAI-TS benchmarks across varying supervision levels, demonstrating particular robustness in low-data regimes. Furthermore, the architecture supports multi-temporal and multi-modal inputs while maintaining a parameter count comparable to efficient existing models.